
Pre-script (dated 26 June 2020): This post has become less relevant because my views on all things quantum-mechanical have evolved significantly as a result of my progression towards a more complete realist (classical) interpretation of quantum physics. In addition, some of the material was removed by a dark force. Hence, we recommend you read our recent papers. I keep blog posts like these mainly because I want to keep track of where I came from. I might review them one day, but I currently don’t have the time or energy for it. 🙂
Original post:
It is said that, when Ptolemy asked Euclid to quickly explain him geometry, Euclid told the King that there was no ‘Royal Road’ to it, by which he meant it’s just difficult and takes a lot of time to understand.
Physicists will tell you the same about quantum physics. So, I know that, at this point, I should just study Feynman’s third Lectures Volume and shut up for a while. However, before I get lost while playing with state vectors, S-matrices, eigenfunctions, eigenvalues and what have you, I’ll try that Royal Road anyway, building on my previous digression on Hamiltonian mechanics.
So… What was that about? Well… If you understood anything from my previous post, it should be that both the Lagrangian and Hamiltonian function use the equations for kinetic and potential energy to derive the equations of motion for a system. The key difference between the Lagrangian and Hamiltonian approach was that the Lagrangian approach yields one differential equation–which had to be solved to yield a functional form for x as a function of time, while the Hamiltonian approach yielded two differential equations–which had to be solved to yield a functional form for both position (x) and momentum (p). In other words, Lagrangian mechanics is a model that focuses on the position variable(s) only, while, in Hamiltonian mechanics, we also keep track of the momentum variable(s). Let me briefly explain the procedure again, so we’re clear on it:
1. We write down a function referred to as the Lagrangian function. The function is L = T – V with T and V the kinetic and potential energy respectively. T has to be expressed as a function of velocity (v) and V has to be expressed as a function of position (x). You’ll say: of course! However, it is an important point to note, otherwise the following step doesn’t make sense. So we take the equations for kinetic and potential energy and combine them to form a function L = L(x, v).
2. We then calculate the so-called Lagrangian equation, in which we use that function L. To be precise: what we have to do is calculate its partial derivatives and insert these in the following equation:

It should be obvious now why I stressed we should write L as a function of velocity and position, i.e. as L = L(x, v). Otherwise those partial derivatives don’t make sense. As to where this equation comes from, don’t worry about it: I did not explain why this works. I didn’t do that here, and I also didn’t do it in my previous post. What we’re doing here is just explaining how it goes, not why.
3. If we’ve done everything right, we should get a second-order differential equation which, as mentioned above, we should then solve for x(t). That’s what ‘solving’ a differential equation is about: find a functional form that satisfies the equation.
Let’s now look at the Hamiltonian approach.
1. We write down a function referred to as the Hamiltonian function. It looks similar to the Lagrangian, except that we sum kinetic and potential energy, and that T has to be expressed as a function of the momentum p. So we have a function H = T + V = H(x, p).
2. We then calculate the so-called Hamiltonian equations, which is a set of two equations, rather than just one equation. [We have two for the one-dimensional situation that we are modeling here: it’s a different story (i.e. we will have more equations) if we’d have more degrees of freedom of course.] It’s the same as in the Lagrangian approach: it’s just a matter of calculating partial derivatives, and insert them in the equations below. Again, note that I am not explaining why this Hamiltonian hocus-pocus actually works. I am just saying how it works.

3. If we’ve done everything right, we should get two first-order differential equations which we should then solve for x(t) and p(t). Now, solving a set of equations may or may not be easy, depending on your point of view. If you wonder how it’s done, there’s excellent stuff on the Web that will show you how (such as, for instance, Paul’s Online Math Notes).
Now, I mentioned in my previous post that the Hamiltonian approach to modeling mechanics is very similar to the approach that’s used in quantum mechanics and that it’s therefore the preferred approach in physics. I also mentioned that, in classical physics, position and momentum are also conjugate variables, and I also showed how we can calculate the momentum as a conjugate variable from the Lagrangian: p = ∂L/∂v. However, I did not dwell on what conjugate variables actually are in classical mechanics. I won’t do that here either. Just accept that conjugate variables, in classical mechanics, are also defined as pairs of variables. They’re not related through some uncertainty relation, like in quantum physics, but they’re related because they can both be obtained as the derivatives of a function which I haven’t introduced as yet. That function is referred to as the action, but… Well… Let’s resist the temptation to digress any further here. If you really want to know what action is–in physics, that is… 🙂 Well… Google it, I’d say. What you should take home from this digression is that position and momentum are also conjugate variables in classical mechanics.
