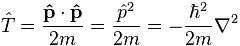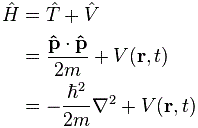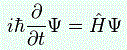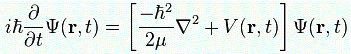It’s probably good to review the concepts we’ve learned so far. Let’s start with the foundation of all of our math, i.e. the concept of the state, or the state vector. [The difference between the two concepts is subtle but real. I’ll come back to it.]
State vectors and base states
We used Dirac’s bra-ket notation to denote a state vector, in general, as | ψ 〉. The obvious question is: what is this thing? We called it a vector because we use it like a vector: we multiply it with some number, and then add it to some other vector. So that’s just what you did in high school, when you learned about real vector spaces. In this regard, it is good to remind you of the definition of a vector space. To put it simply, it is is a collection of objects called vectors, which may be added together, and multiplied by numbers. So we have two things here: the ‘objects’, and the ‘numbers’. That’s why we’d say that we have some vector space over a field of numbers. [The term ‘field’ just refers to an algebraic structure, so we can add and multiply and what have you.] Of course, what it means to ‘add’ two ‘objects’, and what it means to ‘multiply’ an object with a number, depends on the type of objects and, unsurprisingly, the type of numbers.
Huh? The type of number?! A number is a number, no?
No, hombre, no! We’ve got natural numbers, rational numbers, real numbers, complex numbers—and you’ve probably heard of quaternions too – and, hence, ‘multiplying’ a ‘number’ with ‘something else’ can mean very different things. At the same time, the general idea is the general idea, so that’s the same, indeed. 🙂 When using real numbers and the kind of vectors you are used to (i.e. Euclidean vectors), then the multiplication amounts to a re-scaling of the vector, and so that’s why a real number is often referred to as a scalar. At the same time, anything that can be used to multiply a vector is often referred to as a scalar in math so… Well… Terminology is often quite confusing. In fact, I’ll give you some more examples of confusing terminology in a moment. But let’s first look at our ‘objects’ here, i.e. our ‘vectors’.
I did a post on Euclidean and non-Euclidean vector spaces two years ago, when I started this blog, but state vectors are obviously very different ‘objects’. They don’t resemble the vectors we’re used to. We’re used to so-called polar vectors, aka as real vectors, like the position vector (x or r), or the momentum vector (p = m·v), or the electric field vector (E). We are also familiar with the so-called pseudo-vectors, aka as axial vectors, like angular momentum (L = r×p), or the magnetic dipole moment. [Unlike what you might think, not all vector cross products yield a pseudo-vector. For example, the cross-product of a polar and an axial vector yields a polar vector.] But here we are talking some very different ‘object’. In math, we say that state vectors are elements in a Hilbert space. So a Hilbert space is a vector space but… Well… With special vectors. 🙂
The key to understanding why we’d refer to states as state vectors is the fact that, just like Euclidean vectors, we can uniquely specify any element in a Hilbert space with respect to a set of base states. So it’s really like using Cartesian coordinates in a two- or three-dimensional Euclidean space. The analogy is complete because, even in the absence of a geometrical interpretation, we’ll require those base states to be orthonormal. Let me be explicit on that by reminding you of your high-school classes on vector analysis: you’d choose a set of orthonormal base vectors e1, e2, and e3, and you’d write any vector A as:
A = (Ax, Ay, Az) = Ax·e1 + Ay·e2 + Az·e3 with ei·ej = 1 if i = j, and ei·ej = 0 if i ≠ j
The ei·ej = 1 if i = j and ei·ej = 0 if i ≠ j condition expresses the orthonormality condition: the base vectors need to be orthogonal unit vectors. We wrote it as ei·ej = δij using the Kronecker delta (δij = 1 if i = j and 0 if i ≠ j). Now, base states in quantum mechanics do not necessarily have a geometrical interpretation. Indeed, although one often can actually associate them with some position or direction in space, the condition of orthonormality applies in the mathematical sense of the word only. Denoting the base states by i = 1, 2,… – or by Roman numerals, like I and II – so as to distinguish them from the Greek ψ or φ symbols we use to denote state vectors in general, we write the orthonormality condition as follows:
〈 i | j 〉 = δij, with δij = δji is equal to 1 if i = j, and zero if i ≠ j
Now, you may grumble and say: that 〈 i | j 〉 bra-ket does not resemble the ei·ej product. Well… It does and it doesn’t. I’ll show why in a moment. First note how we uniquely specify state vectors in general in terms of a set of base states. For example, if we have two possible base states only, we’ll write:
| φ 〉 = | 1 〉 C1 + | 2 〉 C2
Or, if we chose some other set of base states | I 〉 and | II 〉, we’ll write:
| φ 〉 = | I 〉 CI + | II 〉 CII
You should note that the | 1 〉 C1 term in the | φ 〉 = | 1 〉 C1 + | 2 〉 C2 sum is really like the Ax·e1 product in the A = Ax·e1 + Ay·e2 + Az·e3 expression. In fact, you may actually write it as C1·| 1 〉, or just reverse the order and write C1| 1 〉. However, that’s not common practice and so I won’t do that, except occasionally. So you should look at | 1 〉 C1 as a product indeed: it’s the product of a base state and a complex number, so it’s really like m·v, or whatever other product of some scalar and some vector, except that we’ve got a complex scalar here. […] Yes, I know the term ‘complex scalar’ doesn’t make sense, but I hope you know what I mean. 🙂
More generally, we write:
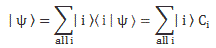
Writing our state vector | ψ 〉, | φ 〉 or | χ 〉 like this also defines these coefficients or coordinates Ci. Unlike our state vectors, or our base states, Ci is an actual number. It has to be, of course: it’s the complex number that makes sense of the whole expression. To be precise, Ci is an amplitude, or a wavefunction, i.e. a function depending on both space and time. In our previous posts, we limited the analysis to amplitudes varying in time only, and we’ll continue to do so for a while. However, at some point, you’ll get the full picture.
Now, what about the supposed similarity between the 〈 i | j〉 bra-ket and the ei·ej product? Let me invoke what Feynman, tongue-in-cheek as usual, refers to as the Great Law of Quantum Mechanics:
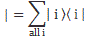
You get this by taking | ψ 〉 out of the | ψ 〉 = ∑| i 〉〈 i | ψ 〉 expression. And, no, don’t say: what nonsense! Because… Well… Dirac’s notation really is that simple and powerful! You just have to read it from right to left. There’s an order to the symbols, unlike what you’re used to in math, because you’re used to operations that are commutative. But I need to move on. The upshot is that we can specify our base states in terms of the base states too. For example, if we have only two base states, let’s say I and II, then we can write:
| I 〉 = ∑| i 〉〈 i | 1 〉 = 1·| I 〉 + 0·| II 〉 and | II 〉 = ∑| i 〉〈 i | II 〉 = 0·| 1 〉 + 0·| II 〉
We can write this using a matrix notation:
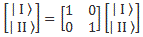 Now that is silly, you’ll say. What’s the use of this? It doesn’t tell us anything new, and it also does not show us why we should think of the 〈 i | j 〉 bra-ket and the ei·ej product as being similar! Well… Yes and no. Let me show you something else. Let’s assume we’ve got some state χ and φ, which we specify in terms of our chosen set of base states as | χ 〉 = ∑ | i 〉 Di and | φ 〉 = ∑ | i 〉 Ci respectively. Now, from our post on quantum math, you’ll remember that 〈 χ | i 〉 and 〈 i | χ 〉 are each other’s complex conjugates, so we know that 〈 χ | i 〉 = 〈 i | χ 〉* = Di*. So if we have all Ci = 〈 i | φ 〉 and all Di = 〈 i | χ 〉, i.e. the ‘components’ of both states in terms of our base states, then we can calculate 〈 χ | φ 〉 – i.e. the amplitude to go from some state φ to some state χ as:
Now that is silly, you’ll say. What’s the use of this? It doesn’t tell us anything new, and it also does not show us why we should think of the 〈 i | j 〉 bra-ket and the ei·ej product as being similar! Well… Yes and no. Let me show you something else. Let’s assume we’ve got some state χ and φ, which we specify in terms of our chosen set of base states as | χ 〉 = ∑ | i 〉 Di and | φ 〉 = ∑ | i 〉 Ci respectively. Now, from our post on quantum math, you’ll remember that 〈 χ | i 〉 and 〈 i | χ 〉 are each other’s complex conjugates, so we know that 〈 χ | i 〉 = 〈 i | χ 〉* = Di*. So if we have all Ci = 〈 i | φ 〉 and all Di = 〈 i | χ 〉, i.e. the ‘components’ of both states in terms of our base states, then we can calculate 〈 χ | φ 〉 – i.e. the amplitude to go from some state φ to some state χ as:
〈 χ | φ 〉 = ∑〈 χ | i 〉〈 i | φ 〉 =∑ Di*Ci = ∑ Di*〈 i | φ 〉
We can now scrap | φ 〉 in this expression – yes, it’s the power of Dirac’s notation once more! – so we get:
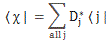
Now, we can re-write this using a matrix notation:
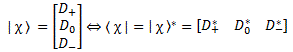
[I assumed that we have three base states now, so as to make the example somewhat less obvious. Please note we can never leave one of the base states out when specifying a state vector, so it’s not like the previous example was not complete. I’ll switch from two-state to three-state systems and back again all the time, so as to show the analysis is pretty general. To visualize things, think of the ammonia molecule as an example of a two-state system versus the spin of a proton or an electron as a three-state system, respectively. OK. Let’s get back to the lesson.]
