
Pre-script (dated 26 June 2020): This post got mutilated by the removal of some material by the dark force. You should be able to follow the main story line, however. If anything, the lack of illustrations might actually help you to think things through for yourself. In any case, we now have different views on these concepts as part of our realist interpretation of quantum mechanics, so we recommend you read our recent papers instead of these old blog posts.
Original post:
You must be despairing by now. More theory? Haven’t we had enough? Relax. We’re almost there. The next post is going to generalize our results for n-state systems. However, before we do that, we need one more building block, and that’s this one. So… Well… Let’s go for it. It’s a bit long but, hopefully, interesting enough—so you don’t fall asleep before the end. 🙂 Let’s first review the concept of an operator itself.
The concept of an operator
You’ll remember Feynman‘s ‘Great Law of Quantum Mechanics’:
| = ∑ | i 〉〈 i | over all base states i.
We also talked of all kinds of apparatuses: a Stern-Gerlach spin filter, a state selector for a maser, a resonant cavity or—quite simply—just time passing by. From a quantum-mechanical point of view, we think of this as particles going into the apparatus in some state φ, and coming out of it in some other state χ. We wrote the amplitude for that as 〈 χ | A | φ 〉. [Remember the right-to-left reading, like Arab or Hebrew script.] Then we applied our ‘Great Law’ to that 〈 χ | A | φ 〉 expression – twice, actually – to get the following expression:

We’re just ‘unpacking’ the φ and χ states here, as we can only describe those states in terms of base states, which we denote as i and j here. That’s all. If we’d add another apparatus in series, we’d get:
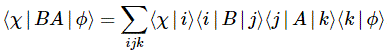
We just put the | bar between B and A and apply the same trick. The | bar is really like a factor 1 in multiplication—in the sense that we can insert it anywhere: a×b = a×1×b = 1×a×b = a×b×1 = 1×a×1×b×1 = 1×a×b×1 etc. Anywhere? Hmm… It’s not quite the same, but I’ll let you check out the differences. 🙂 The point is that, from a mathematical point of view, we can fully describe the apparatus A, or the combined apparatus BA, in terms of those 〈 i | A | j 〉 or 〈 i | BA | j 〉 amplitudes. Depending on the number of base states, we’d have a three-by-three, or a two-by-two, or, more generally, an n-by-n matrix, i.e. a square matrix of order n. For example, there are 3×3 = 9 amplitudes if we have three possible states, for example—and, equally obviously, 2×2 = 4 amplitudes for the example involving spin-1/2 particles. [If you think things are way too complicated,… Well… At least we’ve got square matrices here—not n-by-m matrices.] We simply called such matrix the matrix of amplitudes, and we usually denoted it by A. However, sometimes we’d also denote it by Aij, or by [Aij], depending on our mood. 🙂 The preferred notation was A, however, so as to avoid confusion with the matrix elements, which we’d write as Aij.
The Hamiltonian matrix – which, very roughly speaking, is like the quantum-mechanical equivalent of the dp/dt term of Newton’s Law of Motion: F = dp/dt = m·dv/dt = m·a – is a matrix of amplitudes as well, and we’ll come back to it in a minute. Let’s first continue our story on operators here. The idea of an operator comes up when we’re creative again, and when we drop the 〈 χ | state from the 〈 χ | A | φ〉 expression, so we write:
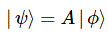
So now we think of the particle entering the ‘apparatus’ A in the state ϕ and coming out of A in some state ψ (‘psi’). But our psi is a ket, i.e. some initial state. That’s why we write it as | ψ 〉. It doesn’t mean anything until we combine with some bra, like a base state 〈 i |, or with a final state, which we’d denote by 〈 χ | or some other Greek letter between a 〈 and a | symbol. So then we get 〈 χ | ψ 〉 = 〈 χ | A | φ〉 or 〈 i | ψ 〉 = 〈 i | A | φ 〉. So then we’re ‘unpacking’ our bar once more. Let me be explicit here: it’s kinda weird, but if you’re going to study quantum math, you’ll need to accept that, when discussing the state of a system or a particle, like ψ or φ, it does make a difference if they’re initial or final states. To be precise, the final 〈 χ | or 〈 φ | states are equal to the conjugate transpose of the initial | χ 〉 or | φ 〉 states, so we write: 〈 χ | = | χ 〉† or 〈 φ | = | φ 〉†. I’ll come back to that, because it’s kind of counter-intuitive: a state should be a state, no? Well… No. Not from a quantum-math point of view at least. 😦 But back to our operator. Feynman defines an operator in the following rather intuitive way:
The symbol A is neither an amplitude, nor a vector; it is a new kind of thing called an operator. It is something which “operates on” some state | φ 〉 to produce some new state | ψ 〉.”