Let’s now move on to quantum mechanics. You’ll see that the ‘similarity’ in approach is… Well… Quite relative, I’d say. 🙂
Position and momentum in quantum mechanics
As you know by now (I wrote at least a dozen posts on this), the concept of position and momentum in quantum mechanics is very different from that in classical physics: we do not have x(t) and p(t) functions which give a unique, precise and unambiguous value for x and p when we assign a value to the time variable and plug it in. No. What we have in quantum physics is some weird wave function, denoted by the Greek letters φ (phi) or ψ (psi) or, using Greek capitals, Φ and Ψ. To be more specific, the psi usually denotes the wave function in the so-called position space (so we write ψ = ψ(x)), and the phi will usually denote the wave function in the so-called momentum space (so we write φ = φ(p)). That sounds more complicated than it is, obviously, but I just wanted to respect terminology here. Finally, note that the ψ(x) and φ(p) wave functions are related through the Uncertainty Principle: they’re conjugate variables, and we have this ΔxΔp = ħ/2 equation, in which the Δ is some standard deviation from some mean value. I should not go into more detail here: you know that by now, don’t you?
While the argument of these functions is some real number, the wave functions themselves are complex-valued, so they have a real and complex amplitude. I’ve also illustrated that a couple of times already but, just to make sure, take a look at the animation below, so you know what we are sort of talking about:
- The A and B situations represent a classical oscillator: we know exactly where the red ball is at any point in time.
- The C to H situations give us a complex-valued amplitude, with the blue oscillation as the real part, and the pink oscillation as the imaginary part.
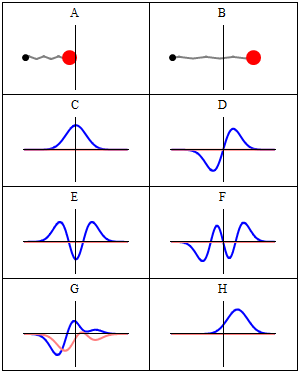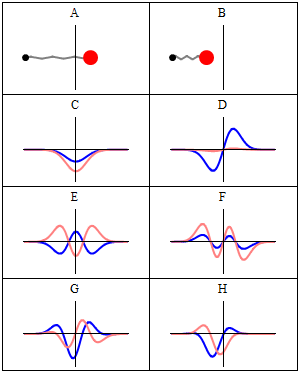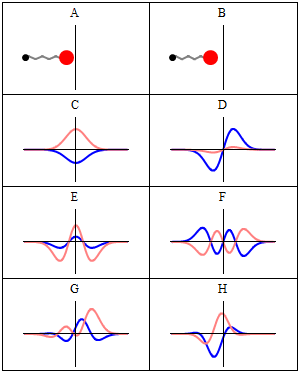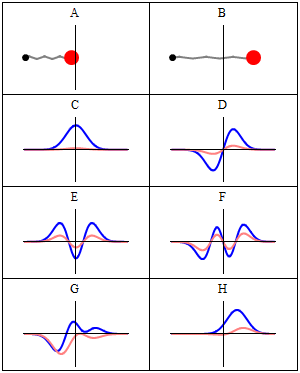 So we have such wave function both for x and p. Note that the animation above suggests we’re only looking at the wave function for x but–trust me–we have a similar one for p, and they’re related indeed. [To see how exactly, I’d advise you to go through the proof of the so-called Kennard inequality.] So… What do we do with that?
So we have such wave function both for x and p. Note that the animation above suggests we’re only looking at the wave function for x but–trust me–we have a similar one for p, and they’re related indeed. [To see how exactly, I’d advise you to go through the proof of the so-called Kennard inequality.] So… What do we do with that?