You’ll say: so what? Well… Look at this:
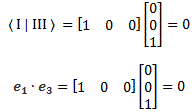
I just combined the notations for 〈 I | and | III 〉. Can you now see the similarity between the the 〈 i | j〉 bra-ket and the ei·ej product? It really is the same: you just need to respect the subtleties in regard to writing the 〈 i | and | j 〉 vector, or the ei and ej vectors, as a row vector or a column vector respectively.
It doesn’t stop here, of course. When learning about vectors in high school, we also learned that we could go from one set of base vectors to another by a transformation, such as, for example, a rotation, or a translation. We showed how a rotation worked in one of our post on two-state systems, where we wrote:
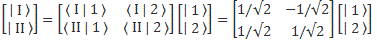
So we’ve got that transformation matrix, which, of course, isn’t random. To be precise, we got the matrix equation above (note that we’re back to two states only, so as to simplify) because we defined the CI and CII coefficients in the | φ 〉 = | I 〉 CI + | II 〉 CII = | 1 〉 C1 + | 2 〉 C2 expression as follows:
- CI = 〈 I | ψ 〉 = (1/√2)·(C1 − C2)
- CII = 〈 II | ψ 〉 = (1/√2)·(C1 + C2)
The (1/√2) factor is there because of the normalization condition, and the two-by-two matrix equals the transformation matrix for a rotation of a state filtering apparatus about the y-axis, over an angle equal to (minus) 90 degrees, which we wrote as:

I promised I’d say something more about confusing terminology so let me do that here. We call a set of base states a ‘representation‘, and writing a state vector in terms of a set of base states is often referred to as a ‘projection‘ of that state into the base set. Again, we can see it’s sort of a mathematical projection, rather than a geometrical one. But it makes sense. In any case, that’s enough on state vectors and base states.
Let me wrap it up by inserting one more matrix equation, which you should be able to reconstruct yourself:
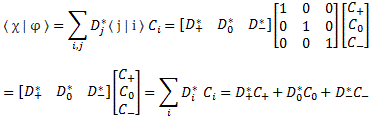
The only thing we’re doing here is to substitute 〈 χ | and | φ 〉 for ∑ Dj*〈 j | and ∑ | i 〉 Ci respectively. All the rest follows. Finally, I promised I’d tell you the difference between a state and a state vector. It’s subtle and, in practice, the two concepts refer to the same. However, we write a state as a state, like ψ or, if it’s a base state, like I, or ‘up’, or whatever. When we say a state vector, then we think of a set of numbers. It may be a row vector, like the 〈 χ | row vector with the Di* coefficients, or a column vector, like the | φ 〉 column vector with the Di* coefficients. But so if we say vector, then we think of a one-dimensional array of numbers, while the state itself is… Well… The state. So that’s some reality in physics. So you might define the state vector as the set of numbers that describes the state. While the difference is subtle, it’s important. It’s also important to note that the 〈 χ | and | χ 〉 state vectors are different too. The former appears as the final state in an amplitude, while the latter describes the starting condition. The former is referred to as a bra in the 〈 χ | φ 〉 bra-ket, while the latter is a ket in the 〈 φ | χ 〉 = 〈 χ | φ 〉* amplitude. 〈 χ | is a row vector equal to ∑ Di*〈 i |, while | χ 〉 = ∑ Di | χ 〉. So it’s quite different. More in general, we’d define bras and kets as row and column vectors respectively, so we write:
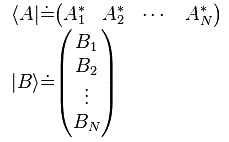
That makes it clear that a bra next to a ket is to be understood as a matrix multiplication. From what I wrote, it is also obvious that the conjugate transpose (which is also known as the Hermitian conjugate) of a bra is the corresponding ket and vice versa, so we write:
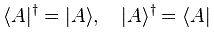
Let me formally define the conjugate or Hermitian transpose here: the conjugate transpose of an m-by-n matrix A with complex elements is the n-by-m matrix A† obtained from A by taking the transpose (so we write the rows as columns and vice versa) and then taking the complex conjugate of each element (i.e. we switch the sign of the imaginary part of the complex number). A† is read as ‘A dagger’, but mathematicians will usually denote it by A*. In fact, there are a lot of equivalent notations, as we can write:
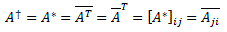
OK. That’s it on this.