But… Well… Be careful! What’s a state? As I mentioned, | ψ 〉 is not the same as 〈 ψ |. We’re talking an initial state | ψ 〉 here, not 〈 ψ |. That’s why we need to ‘unpack’ the operator to see what it does: we have to combine it with some final state that we’re interested in, or a base state. Then—and only then—we get a proper amplitude, i.e. some complex number – or some complex function – that we can work with. To be precise, we then get the amplitude to be in that final state, or in that base state. In practical terms, that means our operator, or our apparatus, doesn’t mean very much as long as we don’t measure what comes out—and measuring something implies we have to choose some set of base states, i.e. a representation, which allows us to describe the final state, which we denoted as 〈 χ | above.
Let’s wrap this up by being clear on the notation once again. We’ll write: Aij = 〈 i | A | j 〉, or Uij = 〈 i | U | j 〉, or Hij = 〈 i | H | j 〉. In other words, we’ll really be consistent now with those subscripts: if they are there, we’re talking a coefficient, or a matrix element. If they’re not there, we’re talking the matrix itself, i.e. A, U or H. Now, to give you a sort of feeling for how that works in terms of the matrix equations that we’ll inevitably have to deal with, let me just jot one of them down here:

The Di* numbers are the ‘coordinates’ of the (final) 〈 χ | state in terms of the base states, which we denote as i = +, 0 or − here. So we have three states here. [That’s just to remind you that the two-state systems we’ve seen so far are pretty easy. We’ll soon be working with four-state systems—and then the sky is the limit. :-)] In fact, you’ll remember that those coordinates were the complex conjugate of the ‘coordinates’ of the initial | χ 〉 state, i.e. D+, D0, D−, so that 1-by-3 matrix above, i.e. the row vector 〈 χ | = [D+* D0* D−*], is the so-called conjugate transpose of the column vector | χ 〉 = [D+ D0 D−]T. [I can’t do columns with this WordPress editor, so I am just putting the T for transpose so as to make sure you understand | χ 〉 is a column vector.]
Now, you’ll wonder – if you don’t, you should 🙂 – how that Aij = 〈 i | A | j 〉, Uij = 〈 i | U | j 〉, or Hij = 〈 i | H | j 〉 notation works out in terms of matrices. It’s extremely simple really. If we have only two states (yes, back to simplicity), which we’ll also write as + and − (forget about the 0 state), then we can write Aij = 〈 i | A | j 〉 in matrix notation as:

Huh? Is is that simple? Yes. We can make things more complicated by involving a transformation matrix so we can write our base states in terms of another, different, set of base states but, in essence, this is what we are talking about here. Of course, you should absolutely not try to give a geometric interpretation to our [1 0] or [0 1] ‘coordinates’. If you do that, you get in trouble, because then you want to give the transformed base states the same geometric interpretation and… Well… It just doesn’t make sense. I gave an example of that in my post on the hydrogen molecule as a two-state system. Symmetries in quantum physics are not geometric… Well… Not in a physical sense, that is. As I explained in my previous post, describing spin-1/2 particles involves stuff like 720 degree symmetries and all that. So… Well… Just don’t! 🙂
Onwards!