The position and momentum operators
When we want to know where a particle actually is, or what its momentum is, we need to do something with this wave function ψ or φ. Let’s focus on the position variable first. While the wave function itself is said to have ‘no physical interpretation’ (frankly, I don’t know what that means: I’d think everything has some kind of interpretation (and what’s physical and non-physical?), but let’s not get lost in philosophy here), we know that the square of the absolute value of the probability amplitude yields a probability density. So |ψ(x)|2 gives us a probability density function or, to put it simply, the probability to find our ‘particle’ (or ‘wavicle’ if you want) at point x. Let’s now do something more sophisticated and write down the expected value of x, which is usually denoted by 〈x〉 (although that invites confusion with Dirac’s bra-ket notation, but don’t worry about it):
![]()
Don’t panic. It’s just an integral. Look at it. ψ* is just the complex conjugate (i.e. a – ib if ψ = a + ib) and you will (or should) remember that the product of a complex number with its (complex) conjugate gives us the square of its absolute value: ψ*ψ = |ψ(x)|2. What about that x? Can we just insert that there, in-between ψ* and ψ ? Good question. The answer is: yes, of course! That x is just some real number and we can put it anywhere. However, it’s still a good question because, while multiplication of complex numbers is commutative (hence, z1z2 = z2z1), the order of our operators – which we will introduce soon – can often not be changed without consequences, so it is something to note.
For the rest, that integral above is quite obvious and it should really not puzzle you: we just multiply a value with its probability of occurring and integrate over the whole domain to get an expected value 〈x〉. Nothing wrong here. Note that we get some real number. [You’ll say: of course! However, I always find it useful to check that when looking at those things mixing complex-valued functions with real-valued variables or arguments. A quick check on the dimensions of what we’re dealing helps greatly in understanding what we’re doing.]
So… You’ve surely heard about the position and momentum operators already. Is that, then, what it is? Doing some integral on some function to get an expected value? Well… No. But there’s a relation. However, let me first make a remark on notation, because that can be quite confusing. The position operator is usually written with a hat on top of the variable – like ẑ – but so I don’t find a hat with every letter with the editor tool for this blog and, hence, I’ll use a bold letter x and p to denote the operator. Don’t confuse it with me using a bold letter for vectors though ! Now, back to the story.
Let’s first give an example of an operator you’re already familiar with in order to understand what an operator actually is. To put it simply: an operator is an instruction to do something with a function. For example: ∂/∂t is an instruction to differentiate some function with regard to the variable t (which usually stands for time). The ∂/∂t operator is obviously referred to as a differentiation operator. When we put a function behind, e.g. f(x, t), we get ∂f(x, t)/∂t, which is just another function in x and t.
So we have the same here: x in itself is just an instruction: you need to put a function behind in order to get some result. So you’ll see it as xψ. In fact, it would be useful to use brackets probably, like x[ψ], especially because I can’t put those hats on the letters here, but I’ll stick to the usual notation, which does not use brackets.
Likewise, we have a momentum operator: p = –iħ∂/∂x. […] Let it sink in. [..]
What’s this? Don’t worry about it. I know: that looks like a very different animal than that x operator. I’ll explain later. Just note, for the moment, that the momentum operator (also) involves a (partial) derivative and, hence, we refer to it as a differential operator (as opposed to differentiation operator). The instruction p = –iħ∂/∂x basically means: differentiate the function with regard to x and multiply with iħ (i.e. the product of Planck’s constant and the imaginary unit i). Nothing wrong with that. Just calculate a derivative and multiply with a tiny imaginary (complex) number.
Now, back to the position operator x. As you can see, that’s a very simple operator–much simpler than the momentum operator in any case. The position operator applied to ψ yields, quite simply, the xψ(x) factor in the integrand above. So we just get a new function xψ(x) when we apply x to ψ, of which the values are simply the product of x and ψ(x). Hence, we write xψ = xψ.
Really? Is it that simple? Yes. For now at least. 🙂
Back to the momentum operator. Where does that come from? That story is not so simple. [Of course not. It can’t be. Just look at it.] Because we have to avoid talking about eigenvalues and all that, my approach to the explanation will be quite intuitive. [As for ‘my’ approach, let me note that it’s basically the approach as used in the Wikipedia article on it. :-)] Just stay with me for a while here.
Let’s assume ψ is given by ψ = ei(kx–ωt). So that’s a nice periodic function, albeit complex-valued. Now, we know that functional form doesn’t make all that much sense because it corresponds to the particle being everywhere, because the square of its absolute value is some constant. In fact, we know it doesn’t even respect the normalization condition: all probabilities have to add up to 1. However, that being said, we also know that we can superimpose an infinite number of such waves (all with different k and ω) to get a more localized wave train, and then re-normalize the result to make sure the normalization condition is met. Hence, let’s just go along with this idealized example and see where it leads.
