
Pre-script (dated 26 June 2020): This post has become less relevant (even irrelevant, perhaps) because my views on all things quantum-mechanical have evolved significantly as a result of my progression towards a more complete realist (classical) interpretation of quantum physics. In addition, some of the material was removed by a dark force (that also created problems with the layout, I see now). In any case, we recommend you read our recent papers. I keep blog posts like these mainly because I want to keep track of where I came from. I might review them one day, but I currently don’t have the time or energy for it. 🙂
Original post:
When re-reading Feynman’s ‘explanation’ of Bose-Einstein versus Fermi-Dirac statistics (Lectures, Vol. III, Chapter 4), and my own March 2014 post summarizing his argument, I suddenly felt his approach raises as many questions as it answers. So I thought it would be good to re-visit it, which is what I’ll do here. Before you continue reading, however, I should warn you: I am not sure I’ll manage to do a better job now, as compared to a few months ago. But let me give it a try.
Setting up the experiment
The (thought) experiment is simple enough: what’s being analyzed is the (theoretical) behavior of two particles, referred to as particle a and particle b respectively that are being scattered into two detectors, referred to as 1 and 2. That can happen in two ways, as depicted below: situation (a) and situation (b). [And, yes, it’s a bit confusing to use the same letters a and b here, but just note the brackets and you’ll be fine.] It’s an elastic scattering and it’s seen in the center-of-mass reference frame in order to ensure we can analyze it using just one variable, θ, for the angle of incidence. So there is no interaction between those two particles in a quantum-mechanical sense: there is no exchange of spin (spin flipping) nor is there any exchange of energy–like in Compton scattering, in which a photon gives some of its energy to an electron, resulting in a Compton shift (i.e. the wavelength of the scattered photon is different than that of the incoming photon). No, it’s just what it is: two particles deflecting each other. […] Well… Maybe. Let’s fully develop the argument to see what’s going on.

First, the analysis is done for two non-identical particles, say an alpha particle (i.e. a helium nucleus) and then some other nucleus (e.g. oxygen, carbon, beryllium,…). Because of the elasticity of the ‘collision’, the possible outcomes of the experiment are binary: if particle a gets into detector 1, it means particle b will be picked up by detector 2, and vice versa. The first situation (particle a gets into detector 1 and particle b goes into detector 2) is depicted in (a), i.e. the illustration on the left above, while the opposite situation, exchanging the role of the particles, is depicted in (b), i.e. the illustration on the right-hand side. So these two ‘ways’ are two different possibilities which are distinguishable not only in principle but also in practice, for non-identical particles that is (just imagine a detector which can distinguish helium from oxygen, or whatever other substance the other particle is). Therefore, strictly following the rules of quantum mechanics, we should add the probabilities of both events to arrive at the total probability of some particle (and with ‘some’, I mean particle a or particle b) ending up in some detector (again, with ‘some’ detector, I mean detector 1 or detector 2).
Now, this is where Feynman’s explanation becomes somewhat tricky. The whole event (i.e. some particle ending up in some detector) is being reduced to two mutually exclusive possibilities that are both being described by the same (complex-valued) wave function f, which has that angle of incidence as its argument. To be precise: the angle of incidence is θ for the first possibility and it’s π–θ for the second possibility. That being said, it is obvious, even if Feynman doesn’t mention it, that both possibilities actually represent a combination of two separate things themselves:
- For situation (a), we have particle a going to detector 1 and particle b going to detector 2. Using Dirac’s so-called bra-ket notation, we should write 〈1|a〉〈2|b〉 = f(θ), with f(θ) a probability amplitude, which should yield a probability when taking its absolute square: P(θ) = |f(θ)|2.
- For situation (b), we have particle b going to detector 1 and particle a going to 2, so we have 〈1|b〉〈2|a〉, which Feynman equates with f(π–θ), so we write 〈1|b〉〈2|a〉 = 〈2|a〉〈1|b〉 = f(π–θ).
Now, Feynman doesn’t dwell on this–not at all, really–but this casual assumption–i.e. the assumption that situation (b) can be represented by using the same wave function f–merits some more reflection. As said, Feynman is very brief on it: he just says situation (b) is the same situation as (a), but then detector 1 and detector 2 being switched (so we exchange the role of the detectors, I’d say). Hence, the relevant angle is π–θ and, of course, it’s a center-of-mass view again so if a goes to 2, then b has to go to 1. There’s no Third Way here. In short, a priori it would seem to be very obvious indeed to associate only one wave function (i.e. that (complex-valued) f(θ) function) with the two possibilities: that wave function f yields a probability amplitude for θ and, hence, it should also yield some (other) probability amplitude for π–θ, i.e. for the ‘other’ angle. So we have two probability amplitudes but one wave function only.
You’ll say: Of course! What’s the problem? Why are you being fussy? Well… I think these assumptions about f(θ) and f(π–θ) representing the underlying probability amplitudes are all nice and fine (and, yes, they are very reasonable indeed), but I also think we should take them for what they are at this moment: assumptions.
Huh? Yes. At this point, I would like to draw your attention to the fact that the only thing we can measure are real-valued possibilities. Indeed, when we do this experiment like a zillion times, it will give us some real number P for the probability that a goes to 1 and b goes to 2 (let me denote this number as P(θ) = Pa→1 and b→2), and then, when we change the angle of incidence by switching detector 1 and 2, it will also give us some (other) real number for the probability that a goes to 2 and b goes to 1 (i.e. a number which we can denote as P(π–θ) = Pa→2 and b→1). Now, while it would seem to be very reasonable that the underlying probability amplitudes are the same, we should be honest with ourselves and admit that the probability amplitudes are something we cannot directly measure.
At this point, let me quickly say something about Dirac’s bra-ket notation, just in case you haven’t heard about it yet. As Feynman notes, we have to get away from thinking too much in terms of wave functions traveling through space because, in quantum mechanics, all sort of stuff can happen (e.g. spin flipping) and not all of it can be analyzed in terms of interfering probability amplitudes. Hence, it’s often more useful to think in terms of a system being in some state and then transitioning to some other state, and that’s why that bra-ket notation is so helpful. We have to read these bra-kets from right to left: the part on the right, e.g. |a〉, is the ket and, in this case, that ket just says that we’re looking at some particle referred to as particle a, while the part on the left, i.e. 〈1|, is the bra, i.e. a shorthand for particle a having arrived at detector 1. If we’d want to be complete, we should write:
〈1|a〉 = 〈particle a arrives at detector 1|particle a leaves its source〉
Note that 〈1|a〉 is some complex-valued number (i.e. a probability amplitude) and so we multiply it here with some other complex number, 〈2|b〉, because it’s two things happening together. As said, don’t worry too much about it. Strictly speaking, we don’t need wave functions and/or probability amplitudes to analyze this situation because there is no interaction in the quantum-mechanical sense: we’ve got a scattering process indeed (implying some randomness in where those particles end up, as opposed to what we’d have in a classical analysis of two billiard balls colliding), but we do not have any interference between wave functions (probability amplitudes) here. We’re just introducing the wave function f because we want to illustrate the difference between this situation (i.e. the scattering of non-identical particles) and what we’d have if we’d be looking at identical particles being scattered.
At this point, I should also note that this bra-ket notation is more in line with Feynman’s own so-called path integral formulation of quantum mechanics, which is actually implicit in his line of argument: rather than thinking about the wave function as representing the (complex) amplitude of some particle to be at point x in space at point t in time, we think about the amplitude as something that’s associated with a path, i.e. one of the possible itineraries from the source (its origin) to the detector (its destination). That explains why this f(θ) function doesn’t mention the position (x) and space (t) variables. What x and t variables would we use anyway? Well… I don’t know. It’s true the position of the detectors is fully determined by θ, so we don’t need to associate any x or t with them. Hence, if we’d be thinking about the space-time variables, then we should be talking the position in space and time of both particle a and particle b. Indeed, it’s easy to see that only a slight change in the horizontal (x) or vertical position (y) of either particle would ensure that both particles do not end up in the detectors. However, as mentioned above, Feynman doesn’t even mention this. Hence, we must assume that any randomness in any x or t variable is captured by that wave function f, which explains why this is actually not a classical analysis: so, in short, we do not have two billiard balls colliding here.
Hmm… You’ll say I am a nitpicker. You’ll say that, of course, any uncertainty is indeed being incorporated in the fact that we represent what’s going on by a wave function f which we cannot observe directly but whose absolute square represents a probability (or, to use precise statistical terminology, a probability density), which we can measure: P = |f(θ)|2 = f(θ)·f*(θ), with f* the complex conjugate of the complex number f. So… […] What? Well… Nothing. You’re right. This thought experiment describes a classical situation (like two billiard balls colliding) and then it doesn’t, because we cannot predict the outcome (i.e. we can’t say where the two billiard balls are going to end up: we can only describe the likely outcome in terms of probabilities Pa→1 and b→2 = |f(θ)|2 and Pa→2 and b→1 = |f(π–θ)|2. Of course, needless to say, the normalization condition should apply: if we add all probabilities over all angles, then we should get 1, we can write: ∫|f(θ)|2dθ = ∫f(θ)·f*(θ)dθ = 1. So that’s it, then?
No. Let this sink in for a while. I’ll come back to it. Let me first make a bit of a detour to illustrate what this thought experiment is supposed to yield, and that’s a more intuitive explanation of Bose-Einstein statistics and Fermi-Dirac statistics, which we’ll get out of the experiment above if we repeat it using identical particles. So we’ll introduce the terms Bose-Einstein statistics and Fermi-Dirac statistics. Hence, there should also be some term for the reference situation described above, i.e a situation in which we non-identical particles are ‘interacting’, so to say, but then with no interference between their wave functions. So, when everything is said and done, it’s a term we should associate with classical mechanics. It’s called Maxwell-Boltzmann statistics.
Huh? Why would we need ‘statistics’ here? Well… We can imagine many particles engaging like this–just colliding elastically and, thereby, interacting in a classical sense, even if we don’t know where exactly they’re going to end up, because of uncertainties in initial positions and what have you. In fact, you already know what this is about: it’s the behavior of particles as described by the kinetic theory of gases (often referred to as statististical mechanics) which, among other things, yields a very elegant function for the distribution of the velocities of gas molecules, as shown below for various gases (helium, neon, argon and xenon) at one specific temperature (25º C), i.e. the graph on the left-hand side, or for the same gas (oxygen) at different temperatures (–100º C, 20º C and 600º C), i.e. the graph on the right-hand side.
Now, all these density functions and what have you are, indeed, referred to as Maxwell-Boltzmann statistics, by physicists and mathematicians that is (you know they always need some special term in order to make sure other people (i.e. people like you and me, I guess) have trouble understanding them).
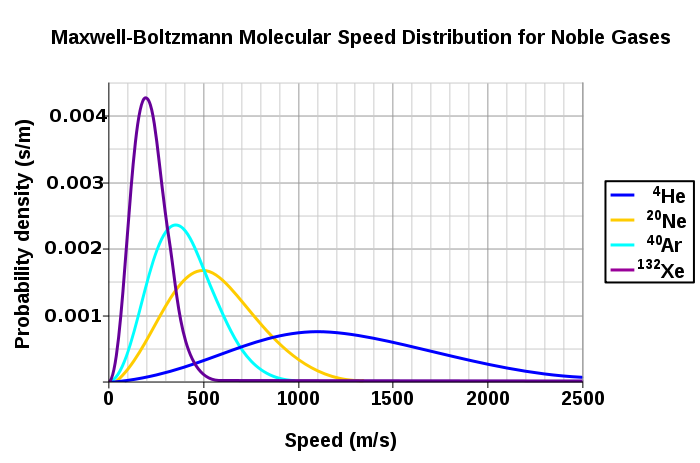
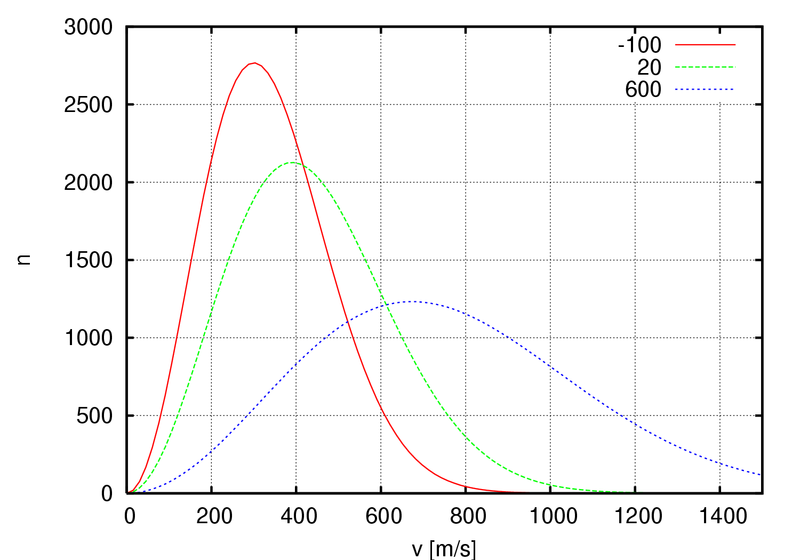
In fact, we get the same density function for other properties of the molecules, such as their momentum and their total energy. It’s worth elaborating on this, I think, because I’ll later compare with Bose-Einstein and Fermi-Dirac statistics.
Maxwell-Boltzmann statistics
Kinetic gas theory yields a very simple and beautiful theorem. It’s the following: in a gas that’s in thermal equilibrium (or just in equilibrium, if you want), the probability (P) of finding a molecule with energy E is proportional to e–E/kT, so we have:
P ∝ e–E/kT
Now that’s a simple function, you may think. If we treat E as just a continuous variable, and T as some constant indeed – hence, if we just treat (the probability) P as a function of (the energy) E – then we get a function like the one below (with the blue, red and green using three different values for T).
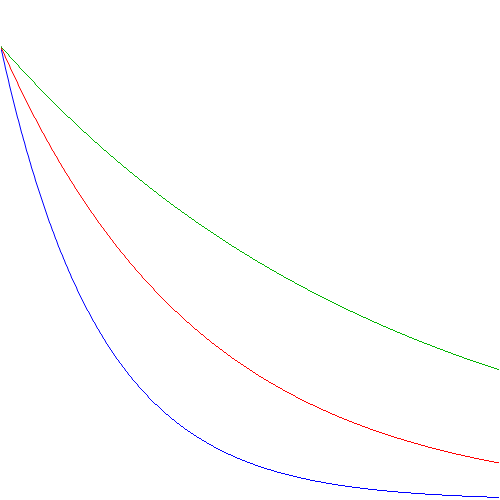
So how do we relate that to the nice bell-shaped curves above? The very simple graphs above seem to indicate the probability is greatest for E = 0, and then just goes down, instead of going up initially to reach some maximum around some average value and then drop down again. Well… The fallacy here, of course, is that the constant of proportionality is itself dependent on the temperature. To be precise, the probability density function for velocities is given by:
![]()
The function for energy is similar. To be precise, we have the following function:
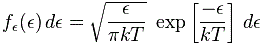
This (and the velocity function too) is a so-called chi-squared distribution, and ϵ is the energy per degree of freedom in the system. Now these functions will give you such nice bell-shaped curves, and so all is alright. In any case, don’t worry too much about it. I have to get back to that story of the two particles and the two detectors.
However, before I do so, let me jot down two (or three) more formulas. The first one is the formula for the expected number 〈Ni〉 of particles occupying energy level εi (and the brackets here, 〈Ni〉, have nothing to do with the bra-ket notation mentioned above: it’s just a general notation for some expected value):
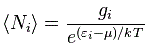 This formula has the same shape as the ones above but we brought the exponential function down, into the denominator, so the minus sign disappears. And then we also simplified it by introducing that gi factor, which I won’t explain here, because the only reason why I wanted to jot this down is to allow you to compare this formula with the equivalent formula when (a) Fermi-Dirac and (b) Bose-Einstein statistics apply:
This formula has the same shape as the ones above but we brought the exponential function down, into the denominator, so the minus sign disappears. And then we also simplified it by introducing that gi factor, which I won’t explain here, because the only reason why I wanted to jot this down is to allow you to compare this formula with the equivalent formula when (a) Fermi-Dirac and (b) Bose-Einstein statistics apply:
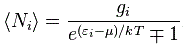
Do you see the difference? The only change in the formula is the ±1 term in the denominator: we have a minus one (–1) for Fermi-Dirac statistics and a plus one (+1) for Bose-Einstein statistics indeed. That’s all. That’s the difference with Maxwell-Boltzmann statistics.
Huh? Yes. Think about it, but don’t worry too much. Just make a mental note of it, as it will be handy when you’d be exploring related articles. [And, of course, please don’t think I am bagatellizing the difference between Maxwell-Boltzmann, Bose-Einstein and Fermi-Dirac statistics here: that ±1 term in the denominator is, obviously, a very important difference, as evidenced by the consequences of formulas like the one above: just think about the crowding-in effect in lasers as opposed to the Pauli exclusion principle, for example. :-)]
Setting up the experiment (continued)
Let’s get back to our experiment. As mentioned above, we don’t really need probability amplitudes in the classical world: ordinary probabilities, taking into account uncertainties about initial conditions only, will do. Indeed, there’s a limit to the precision with which we can measure the position in space and time of any particle in the classical world as well and, hence, we’d expect some randomness (as captured in the scattering phenomenon) but, as mentioned above, ordinary probabilities would do to capture that. Nevertheless, we did associate probability amplitudes with the events described above in order to illustrate the difference with the quantum-mechanical world. More specifically, we distinguished:
- Situation (a): particle a goes to detector 1 and b goes to 2, versus
- Situation (b): particle a goes to 2 and b goes to 1.
In our bra-ket notation:
- 〈1|a〉〈2|b〉 = f(θ), and
- 〈1|b〉〈2|a〉 = f(π–θ).
The f(θ) function is a quantum-mechanical wave function. As mentioned above, while we’d expect to see some space (x) and time (t) variables in it, these are, apparently, already captured by the θ variable. What about f(π–θ)? Well… As mentioned above also, that’s just the same function as f(θ) but using the angle π–θ as the argument. So, the following remark is probably too trivial to note but let me do it anyway (to make sure you understand what we’re modeling here really): while it’s the same function f, the values f(θ) and f(π–θ) are, of course, not necessarily equal and, hence, the corresponding probabilities are also not necessarily the same. Indeed, some angles of scattering may be more likely than others. However, note that we assume that the function f itself is exactly the same for the two situations (a) and (b), as evidenced by that normalization condition we assume to be respected: if we add all probabilities over all angles, then we should get 1, so ∫|f(θ)|2dθ = ∫f(θ)·f*(θ)dθ = 1.
So far so good, you’ll say. However, let me ask the same critical question once again: why would we use the same wave function f for the second situation?
Huh? You’ll say: why wouldn’t we? Well… Think about it. Again, how do we find that f(θ) function? The assumption here is that we just do the experiment a zillion times while varying the angle θ and, hence, that we’ll find some average corresponding to P(θ), i.e. the probability. Now, the next step then is to equate that average value to |f(θ)|2 obviously, because we have this quantum-mechanical theory saying probabilities are the absolute square of probability amplitudes. And, so… Well… Yes. We then just take the square root of the P function to find the f(θ) function, isn’t it?
Well… No. That’s where Feynman is not very accurate when it comes to spelling out all of the assumptions underpinning this thought experiment. We should obviously watch out here, as there’s all kinds of complications when you do something like that. To a large extent (perhaps all of it), the complications are mathematical only.
First, note that any number (real or complex, but note that |f(θ)|2 is a real number) has two distinct real square roots: a positive and a negative one: x = ± √x2. Secondly, we should also note that, if f(θ) is a regular complex-valued wave function of x and t and θ (and with ‘regular’, we mean, of course, that’s it’s some solution to a Schrödinger (or Schrödinger-like) equation), then we can multiply it with some random factor shifting its phase Θ (usually written as Θ = kx–ωt+α) and the square of its absolute value (i.e. its squared norm) will still yield the same value. In mathematical terms, such factor is just a complex number with a modulus (or length or norm–whatever terminology you prefer) equal to one, which we can write as a complex exponential: eiα, for example. So we should note that, from a mathematical point of view, any function eiαf(θ) will yield the same probabilities as f(θ). Indeed,
|f(θ)|2 = |eiαf(θ)|2 = (|eiα||f(θ)|)2 = |eiα|2|f(θ)|2 = 12|f(θ)|2
Likewise, while we assume that this function f(π–θ) is the same function f as that f(θ) function, from a mathematical point of view, the function eiβf(π–θ) would do just as well, because its absolute square yields the very same (real) probability |f(π–θ)|2. So the question as to what wave function we should take for the probability amplitude is not as easy to answer as you may think. Huh? So what function should we take then? Well… We don’t know. Fortunately, it doesn’t matter, for non-identical particles that is. Indeed, when analyzing the scattering of non-identical particles, we’re interested in the probabilities only and we can calculate the total probability of particle a ending up in detector 1 or 2 (and, hence, particle b ending up in detector 2 or 1) as the following sum:
|eiαf(θ)|2 +|eiβf(π–θ)|2 = |f(θ)|2 +|f(π–θ)|2.
In other words, for non-identical particles, these phase factors (eiα or eiβ) don’t matter and we can just forget about them.
However, and that’s the crux of the matter really, we should mention them, of course, in case we’d have to add the probability amplitudes–which is exactly what we’ll have to do when we’re looking at identical particles, of course. In fact, in that case (i.e. when these phase factors eiα and eiβ will actually matter), you should note that what matters really is the phase difference, so we could replace α and β with some δ (which is what we’ll do below).
However, let’s not put the cart before the horse and conclude our analysis of what’s going on when we’re considering non-identical parties: in that case, this phase difference doesn’t matter. And the remark about the positive and negative square root doesn’t matter either. In fact, if you want, you can subsume it under the phase difference story by writing eiα as eiα = ± 1. To be more explicit: we could say that –f(θ) is the probability amplitude, as |–f(θ)|2 is also equal to that very same real number |f(θ)|2. OK. Done.
Bose-Einstein and Fermi-Dirac statistics
As I mentioned above, the story becomes an entirely different one when we’re doing the same experiment with identical particles. At this point, Feynman’s argument becomes rather fuzzy and, in my humble opinion, that’s because he refused to be very explicit about all of those implicit assumptions I mentioned above. What I can make of it, is the following:
1. We know that we’ll have to add probability amplitudes, instead of probabilities, because we’re talking one event that can happen in two indistinguishable ways. Indeed, for non-identical particles, we can, in principle (and in practice) distinguish situation (a) and (b) – and so that’s why we only have to add some real-valued numbers representing probabilities – but so we cannot do do that for identical particles.
2. Situation (a) is still being described by some probability amplitude f(θ). We don’t know what function exactly, but we assume there is some unique wave function f(θ) out there that accurately describes the probability amplitude of particle a going to 1 (and, hence, particle b going to 2), even if we can’t tell which is a and which is b. What about the phase factor? Well… We just assume we’ve chosen our t such that α = 0. In short, the assumption is that situation (a) is represented by some probability amplitude (or wave function, if you prefer that term) f(θ).
3. However, a (or some) particle (i.e. particle a or particle b) ending up in a (some) detector (i.e. detector 1 or detector 2) may come about in two ways that cannot be distinguished one from the other. One is the way described above, by that wave function f(θ). The other way is by exchanging the role of the two particles. Now, it would seem logical to associate the amplitude f(π–θ) with the second way. But we’re in the quantum-mechanical world now. There’s uncertainty, in position, in momentum, in energy, in time, whatever. So we can’t be sure about the phase. That being said, the wave function will still have the same functional form, we must assume, as it should yield the same probability when squaring. To account for that, we will allow for a phase factor, and we know it will be important when adding the amplitudes. So, while the probability for the second way (i.e. the square of its absolute value) should be the same, its probability amplitude does not necessarily have to be the same: we have to allow for positive and negative roots or, more generally, a possible phase shift. Hence, we’ll write the probability amplitude as eiδf(π–θ) for the second way. [Why do I use δ instead of β? Well… Again: note that it’s the phase difference that matters. From a mathematical point of view, it’s the same as inserting an eiβ factor: δ can take on any value.]
4. Now it’s time for the Big Trick. Nature doesn’t matter about our labeling of particles. If we have to multiply the wave function (i.e. f(π–θ), or f(θ)–it’s the same: we’re talking a complex-valued function of some variable (i.e. the angle θ) here) with a phase factor eiδ when exchanging the roles of the particles (or, what amounts to the same, exchanging the role of the detectors), we should get back to our point of departure (i.e. no exchange of particles, or detectors) when doing that two times in a row, isn’t it? So we exchange the role of particle a and b in this analysis (or the role of the detectors), and then we’d exchange their roles once again, then there’s no exchange of roles really and we’re back at the original situation. So we must have eiδeiδf(θ) = f(θ) (and eiδeiδf(π–θ) = f(π–θ) of course, which is exactly the same statement from a mathematical point of view).
5. However, that means (eiδ)2 = +1, which, in turn, implies that eiδ is plus or minus one: eiδ = ± 1. So that means the phase difference δ must be equal to 0 or π (or –π, which is the same as +π).
In practical terms, that means we have two ways of combining probability amplitudes for identical particles: we either add them or, else, we subtract them. Both cases exist in reality, and lead to the dichotomy between Bose and Fermi particles:
- For Bose particles, we find the total probability amplitude for this scattering event by adding the two individual amplitudes: f(θ) + f(π–θ).
- For Fermi particles, we find the total probability amplitude for this scattering event by subtracting the two individual amplitudes: f(θ) – f(π–θ).
As compared to the probability for non-identical particles which, you’ll remember, was equal to |f(θ)|2 +|f(π–θ)|2, we have the following Bose-Einstein and Fermi-Dirac statistics:
- For Bose particles: the combined probability is equal to |f(θ) + f(π–θ)|2. For example, if θ is 90°, then we have a scattering probability that is exactly twice the probability for non-identical particles. Indeed, if θ is 90°, then f(θ) = f(π–θ), and then we have |f(π/2) + f(π/2)|2 = |2f(π/2)|2 = 4|f(π/2)|2. Now, that’s two times |f(π/2)|2 +|f(π/2)|2 = 2|f(π/2)|2 indeed.
- For Fermi particles (e.g. electrons), we have a combined probability equal to |f(θ) – f(π–θ)|2. Again, if θ is 90°, f(θ) = f(π–θ), and so it would mean that we have a combined probability which is equal to zero ! Now, that‘s a strange result, isn’t it? It is. Fortunately, the strange result has to be modified because electrons will also have spin and, hence, in half of the cases, the two electrons will actually not be identical but have opposite spin. That changes the analysis substantially (see Feynman’s Lectures, III-3-12). To be precise, if we take the spin factor into, we’ll find a total probability (for θ = 90°) equal to |f(π/2)|2, so that’s half of the probability for non-identical particles.
Hmm… You’ll say: Now that was a complicated story! I fully agree. Frankly, I must admit I feel like I still don’t quite ‘get‘ the story with that phase shift eiδ, in an intuitive way that is (and so that’s the reason for going through the trouble of writing out this post). While I think it makes somewhat more sense now (I mean, more than when I wrote a post on this in March), I still feel I’ve only brought some of the implicit assumptions to the fore. In essence, what we’ve got here is a mathematical dichotomy (or a mathematical possibility if you want) corresponding to what turns out to be an actual dichotomy in Nature: in quantum-mechanics, particles are either bosons or fermions. There is no Third Way, in quantum-mechanics that is (there is a Third Way in reality, of course: that’s the classical world!).
I guess it will become more obvious as I’ll get somewhat more acquainted with the real arithmetic involved in quantum-mechanical calculations over the coming weeks. In short, I’ve analyzed this thing over and over again, but it’s still not quite clear me. I guess I should just move on and accept that:
- This explanation ‘explains’ the experimental evidence, and that’s different probabilities for identical particles as compared to non-identical particles.
- This explanation ‘complements’ analyses such as that 1916 analysis of blackbody radiation by Einstein (see my post on that), which approaches interference from an angle that’s somewhat more intuitive.
A numerical example
I’ve learned that, when some theoretical piece feels hard to read, an old-fashioned numerical example often helps. So let’s try one here. We can experiment with many functional forms but let’s keep things simple. From the illustration (which I copy below for your convenience), that angle θ can take any value between −π and +π, so you shouldn’t think detector 1 can only be ‘north’ of the collision spot: it can be anywhere.
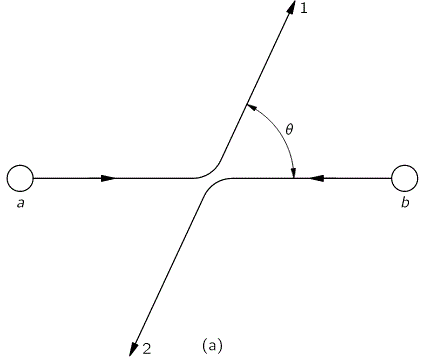
Now, it may or may not make sense (and please work out other examples than this one here), but let’s assume particle a and b are more likely to go in a line that’s more or less straight. In other words, the assumption is that both particles deflect each other only slightly, or even not at all. After all, we’re talking ‘point-like’ particles here and so, even when we try hard, it’s hard to make them collide really.
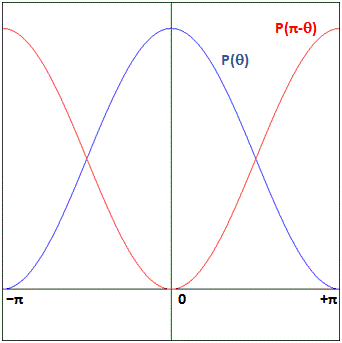
That would amount to a typical bell-shaped curve for that probability density curve P(θ): one like the blue curve below. That one shows that the probability of particle a and b just bouncing back (i.e. θ ≈ ±π) is (close to) zero, while it’s highest for θ ≈ 0, and some intermediate value for anything angle in-between. The red curve shows P(π–θ), which can be found by mirroring the P(θ) around the vertical axis, which yields the same function because the function is symmetrical: P(θ) = P(–θ), and then shifting it by adding the vertical distance π. It should: it’s the second possibility, remember? Particle a ending up in detector 2. But detector 2 is positioned at the angle π–θ and, hence, if π–θ is close to ±π (so if θ ≈ 0), that means particle 1 is basically bouncing back also, which we said is unlikely. On the other hand, if detector 2 is positioned at an angle π–θ ≈ 0, then we have the highest probability of particle a going right to it. In short, the red curve makes sense too, I would think. [But do think about yourself: you’re the ultimate judge!]
The harder question, of course, concerns the choice of some wave function f(θ) to match those P curves above. Remember that these probability densities P are real numbers and any real number is the absolute square (aka the squared norm) of an infinite number of complex numbers! So we’ve got l’embarras du choix, as they say in French. So… What do to? Well… Let’s keep things simple and stupid and choose a real-valued wave function f(θ), such as the blue function below. Huh? You’ll wonder if that’s legitimate. Frankly, I am not 100% sure, but why not? The blue f(θ) function will give you the blue P(θ) above, so why not go along with it? It’s based on a cosine function but it’s only half of a full cycle. Why? Not sure. I am just trying to match some sinusoidal function with the probability density function here, so… Well… Let’s take the next step.
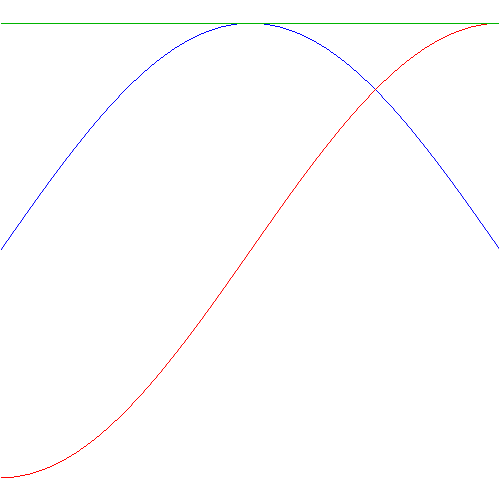
The red graph above is the associated f(π–θ) function. Could we choose another one? No. There’s no freedom of choice here, I am afraid: if we choose a functional form for f(θ), then our f(π–θ) function is fixed too. So it is what it is: negative between –π and 0, and positive between 0 and +π and 0. Now that is definitely not good, because f(π–θ) for θ = –π is not equal to f(π–θ) for θ = +π: they’re opposite values. That’s nonsensical, isn’t it? Both the f(θ) and the f(π–θ) should be something cyclical… But, again, let’s go along with it as for now: note that the green horizontal line is the sum of the squared (absolute) values of f(θ) and f(π–θ), and note that it’s some constant.
Now, that’s a funny result, because I assumed both particles were more likely to go in some straight line, rather than recoil with some sharp angle θ. It again indicates I must be doing something wrong here. However, the important thing for me here is to compare with the Bose-Einstein and Fermi-Dirac statistics. What’s the total probability there if we take that blue f(θ) function? Well… That’s what’s shown below. The horizontal blue line is the same as the green line in the graph above: a constant probability for some particle (a or b) ending up in some detector (1 or 2). Note that the surface, when added, of the two rectangles above the x-axis (i.e. the θ-axis) should add up to 1. The red graph gives the probability when the experiment is carried out for (identical) bosons (or Bose particles as I like to call them). It’s weird: it makes sense from a mathematical point of view (the surface under the curve adds up to the same surface under the blue line, so it adds up to 1) but, from a physics point of view, what does this mean? A maximum at θ = π/2 and a minimum at θ = –π/2? Likewise, how to interpret the result for fermions?
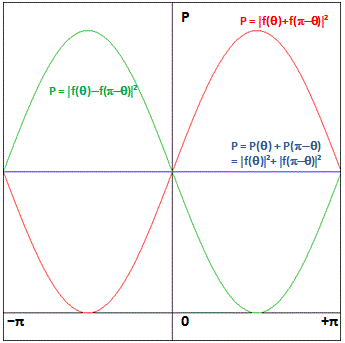
Is this OK? Well… To some extent, I guess. It surely matches the theoretical results I mentioned above: we have twice the probability for bosons for θ = 90° (red curve), and a probability equal to zero for the same angle when we’re talking fermions (green curve). Still, this numerical example triggers more questions than it answers. Indeed, my starting hypothesis was very symmetrical: both particle a and b are likely to go in a straight line, rather than being deflected in some sharp(er) angle. Now, while that hypothesis gave a somewhat unusual but still understandable probability density function in the classical world (for non-identical particles, we got a constant for P(θ) + P(π–θ)), we get this weird asymmetry in the quantum-mechanical world: we’re much more likely to catch a boson in a detector ‘north’ of the line of firing than ‘south’ of it, and vice versa for fermions.
That’s weird, to say the least. So let’s go back to the drawing board and take another function for f(θ) and, hence, for f(π–θ). This time, the two graphs below assume that (i) f(θ) and f(π–θ) have a real as well as an imaginary part and (ii) that they go through a full cycle, instead of a half-cycle only. This is done by equating the real part of the two functions with cos(θ) and cos(π–θ) respectively, and their imaginary part with sin(θ) and sin(π–θ) respectively. [Note that we conveniently forget about the normalization condition here.]
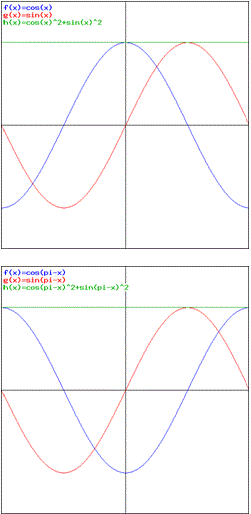
What do we see? Well… The imaginary part of f(θ) and f(π–θ) is the same, because sin(π–θ) = sin(θ). We also see that the real part of f(θ) and f(π–θ) are the same except for a phase difference equal to π: cos(π–θ) = cos[–(θ–π)] = cos(θ–π). More importantly, we see that the absolute square of both f(θ) and f(π–θ) yields the same constant, and so their sum P = |f(θ)|2 +|f(π–θ)|2 = 2|f(θ)|2 = 2|f(π–θ)|2 = 2P(θ) = 2P(π–θ). So that’s another constant. That’s actually OK because, this time, I did not favor one angle over the other (so I did not assume both particles were more likely to go in some straight line rather than recoil).
Now, how does this compare to Bose-Einstein and Fermi-Dirac statistics? That’s shown below. For Bose-Einstein (left-hand side), the sum of the real parts of f(θ) and f(π–θ) yields zero (blue line), while the sum of their imaginary parts (i.e. the red graph) yields a sine-like function but it has double the amplitude of sin(θ). That’s logical: sin(θ) + sin(π–θ) = 2sin(θ). The green curve is the more interesting one, because that’s the total probability we’re looking for. It has two maxima now, at +π/2 and at –π/2. That’s good, as it does away with that ‘weird asymmetry’ we got when we used a ‘half-cycle’ f(θ) function.
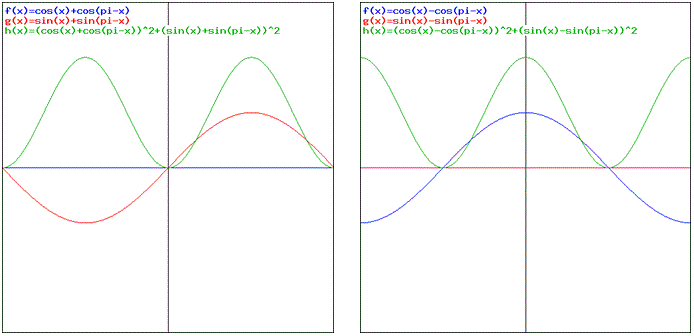
Likewise, the Fermi-Dirac probability density function looks good as well (right-hand side). We have the imaginary parts of f(θ) and f(π–θ) that ‘add’ to zero: sin(θ) – sin(π–θ) = 0 (I put ‘add’ between brackets because, with Fermi-Dirac, we’re subtracting of course), while the real parts ‘add’ up to a double cosine function: cos(θ) – cos(π–θ) = cos(θ) – [–cos(θ)] = 2cos(θ). We now get a minimum at +π/2 and at –π/2, which is also in line with the general result we’d expect. The (final) graph below summarizes our findings. It gives the three ‘types’ of probabilities, i.e. the probability of finding some particle in some detector as a function of the angle –π < θ < +π using:
- Maxwell-Boltzmann statistics: that’s the green constant (non-identical particles, and probability does not vary with the angle θ).
- Bose-Einstein: that’s the blue graph below. It has two maxima, at +π/2 and at –π/2, and two minima, at 0 and at ±π (+π and –π are the same angle obviously), with the maxima equal to twice the value we get under Maxwell-Boltzmann statistics.
- Finally, the red graph gives the Fermi-Dirac probabilities. Also two maxima and minima, but at different places: the maxima are at θ = 0 and θ = ±π, while the minima are at at +π/2 and at –π/2.

Funny, isn’t it? These probability density functions are all well-behaved, in the sense that they add up to the same total (which should be 1 when applying the normalization condition). Indeed, the surfaces under the green, blue and red lines are obviously the same. But so we get these weird fluctuations for Bose-Einstein and Fermi-Dirac statistics, favoring two specific angles over all others, while there’s no such favoritism when the experiment involves non-identical particles. This, of course, just follows from our assumption concerning f(θ). What if we double the frequency of f(θ), i.e. from one cycle to two cycles between –π and +π? Well… Just try it: take f(θ) = cos(2·θ) + isin(2·θ) and do the calculations. You should get the following probability graphs: we have the same green line for non-identical particles, but interference with four maxima (and four minima) for the Bose-Einstein and Fermi-Dirac probabilities.
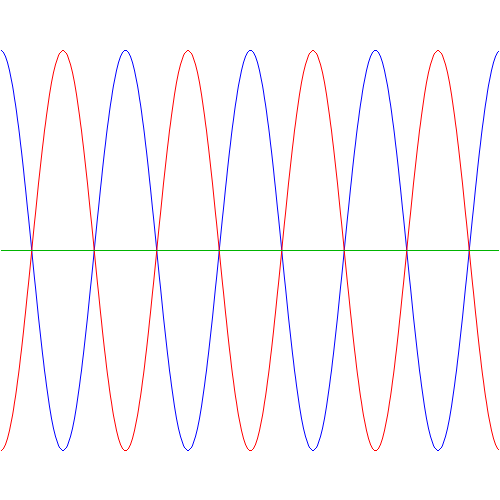
Again… Funny, isn’t it? So… What to make of this? Frankly, I don’t know. But one last graph makes for an interesting observation: if the angular frequency of f(θ) takes on larger and larger values, the Bose-Einstein and Fermi-Dirac probability density functions also start oscillating wildly. For example, the graphs below are based on a f(θ) function equal to f(θ) = cos(25·θ) + isin(25·θ). The explosion of color hurts the eye, doesn’t it? 🙂 But, apart from that, do you now see why physicists say that, at high frequencies, the interference pattern gets smeared out? Indeed, if we move the detector just a little bit (i.e. we change the angle θ just a little bit) in the example below, we hit a maximum instead of a minimum, and vice versa. In short, the granularity may be such that we can only measure that green line, in which case we’d think we’re dealing with Maxwell-Boltzmann statistics, while the underlying reality may be different.
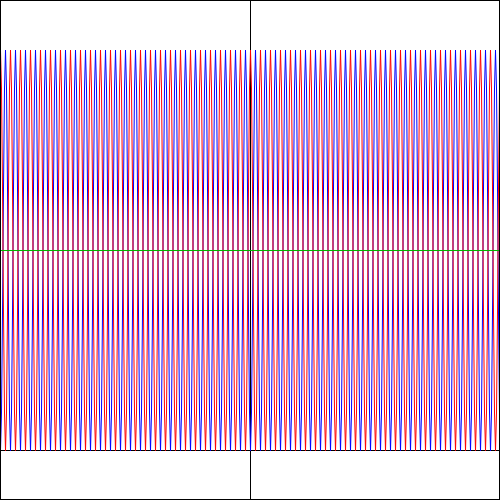
That explains another quote in Feynman’s famous introduction to quantum mechanics (Lectures, Vol. III, Chapter 1): “If the motion of all matter—as well as electrons—must be described in terms of waves, what about the bullets in our first experiment? Why didn’t we see an interference pattern there? It turns out that for the bullets the wavelengths were so tiny that the interference patterns became very fine. So fine, in fact, that with any detector of finite size one could not distinguish the separate maxima and minima. What we saw was only a kind of average, which is the classical curve. In the Figure below, we have tried to indicate schematically what happens with large-scale objects. Part (a) of the figure shows the probability distribution one might predict for bullets, using quantum mechanics. The rapid wiggles are supposed to represent the interference pattern one gets for waves of very short wavelength. Any physical detector, however, straddles several wiggles of the probability curve, so that the measurements show the smooth curve drawn in part (b) of the figure.”
But that should really conclude this post. It has become way too long already. One final remark, though: the ‘smearing out’ effect also explains why those three equations for 〈Ni〉 sometimes do amount to more or less the same thing: the Bose-Einstein and Fermi-Dirac formulas may approximate the Maxwell-Boltzmann equation. In that case, the ±1 term in the denominator does not make much of a difference. As we said a couple of times already, it all depends on scale. 🙂
Concluding remarks
1. The best I can do in terms of interpreting the above, is to tell myself that we cannot fully ‘fix’ the functional form of the wave function for the second or ‘other’ way the event can happen if we’re ‘fixing’ the functional form for the first of the two possibilities. We have to allow for a phase shift eiδ indeed, which incorporates all kinds of considerations of uncertainty in regard to both time and position and, hence, in regard to energy and momentum also (using both the ΔEΔt = ħ/2 and ΔxΔp = ħ/2 expressions)–I assume (but that’s just a gut instinct). And then the symmetry of the situation then implies eiδ can only take on one of two possible values: –1 or +1 which, in turn, implies that δ is equal to 0 or π.
2. For those who’d think I am basically doing nothing but re-write a chapter out of Feynman’s Lectures, I’d refute that. One point to note is that Feynman doesn’t seem to accept that we should introduce a phase factor in the analysis for non-identical particles as well. To be specific: just switching the detectors (instead of the particles) also implies that one should allow for the mathematical possibility of the phase of that f function being shifted by some random factor δ. The only difference with the quantum-mechanical analysis (i.e. the analysis for identical particles) is that the phase factor doesn’t make a difference as to the final result, because we’re not adding amplitudes but their absolute squares and, hence, a phase shift doesn’t matter.
3. I think all of the reasoning above makes not only for a very fine but also a very beautiful theoretical argument, even I feel like I don’t fully ‘understand’ it, in an intuitive way that is. I hope this post has made you think. Isn’t it wonderful to see that the theoretical or mathematical possibilities of the model actually correspond to realities, both in the classical as well as in the quantum-mechanical world? In fact, I can imagine that most physicists and mathematicians would shrug this whole reflection off like… Well… Like: “Of course! It’s obvious, isn’t it?” I don’t think it’s obvious. I think it’s deep. I would even qualify it as mysterious, and surely as beautiful. 🙂
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 20, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:

Hello, I was browsing through physics tagged post’s and found this one refreshing. It is presented well and exposes some of the funkiness behind quantum mechanics. I wanted to suggest reading about Berry’s Phase if you haven’t already, it continues the story of strange phases popping up in physics.
Hi Nathan ! Thanks for your comment. So nice of you. And encouraging. Frankly, an indication like this – that the questions I have or ask make sense to someone out there – encourages me to probe further. I’ll have a look at Berry’s phase. 🙂