One more thing, perhaps. We’ll often have states, or base states, that make sense, in a physical sense, that is. But it’s not always the case: we’ll sometimes use base states that may not represent some situation we’re likely to encounter, but that make sense mathematically. We gave the example of the ‘mathematical’ | I 〉 and | II 〉 base states, versus the ‘physical’ | 1 〉 and | 2 〉 base states, in our post on the ammonia molecule, so I won’t say more about this here. Do keep it in mind though. Sometimes it may feel like nothing makes sense, physically, but it usually does mathematically and, therefore, all usually comes out alright in the end. 🙂 To be precise, what we did there, was to choose base states with a unambiguous, i.e. a definite, energy level. That made our calculations much easier, and the end result was the same, indeed!
So… Well… I’ll let this sink in, and move on to the next topic.
The Hamiltonian operator
In my post on the post on the Hamiltonian, I explained that those Ci and Di coefficients are usually a function of time, and how they can be determined. To be precise, they’re determined by a set of differential equations (i.e. equations involving a function and the derivative of that function) which we wrote as:

If we have two base states only, then this set of equations can be written as:
Two equations and two functions – C1 = C1(t) and C2 = C2(t) – so we should be able to solve this thing, right? Well… No. We don’t know those Hij coefficients. As I explained in that post, they also evolve in time, so we should write them as Hij(t) instead of Hij tout court, and so it messes the whole thing up. We have two equations and six functions really. Of course, there’s always a way out, but I won’t dwell on that here—not now at least. What I want to do here is look at the Hamiltonian as an operator.
We introduced operators – but not very rigorously – when explaining the Hamiltonian. We did so by ‘expanding’ our 〈 χ | φ 〉 amplitude as follows. We’d say the amplitude to find a ‘thing’ – like a particle, for example, or some system, of particles or other things – in some state χ at the time t = t2, when it was in some state φ state at the time t = t1 was equal to:
Now, a formula like this only makes sense because we’re ‘abstracting away’ from the base states, which we need to describe any state. Hence, to actually describe what’s going on, we have to choose some representation and expand this expression as follows:
That looks pretty monstrous, so we should write it all out. Using the matrix notation I introduced above, we can do that – let’s take a practical example with three base states once again – as follows:
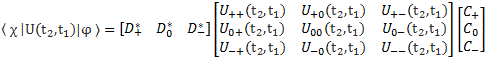
Now, this still looks pretty monstrous, but just think of it. We’re just applying that ‘Great Law of Quantum Physics’ here, i.e. | = ∑ | i 〉〈 i | over all base states i. To be precise, we apply it to an 〈 χ | A | φ 〉 expression, and we do so twice, so we get:
Nothing more, nothing less. 🙂 Now, the idea of an operator is the result of being creative: we just drop the 〈 χ | state from the expression above to write:
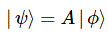
Yes. I know. That’s a lot to swallow, but you’ll see it makes sense because of the Great Law of Quantum Mechanics:
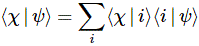
Just think about it and continue reading when you’re ready. 🙂 The upshot is: we now think of the particle entering some ‘apparatus’ A in the state ϕ and coming out of A in some state ψ or, looking at A as an operator, we can generalize this. As Feynman puts it:
“The symbol A is neither an amplitude, nor a vector; it is a new kind of thing called an operator. It is something which “operates on” a state to produce a new state.”