We know the wave number k (i.e. its ‘frequency in space’, as it’s often described) is related to the momentum p through the de Broglie relation: p = ħk. [Again, you should think about a whole bunch of these waves and, hence, some spread in k corresponding to some spread in p, but just go along with the story for now and don’t try to make it even more complicated.] Now, if we differentiate with regard to x, and then substitute, we get ∂ψ/∂x = ∂ei(kx–ωt)/∂x = ikei(kx–ωt) = ikψ, or
![]()
So what is this? Well… On the left-hand side, we have the (partial) derivative of a complex-valued function (ψ) with regard to x. Now, that derivative is, more likely than not, also some complex-valued function. And if you don’t believe me, just look at the right-hand side of the equation, where we have that i and ψ. In fact, the equation just shows that, when we take that derivative, we get our original function ψ but multiplied by ip/ħ. Hey! We’ve got a differential equation here, don’t we? Yes. And the solution for it is… Well… The natural exponential. Of course! That should be no surprise because we started out with a natural exponential as functional form! So that’s not the point. What is the point, then? Well… If we bring that i/ħ factor to the other side, we get:
(–i/ħ)(∂ψ/∂x) = pψ
[If you’re confused about the –i, remember that i–1 = 1/i = –i.] So… We’ve got pψ on the right-hand side now. So… Well… That’s like xψ, isn’t it? Yes. 🙂 If we define the momentum operator as p = (–i/ħ)(∂/∂x), then we get pψ = pψ. So that’s the same thing as for the position operator. It’s just that p is… Well… A more complex operator, as it has that –i/ħ factor in it. And, yes, of course it also involves an instruction to differentiate, which also sets it apart from the position operator, which is just an instruction to multiply the function with its argument.
I am sure you’ll find this funny–perhaps even fishy–business. And, yes, I have the same questions: what does it all mean? I can’t answer that here. As for now, just accept that this position and momentum operator are what they are, and that I can’t do anything about that. But… I hear you sputter: what about their interpretation? Well… Sorry… I could say that the functions xψ and pψ are so-called linear maps but that is not likely to help you much in understanding what these operators really do. You – and I for sure 🙂 – will indeed have to go through that story of eigenvalues to a somewhat deeper understanding of what these operators actually are. That’s just how it is. As for now, I just have to move on. Sorry for letting you down here. 🙂
Energy operators
Now that we sort of ‘understand’ those position and momentum operators (or their mathematical form at least), it’s time to introduce the energy operators. Indeed, in quantum mechanics, we’ve also got an operator for (a) kinetic energy, and for (b) potential energy. These operators are also denoted with a hat above the T and V symbol. All quantum-mechanical operators are like that, it seems. However, because of the limitations of the editor tool here, I’ll also use a bold T and V respectively. Now, I am sure you’ve had enough of this operators, so let me just jot them down:
- V = V, so that’s just an instruction to multiply a function with V = V(x, t). That’s easy enough because that’s just like the position vector.
- As for T, that’s more complicated. It involves that momentum operator p, which was also more complicated, remember? Let me just give you the formula:
T = p·p/2m = p2/2m.
So we multiply the operator p with itself here. What does that mean? Well… Because the operator involves a derivative, it means we have to take the derivative twice and… No ! Well… Let me correct myself: yes and no. 🙂 That p·p product is, strictly speaking, a dot product between two vectors, and so it’s not just a matter of differentiating twice. Now that we are here, we may just as well extend the analysis a bit and assume that we also have a y and z coordinate, so we’ll have a position vector r = (x, y, z). [Note that r is a vector here, not an operator. !?! Oh… Well…] Extending the analysis to three (or more) dimensions means that we should replace the differentiation operator by the so-called gradient or del operator: ∇ = (∂/∂x, ∂/∂y, ∂/∂z). And now that dot product p·p will, among other things, yield another operator which you’re surely familiar with: the Laplacian. Let me remind you of it:

Hence, we can write the kinetic energy operator T as:
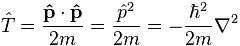
I quickly copied this formula from Wikipedia, which doesn’t have the limitation of the WordPress editor tool, and so you see it now the way you should see it, i.e. with the hat notation. 🙂
[…]
In case you’re despairing, hang on ! We’re almost there. 🙂 We can, indeed, now define the Hamiltonian operator that’s used in quantum mechanics. While the Hamiltonian function was the sum of the potential and kinetic energy functions in classical physics, in quantum mechanics we add the two energy operators. You’ll grumble and say: that’s not the same as adding energies. And you’re right: adding operators is not the same as adding energy functions. Of course it isn’t. 🙂 But just stick to the story, please, and stop criticizing. [Oh – just in case you wonder where that minus sign comes from: i2 = –1, of course.]
Adding the two operators together yields the following:
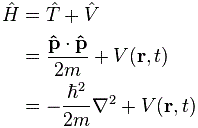
So. Yes. That’s the famous Hamiltonian operator.
OK. So what?
Yes…. Hmm… What do we do with that operator? Well… We apply it to the function and so we write Hψ = … Hmm…
Well… What?
Well… I am not writing this post just to give some definitions of the type of operators that are used in quantum mechanics and then just do obvious stuff by writing it all out. No. I am writing this post to illustrate how things work.
OK. So how does it work then?
Well… It turns out that, in quantum mechanics, we have similar equations as in classical mechanics. Remember that I just wrote down the set of (two) differential equations when discussing Hamiltonian mechanics? Here I’ll do the same. The Hamiltonian operator appears in an equation of which you’ve surely heard of and which, just like me, you’d love to understand–and then I mean: understand it fully, completely, and intuitively. […] Yes. It’s the Schrödinger equation:
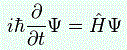
Note, once again, I am not saying anything about where this equation comes from. It’s like jotting down that Lagrange equation, or the set of Hamiltonian equations: I am not saying anything about the why of all this hocus pocus. I am just saying how it goes. So we’ve got another differential equation here, and we have to solve it. If we all write it out using the above definition of the Hamiltonian operator, we get:
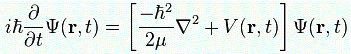
If you’re still with me, you’ll immediately wonder about that μ. Well… Don’t. It’s the mass really, but the so-called reduced mass. Don’t worry about it. Just google it if you want to know more about this concept of a ‘reduced’ mass: it’s a fine point which doesn’t matter here really. The point is the grand result.
But… So… What is the grand result? What are we looking at here? Well… Just as I said above: that Schrödinger equation is a differential equation, just like those equations we got when applying the Lagrangian and Hamiltonian approach to modeling a dynamic system in classical mechanics, and, hence, just like what we (were supposed to) do there, we have to solve it. 🙂 Of course, it looks much more daunting than our Lagrangian or Hamiltonian differential equations, because we’ve got complex-valued functions here, and you’re probably scared of that iħ factor too. But you shouldn’t be. When everything is said and done, we’ve got a differential equation here that we need to solve for ψ. In other words, we need to find functional forms for ψ that satisfy the above equation. That’s it. Period.
So how do these solutions look like? Well, they look like those complex-valued oscillating things in the very first animation above. Let me copy them again:
So… That’s it then? Yes. I won’t say anything more about it here, because (1) this post has become way too long already, and so I won’t dwell on the solutions of that Schrödinger equation, and because (2) I do feel it’s about time I really start doing what it takes, and that’s to work on all of the math that’s necessary to actually do all that hocus-pocus. 🙂
Post scriptum: As for understanding the Schrödinger equation “fully, completely, and intuitively”, I am not sure that’s actually possible. But I am trying hard and so let’s see. 🙂 I’ll tell you after I mastered the math. But something inside of me tells me there’s indeed no Royal Road to it. 🙂
Post scriptum 2 (dated 16 November 2015): I’ve added this post scriptum, more than a year later after writing all of the above, because I now realize how immature it actually is. If you really want to know more about quantum math, then you should read my more recent posts, like the one on the Hamiltonian matrix. It’s not that anything that I write above is wrong—it isn’t. But… Well… It’s just that I feel that I’ve jumped the gun. […] But then that’s probably not a bad thing. 🙂
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:

I notice the “hat” on the Hamiltonian is loosely added or subtracted w/o apparent rhyme or reason. Surely it matters when dealing with Hamiltonian mechanics, or am I being too fastidious?
Jake Banner
You’re right. I need to review a lot of what I wrote… 🙂