The Hamiltonian as a matrix and as an operator
As mentioned above, our Hamiltonian is a matrix of amplitudes as well, and we can also write it as H, Hij, or [Hij] respectively, depending on our mood. 🙂 For some reason, Feynman often writes it as Hij, instead of H, which creates a lot of confusion because, in most contexts, Hij refers to the matrix elements, rather than the matrix itself. I guess Feynman likes to keep the subscripts, i.e ij or I,II, as they refer to the representation that was chosen. However, Hij should really refer to the matrix element, and then we can use H for the matrix itself. So let’s be consistent. As I’ve shown above, the Hij notation – and so I am talking the Hamiltonian coefficients here – is actually a shorthand for writing:
Hij = 〈 i | H | j 〉
So the Hamiltonian coefficient (Hij) connects two base states (i and j) through the Hamiltonian matrix (H). Connect? How? Our language in the previous posts, and some of Feynman’s language, may have suggested the Hamiltonian coefficients are amplitudes to go from state j to state i. However, that’s not the case. Or… Well… We need to qualify that statement. What does it mean? The i and j states are base states and, hence, 〈 i | j 〉 = δij, with δij = 1 if i = j and δij = 0 if i ≠ j. Hence, stating that the Hamiltonian coefficients are the amplitudes to go from one state to another is… Well… Let’s say that language is rather inaccurate. We need to include the element of time, so we need to think in terms of those amplitudes C1 and C2, or CI and CII, which are functions in time: Ci = Ci(t). Now, the Hamiltonian coefficients are obviously related to those amplitudes. Sure! That’s quite obvious from the fact they appear in those differential equations for C1 and C2, or CI and CII, i.e. the amplitude to be in state 1 or state 2, or state I or state II, respectively. But they’re not the same.
Let’s go back to the basics here. When we derived the Hamiltonian matrix as we presented Feynman’s brilliant differential analysis of it, we wrote the amplitude to go from one base state to another, as a function in time (or a function of time, I should say), as:
Uij = Uij(t + Δt, t) = 〈 i | U | j 〉 = 〈 i | U(t + Δt, t) | j 〉
Our ‘unpacking’ rules then allowed us to write something like this for t = t1 and t + Δt = t2 or – let me quickly circle back to that monster matrix notation above – for Δt = t2 − t1:
The key – as presented by Feynman – to go from those Uij amplitudes to the Hij amplitudes is to consider the following: if Δt goes to zero, nothing happens, so we wrote: Uij = 〈 i | U | j 〉 → 〈 i | j 〉 = δij for Δt → 0. We also assumed that, for small t, those Uij amplitudes should differ from δij (i.e. from 1 or 0) by amounts that are proportional to Δt. So we wrote:
Uij(t + Δt, t) = δij + ΔUij(t + Δt, t) = δij + Kij(t)·Δt ⇔ Uij(t + Δt, t) = δij − (i/ħ)·Hij(t)·Δt
There’s several things here. First, note the first-order linear approximation: it’s just like the general y(t + Δt) = y(t) + Δy = y(t) + (dy/dt)·Δt formula. So can we look at our Kij(t) function as being the time derivative of the Uij(t + Δt, t) function? The answer is, unambiguously, yes. Hence, −(i/ħ)·Hij(t) is the same time derivative. [Why? Because Kij(t) = −(i/ħ)·Hij(t).] Now, the time derivative of a function, i.e. dy/dt, is equal to Δy/Δt for Δt → 0 and, of course, we know that Δy = 0 for Δt → 0. We are now in a position to understand Feynman’s interpretation of the Hamiltonian coefficients:
The −(i/ħ)·Hij(t) = −(i/ħ)·〈 i | H | j 〉 factor is the amplitude that—under the physical conditions described by H—a state j will, during the time dt, “generate” the state i.