Back to our Hamiltonian. Let’s go through the same process of ‘abstraction’. Let’s first re-write that ‘Hamiltonian equation’ as follows:
The Hij(t) are amplitudes indeed, and we can represent them in a 〈 i | Hij(t) | j 〉 matrix indeed! Now let’s take the first step in our ‘abstraction process’: let’s scrap the 〈 i | bit. We get:
We can, of course, also abstract away from the | j 〉 bit, so we get:
![]()
Look at this! The right-hand side of this expression is exactly the same as that A | χ 〉 format we presented when introducing the concept of an operator. [In fact, when I say you should ‘abstract away’ from the | j 〉 bit, then you should think of the ‘Great Law’ and that matrix notation above.] So H is an operator and, therefore, it’s something which operates on a state to produce a new state.
OK. Clear enough. But what’s that ‘state’ on the left-hand side? I’ll just paraphrase Feynman here, who says we should think of it as follows: “The time derivative of the state vector |ψ〉 times iℏ is equal to what you get by (1) operating with the Hamiltonian operator H on each base state, (2) multiplying by the amplitude that ψ is in the state j (i.e. 〈j|ψ〉), and (1) summing over all j.” Alternatively, you can also say: “The time derivative, times iħ, of a state |ψ〉 is equal to what you get if you operate on it with the Hamiltonian.” Of course, that’s true for any state, so we can ‘abstract away’ the |ψ〉 bit too and, putting a little hat (^) over the operator to remind ourselves that it’s an operator (rather than just any matrix), we get the Hamiltonian operator equation:
![]()
Now, that’s all nice and great, but the key question, of course, is: what can you do with this? Well… It turns out his Hamiltonian operators is useful to calculate lots of stuff. In the first place, of course, it’s a useful operator in the context of those differential equations describing the dynamics of a quantum-mechanical system. When everything is said and done, those equations are the equivalent, in quantum physics, of the law of motion in classical physics. [And I am not joking here.]
In addition, the Hamiltonian operator also has other uses. The one I should really mention here is that you can calculate the average or expected value (EV[X]) of the energy of a state ψ (i.e. any state, really) by first operating on | ψ 〉 with the Hamiltonian, and then multiplying 〈 ψ | with the result. That sounds a bit complicated, but you’ll understand it when seeing the mathematical expression, which we can write as:
![]()
The formula is pretty straightforward. [If you don’t think so, then just write it all out using the matrix notation.] But you may wonder how it works exactly… Well… Sorry. I don’t want to copy all of Feynman here, so I’ll refer you to him on this. In fact, the proof of this formula is actually very straightforward, and so you should be able to get through it with the math you got here. You may even understand Feynman’s illustration of it for the ‘special case’ when base states are, indeed, those mathematically convenient base states with definite energy levels.
Have fun with it! 🙂
Post scriptum on Hilbert spaces:
As mentioned above, our state vectors are actually functions. To be specific, they are wavefunctions, i.e. periodic functions, evolving in space and time, so we usually write them as ψ = ψ(x, t). Our ‘Hilbert space’, i.e. our collection of state vectors, is, therefore, often referred to as a function space. So it’s a set of functions. At the same time, it is a vector space too, because we have those addition and multiplication operations, so our function space has the algebraic structure of a vector space. As you can imagine, there are some mathematical conditions for a space or a set of objects to ‘qualify’ as a Hilbert space, and the epithet itself comes with a lot of interesting properties. One of them is completeness, which is a property that allows us to jot down those differential equations that describe the dynamics of a quantum-mechanical system. However, as you can find whatever you’d need or want to know about those mathematical properties on the Web, I won’t get into it. The important thing here is to understand the concept of a Hilbert space intuitively. I hope this post has helped you in that regard, at least. 🙂
Some content on this page was disabled on June 16, 2020 as a result of a DMCA takedown notice from The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 16, 2020 as a result of a DMCA takedown notice from The California Institute of Technology. You can learn more about the DMCA here:https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 16, 2020 as a result of a DMCA takedown notice from The California Institute of Technology. You can learn more about the DMCA here:https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 16, 2020 as a result of a DMCA takedown notice from The California Institute of Technology. You can learn more about the DMCA here:https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 16, 2020 as a result of a DMCA takedown notice from The California Institute of Technology. You can learn more about the DMCA here:https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 16, 2020 as a result of a DMCA takedown notice from The California Institute of Technology. You can learn more about the DMCA here:https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 16, 2020 as a result of a DMCA takedown notice from The California Institute of Technology. You can learn more about the DMCA here:https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here: