Pre-scriptum (added on 26 June 2020): The main problem with contemporary physics – all what Paul Ehrenfest referred to as the ‘unendlicher Heisenberg-Born-Dirac-Schrödinger Wurstmachinen-Physik-Betrieb’ – is that it stopped analyzing the physicality of the situation. One should, therefore, probably distinguishing physical from mathematical space. H.A. Lorentz said some useful things about that at the 1927 Solvay Conference. I wrote about that in a more recent paper.
Original post:
The term ‘space’ is all over the place when reading math. There are are all kinds of spaces in mathematics and the terminology is quite confusing. Let’s first start with the definition of a space: a space (in mathematics) is, quite simply, just a set of things (elements or objects) with some kind of structure (and, yes, there is also a definition for the extremely general notion of ‘structure’: a structure on a set consists of ‘additional mathematical objects’ that relate to the set in some manner attach – I am not sure that helps but so there you go).
The elements of the set can be anything. From what I read, I understand that a topological space might be the most general notion of a mathematical space. The Wikipedia article on it defines a topological space as “a set of points, along with a set of neighborhoods for each points, that satisfies a set of axioms relating points and neighborhoods.” It also states that “other spaces, such as manifolds and metric spaces, are (nothing but) specializations of topological spaces with extra structures or constraints.” However, the symbolism involved in explaining the concept is complex and probably prevents me from understanding the finer points. I guess I’d need to study topology for that – but so I am only doing a course in complex analysis right now. 🙂
Let’s go to something something more familiar: the metric spaces. A metric space is a set where a notion of distance (i.e a metric) between elements of the set is defined. That makes sense, doesn’t it?
We have Euclidean and non-Euclidean metric spaces. We all know Euclidean spaces as that is what use for the simple algebra and calculus we all had to learn as a teenager. They can have two, three or more dimensions, but there is only one Euclidean space in any dimension (a line, the plane or, more in general, the Cartesian multidimensional coordinate system). In Euclidean geometry, we have the parallel postulate: within a two-dimensional plane, for any given line L and a point p which is not on that line, there is only one line through that point – the parallel line –which does not intersect with the given line. Euclidean geometry is flat – well… Kind of.
Non-Euclidean metric spaces are a study object in their own but – to put it simply – in non-Euclidean geometry, we do not have the parallel postulate. If we do away with that, then there are two broad possibilities: either we have more than one parallel line or, else, we have none. Let’s start with the latter, i.e. no parallels. The most often quoted example of this is the sphere. A sphere is a two-dimensional surface where lines are actually great circles which divide the sphere in two equal hemispheres, like the equator or the meridians through the poles. They are the shortest path between the two points and so that corresponds to the definition of a line on a sphere indeed. Now, any ‘line’ (any geodesic that is) through a point p off a ‘line’ (geodesic) L will intersect with L, and so there are no parallel lines on a sphere – at least not as per the mathematical definition of a parallel line. Indeed, parallel lines do not intersect. I have to note that it is all a bit confusing because the so-called parallels of latitude on a globe are small circles, not great circles, and, hence, they are not the equivalent of a line in spherical geometry. In short, the parallels of latitude are not parallel lines – in the mathematical sense of the word that is. Does that make sense? For me it makes sense enough, so I guess I should move on.
Other Euclidean geometric facts, such as the angles of a triangle summing up to 180°, cannot be observed on a sphere either: the angles of a triangle on a sphere add up to more than 180° (for the big triangle illustrated below, they add up to 90 + 90 + 50 = 230°). That’s typical of Riemannian or elliptic geometry in general and so, yes, the sphere is an example of Riemannian or elliptic geometry.
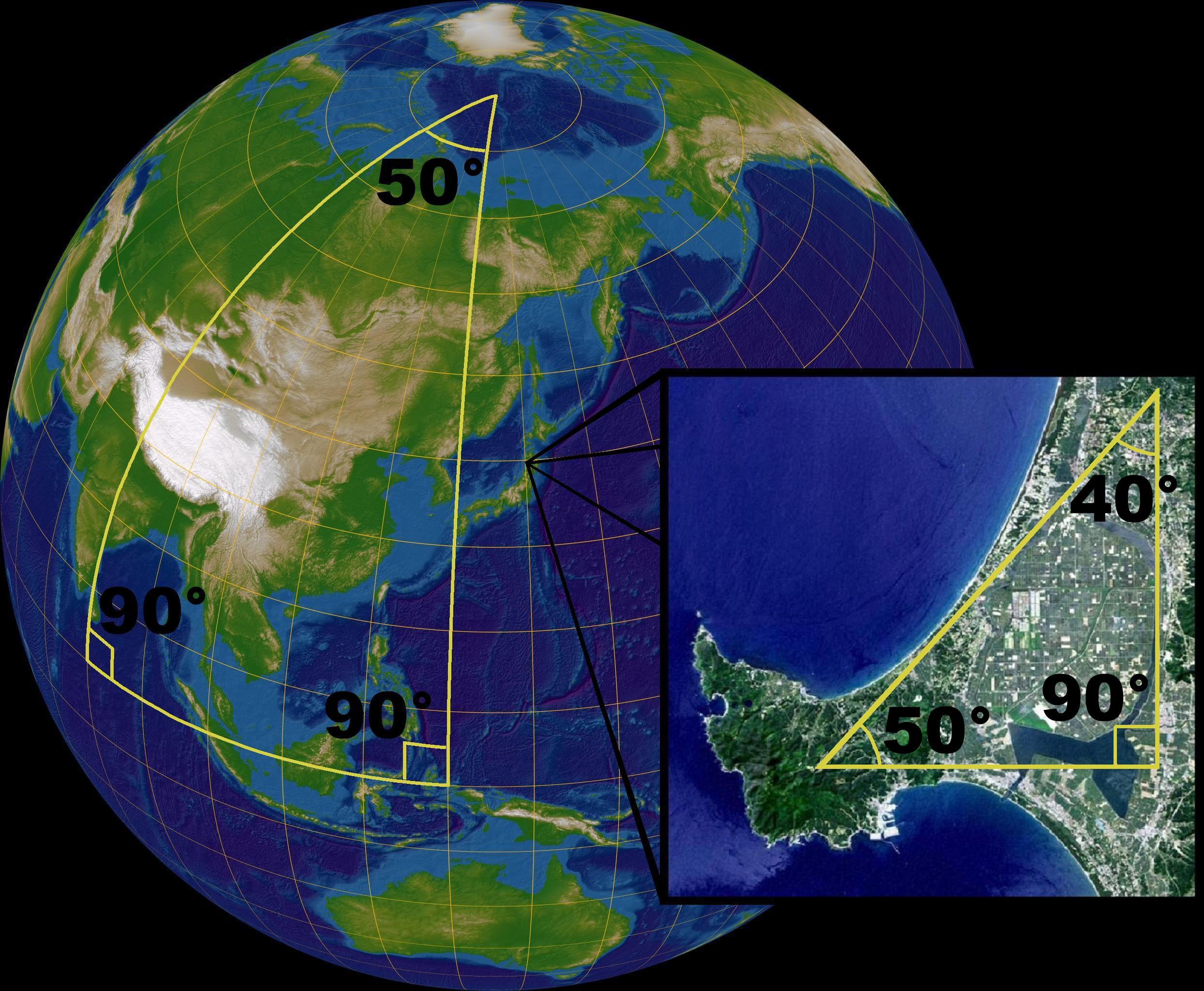
Of course, it is probably useful to remind ourselves that a sphere is a two-dimensional surface in elliptic geometry, even if we’re visualizing it in a three-dimensional space when we’re discussing its properties. Think about the flatlander walking on the surface on the globe: for him, the sphere is two-dimensional indeed, and so it’s not us – our world is not flat: we think in 3D – but the flatlander who is living in a spherically geometric world. It’s probably useful to introduce the term ‘manifold’ here. Spheres – and other surfaces, like the saddle-shaped surfaces we will introduce next – are (two-dimensional) manifolds. Now what’s that? I won’t go into the etymology of the term because that doesn’t help I feel: apparently, it has nothing to do with the verb to fold so it’s not something with many folds or so – although a two-dimensional manifold can look like something folded. A manifold is, quite simply, a topological space that near each point resembles Euclidean space, so we can define a metric on them indeed and do all kinds of things with that metric – locally that is. If the flatlander does these things – like measuring angles and lengths and what have you – close enough to where he is, then he won’t notice he’s living in a non-Euclidean space. That ‘fact’ is also shown above: the angles of a small (i.e. a local) triangle do add up to 180° – approximately that is.
Fine. Let’s move on again.
The other type of non-Euclidean geometry is hyperbolic or Lobachevskian geometry. Hyperbolic geometry is the geometry of saddle-shaped surfaces. Many lines (in fact, an infinite number of them) can be drawn parallel to a given line through a given point (the illustration below shows just one), and the angles of a triangle add up to less than 180°.
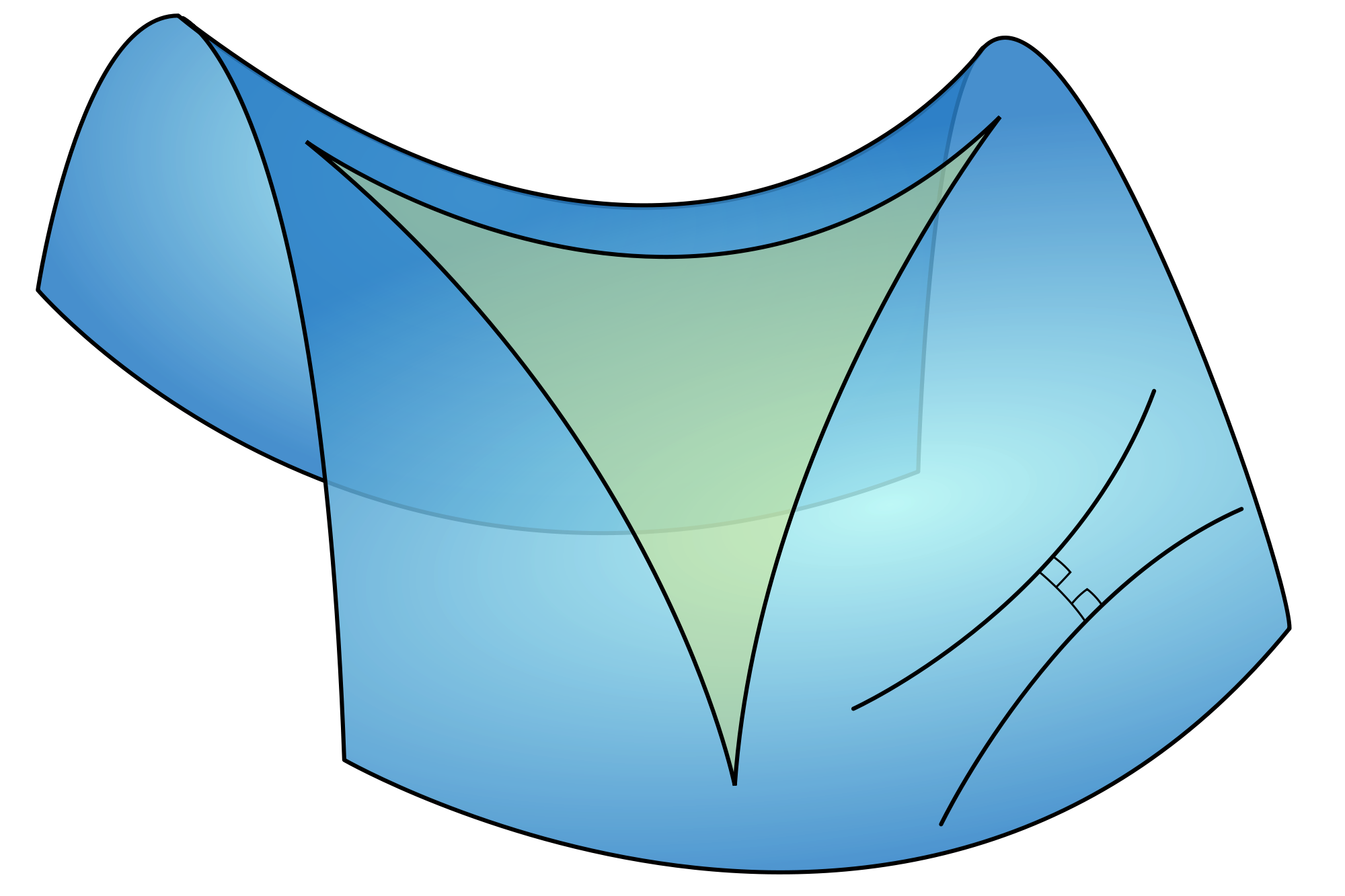
OK… Enough about metric spaces perhaps – except for noting that, when physicists talk about curved space, they obviously mean that the the space we are living in (i.e. the universe) is non-Euclidean: gravity curves it. And let’s add one or two other points as well. Anyone who has read something about Einstein’s special relativity theory will remember that the mathematician Hermann Minkowski added a time dimension to the three ordinary dimensions of space, creating a so-called Minkowski space, which is actually four-dimensional spacetime. So what’s that in mathematical terms? The ‘points’ in Minkowski’s four-dimensional spacetime are referred to as ‘events’. They are also referred to as four-vectors. The important thing to note here is that it’s not an Euclidean space: it is pseudo-Euclidean. Huh?
Let’s skip that for now and not make it any more complicated than it already. Let us just note that the Minkowski space is not only a metric space (and a manifold obviously, which resembles Euclidean space locally, which is why we don’t notice its curvature really): a Minkowski space is also a vector space. So what’s a vector space? The formal definition is clear: a vector space V over a (scalar) field F is a set of elements (vectors) together with two binary operations: addition and scalar multiplication. So we can add the vectors (that is the elements of the vector space) and scale them with a scalar, i.e. an element of the field F (that’s actually where the word ‘scalar’ comes from: something that scales vectors). The addition and scalar multiplication operations need to satisfy a number of axioms but these are quite straightforward (like associativity, commutativity, distributivity, the existence of an additive and multiplicative inverse, etcetera). The scalars are usually real numbers: in that case, the field F is equal to R, the set of real numbers (sorry I can’t use blackboard bold here for symbols so I am just using a bold capital R for the set of the real numbers), and the vector space is referred to as a real vector space. However, they can also be complex numbers: in that case, the field F is equal to C, the set of complex numbers, and the vector space is, obviously, referred to as a complex vector space.
N-tuples of elements of F itself (a1, a2,…, an) are a very straightforward example of a vector space: Euclidean spaces can be denoted as R (the real line), R2 (the Euclidean plane), R3 (Euclidean three-dimensional space), etcetera. Another example, is the set C of complex numbers: that’s a vector space too, and not only over the real numbers (F = R), but also over itself (F = C). OK. Fair enough, I’d say. What’s next?
It becomes somewhat more complicated when the ‘vectors’ (i.e. the elements in the vector space) are mathematical functions: indeed, a space can consists of functions (a function is just another object, isn’t it?), and function spaces can also be vector spaces because we can perform (pointwise) addition and scalar multiplication on functions. Vector spaces can consist of other mathematical objects too. In short, the notion of a ‘vector’ as some kind of arrow defined by some point in space does not cover the true mathematical notion of a vector, which is very general (an element of a ‘vector field’ as defined above). The same goes for fields: we usually think a field consists of numbers (real, complex, or whatever other number one can think of), but a field can also consist of vectors. In fact, vector fields are as common as scalar fields in in physics (think of vectors representing the speed and direction of a moving fluid for example, as opposed to its local temperature – which is a scalar quantity).
Quite confusing, isn’t it? Can we have a vector space over a vector field?
Tricky question. From what I read so far, I am not sure actually. I guess the answer is both yes and no. The second binary operation on the vector space is scalar multiplication, so the field F needs to be a scalar field – not a vector field. Indeed, the formal definition of a vector field is quite formal: F has to be a scalar field. But then complex numbers z can be looked at not only as scalars in their own right (that’s the focus of the complex analysis course that I am currently reading) but also as vectors in their own right. OK, we’re talking a special kind of vectors here (vectors from the origin to the point z) but so what? And then we already noted that C is a vector field over itself, didn’t we?
So how do we define scalar multiplication in this case? Can we use the ‘scalar’ product (aka as the dot product, or the inner product) between two vectors here (as opposed to the cross-product, aka as the vector product tout court)? I am not sure. Not at all actually. Perhaps it is the usual product between two complex numbers – (x+iy)(u+iv) = (xu-yv) + i(xv+yu) – which, unlike the standard ‘scalar’ product between two vectors, returns another complex number as a result (as opposed to the dot product (x,y)·(u,v), which is equal to the real number xu + yv). The Brown & Churchill course on complex analysis which I am reading just notes that “this product [of two complex numbers] is, evidently, neither the scalar nor the vector product used in ordinary vector analysis”. However, because the ‘scalar’ product returns a single (real) number as a result, while the product of two complex numbers is – quite obviously – a complex number in itself, I must assume it’s the above-mentioned ‘usual product between two complex numbers’ that is to be used for ‘scalar’ multiplication in this case (i.e. the case of defining C as a vector field over itself). In addition, the geometric interpretation of multiplying two complex numbers show that it actually is a matter of scaling: the ‘length’ of the complex number zw (i.e. its absolute value) is equal to the product of the absolute value of z and w respectively and, as for its argument (i.e. the angle from the real line), the argument of zw is equal to the sum of the arguments of z and w respectively. In short, this looks very much like what scalar multiplication is supposed to do.
Let’s see if we can confirm the above (i.e. C being a vector field over itself, with scalar multiplication being defined as the product between two complex numbers) at some later point in time. For the moment, I think I’ve had quite enough on – for the moment at least. Indeed, while I note there are many other unexplored spaces, I will not attempt to penetrate these as for now. For example, I note the frequent reference to Hilbert spaces but, from what I understand, this is also some kind of vector space, but then with even more additional structure and/or a more general definition of the ‘objects’ which make up its elements. Its definition involves Cauchy sequences of vectors – and that’s a concept I haven’t studied as yet. To make things even more complicated, there are also Banach spaces – and lots of other things really. So I will need to look at that but, again, for the moment I’ll just leave the matter alone and get back into the nitty-gritty of complex analysis. Doing so will probably clarify all of the more subtle points mentioned above.
[…] Wow! It’s been quite a journey so far, and I am still in the first chapters of the course only!
PS: I did look it up just now (i.e. a few days later than when I wrote the text above) and my inference is correct: C is a complex vector space over itself, and the formula to be used for scalar multiplication is the standard formula for multiplying complex numbers: (x+iy)(u+iv) = (xu-yv) + i(xv+yu). C2, or Cn in general, are other examples of complex vector spaces (i.e. a vector space over C).