I know I shouldn’t make this post too long (I promised to write about the Pauli spin matrices, and I am not even halfway there) but I should note a funny thing there: in that Uij(t + Δt, t) = δij + ΔUij(t + Δt, t) = δij + Kij(t)·Δt = δij − (i/ħ)·Hij(t)·Δt formula, for Δt → 0, we go from real to complex numbers. I shouldn’t anticipate anything but… Well… We know that the Hij coefficients will (usually) represent some energy level, so they are real numbers. Therefore, − (i/ħ)·Hij(t) = Kij(t) is complex-valued, as we’d expect, because Uij(t + Δt, t) is, in general, complex-valued, and δij is just 0 or 1. I don’t have too much time to linger on this, but it should remind you of how one may mathematically ‘construct’ the complex exponential eis by using the linear approximation eiε = 1 + iε near s = 0 or, what amounts to the same, for small ε. My post on this shows how Feynman takes the magic out of Euler’s formula doing that – and I should re-visit it, because I feel the formula above, and that linear approximation formula for a complex exponential, go to the heart of the ‘mystery’, really. But… Well… No time. I have to move on.
Let me quickly make another small technical remark here. When Feynman talks about base states, he always writes them as a bra or a ket, just like any other state. So he talks about “base state | i 〉”, or “base state 〈 i |”. If you look it up, you’ll see he does the same in that quote: he writes | j 〉 and | i 〉, rather than j and i. In fact, strictly speaking, he should write 〈 i | instead of | i 〉. Frankly, I really prefer to just write “base state i”, or base state j”, without specifying if it’s a bra or a ket. A base state is a base state: 〈 i | and | i 〉 represent the same. Of course, it’s rather obvious that 〈 χ | and | χ 〉 are not the same. In fact, as I showed above, they’re each other’s complex conjugate, so 〈 χ |* = | χ 〉. To be precise, I should say: they’re each other’s conjugate transpose, because we’re talking row and column vectors respectively. Likewise, we can write: 〈 χ | φ 〉* = 〈 φ | χ 〉. For base states, this becomes 〈 i | j 〉* = 〈 j | i 〉. Now, 〈 i | and | j 〉 were matrices, really – row and column vectors, to be precise – so we can apply the following rule: the conjugate transpose of the product of two matrices is the product of the conjugate transpose of the same matrices, but with the order of the matrices reversed. So we have: (AB)* = B*A*. In this case: 〈 i | j 〉* = | j 〉*〈 i |*. Huh? Yes. Think about it. I should probably use the dagger notation for the conjugate transpose, rather than the simple * notation, but… Well… It works. The bottom line is: 〈 i | j 〉* = 〈 j | i 〉 = | j 〉*〈 i |* and, therefore, 〈 j | = | j 〉* and | i 〉 = 〈 i |*. Conversely, 〈 j | i 〉* = 〈 i | j 〉 = | i 〉*〈 j |* and, therefore, we also have 〈 j |* = | j 〉 and | i 〉* = 〈 i |. Now, we know the coefficients of these row and column vectors are either one or zero. In short, 〈 i | and | i 〉, or 〈 j | and | j 〉 are really one and the same ‘object’. The only reason why we would use the bra-ket notation is to indicate whether we’re using them in an initial condition, or in a final state. In the specific case that we’re dealing with here, it’s obvious that j is used in an initial condition, and i is a final condition.
We’re now ready to look at these differential equations once more, and try to truly understand them:
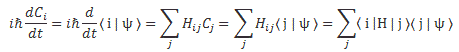
The summation over all base states j amounts to adding the contribution, so to speak, of all those base states j, during the infinitesimally small time interval dt, to the change in the amplitude (during the same infinitesimal time interval, of course) to be in state i. Does that make sense?
You’ll say: yes. Or maybe. Or maybe not. 🙂 And I know you’re impatient. We were supposed to talk about the Hamiltonian operator here. So what about that? Why this long story on the Hamiltonian coefficients? Well… Let’s take the next step. An operator is all about ‘abstracting away’, or ‘dropping terms’, as Feynman calls it—more down to the ground. 🙂 So let’s do that in two successive rounds, as shown below. First we drop the 〈 i |, because the equation holds for any i. Then we apply the grand | = ∑ | i 〉〈 i | rule—which is somewhat tricky, as it also gets rid of the summation. We then define the Hamiltonian operator as H, but we just put a little hat on top of it. That’s all.
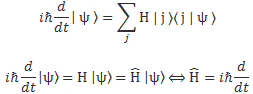
As this is all rather confusing, let me show what it means in terms of matrix algebra:
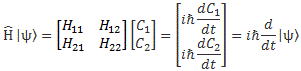
So… Frankly, it’s not all that difficult. It’s basically introducing a summary notation, which is what operators usually do. Note that the H = (i/ħ)·d/dt operator (sorry if I am not always putting the hat) is not just the d/dt with an extra division by ħ and a multiplication by the imaginary unit i. From a mathematical point of view, of course, that’s what it seems to be, and actually is. From a mathematical point of view, it’s just an n-by-n matrix, and so we can effectively apply it to some n-by-1 column vector to get another n-by-1 column vector.
But its meaning is much deeper: as Feynman puts it: the equation(s) above are the dynamical law of Nature—the law of motion for a quantum system. In a way, it’s like that invariant (1−v2)−1/2·d/dt operator that we introduced when discussing relativity, and things like the proper time and invariance under Lorentz transformation. That operator really did something. It ‘fixed’ things as we applied to the four-vectors in relativistic spacetime. So… Well… Think about it.
Before I move on – because, when everything is said and done, I promised to use the Pauli matrices as operators – I’ll just copy Feynman as he approaches the equations from another angle:
Of course, that’s the equation we started out with, before we started ‘abstracting away’:
So… Well… You can go through the motions once more. Onward!
The Pauli spin matrices as operators
If the Hamiltonian matrix can be used as an operator, then we can use the Pauli spin matrices as little operators too! Indeed, from my previous post, you’ll remember we can write the Hamiltonian in terms of the Pauli spin matrices:
Now, if we think of the Hamiltonian matrix as an operator, we can put a little hat everywhere, so we get:
It’s really as simple as that. Now, we get a little bit in trouble with the x, y and z subscripts as we’re going to want to write the matrix elements as σij, so we’ll just move them and write them as superscripts, so our matrix elements will be written as σxij = 〈 i | σx | j 〉, σyij = 〈 i | σy | j 〉 and σzij = 〈 i | σz | j 〉 respectively. Now, we introduced all kinds of properties of the Pauli matrices themselves, but let’s now look at the properties of these matrices as an operator. To do that, we’ll let them loose on the base states. We get the following:

[You can check this in Feynman, but it’s really very straightforward, so you should try to get this result yourself.] The next thing is to create even more operators by multiplying the operators two by two. We get stuff like:
σxσy|+〉 = σx(σy|+〉) = σx(i|−〉) = i·(σx|−〉) = i·|+〉
The thing to note here is that it’s business as usual: we can move factors like i out of the operators, as the operators work on the state vectors only. Oh… And sorry I am not putting the hat again. It’s the limitations of the WordPress editor here (I always need to ‘import’ my formulas from Word or some other editor, so I can’t put them in the text itself). On the other hand, Feynman himself seems to doubt the use of the hat symbol, as he writes: “It is best, when working with these things, not to keep track of whether a quantity like σ or H is an operator or a matrix. All the (matrix) equations are the same anyway.“
That makes it all rather tedious or, in fact, no! That makes it all quite easy, because our table with the properties of the sigma matrices is also valid for the sigma operators, so let’s just copy it, and then we’re done, so we can wrap up and do something else. 🙂
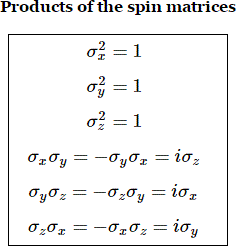
To conclude, let me answer your most pressing question at this very moment: what’s the use of this? Well… To a large extent, it’s a nice way of rather things. For example, let’s look at our equations for the ammonia molecule once more. But… Well… No. I’ll refer you to Feynman here, as he re-visits all the systems we’ve studied before, but now approaches them with our new operators and notations. Have fun with it! 🙂
Some content on this page was disabled on June 16, 2020 as a result of a DMCA takedown notice from The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 16, 2020 as a result of a DMCA takedown notice from The California Institute of Technology. You can learn more about the DMCA here:https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 16, 2020 as a result of a DMCA takedown notice from The California Institute of Technology. You can learn more about the DMCA here:https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
