
Of course, your first question when seeing the title of this post is: what’s original, really? Well… The answer is simple: it’s the historical approach, and it’s original because it’s actually quite intuitive. Indeed, Lecture no. 16 in Feynman’s third Volume of Lectures on Physics is like a trip down memory lane as Feynman himself acknowledges, after presenting Schrödinger’s equation using that very rudimentary model we developed in our previous post:
“We do not intend to have you think we have derived the Schrödinger equation but only wish to show you one way of thinking about it. When Schrödinger first wrote it down, he gave a kind of derivation based on some heuristic arguments and some brilliant intuitive guesses. Some of the arguments he used were even false, but that does not matter; the only important thing is that the ultimate equation gives a correct description of nature.”
So… Well… Let’s have a look at it. 🙂 We were looking at some electron we described in terms of its location at one or the other atom in a linear array (think of it as a line). We did so by defining base states |n〉 = |xn〉, noting that the state of the electron at any point in time could then be written as:
|φ〉 = ∑ |xn〉Cn(t) = ∑ |xn〉〈xn|φ〉 over all n
The Cn(t) = 〈xn|φ〉 coefficient is the amplitude for the electron to be at xn at t. Hence, the Cn(t) amplitudes vary with t as well as with x. We’ll re-write them as Cn(t) = C(xn, t) = C(xn). Note that the latter notation does not explicitly show the time dependence. The Hamiltonian equation we derived in our previous post is now written as:
iħ·(∂C(xn)/∂t) = E0C(xn) − AC(xn+b) − AC(xn−b)
Note that, as part of our move from the Cn(t) to the C(xn) notation, we write the time derivative dCn(t)/dt now as ∂C(xn)/∂t, so we use the partial derivative symbol now (∂). Of course, the other partial derivative will be ∂C(x)/∂x) as we move from the count variable xn to the continuous variable x, but let’s not get ahead of ourselves here. The solution we found for our C(xn) functions was the following wavefunction:
C(xn) = a·ei(k∙xn−ω·t) = a·e−i∙ω·t·ei∙k∙xn = a·e−i·(E/ħ)·t·ei·k∙xn
We also found the following relationship between E and k:
E = E0 − 2A·cos(kb)
Now, even Feynman struggles a bit with the definition of E0 and k here, and their relationship with E, which is graphed below.
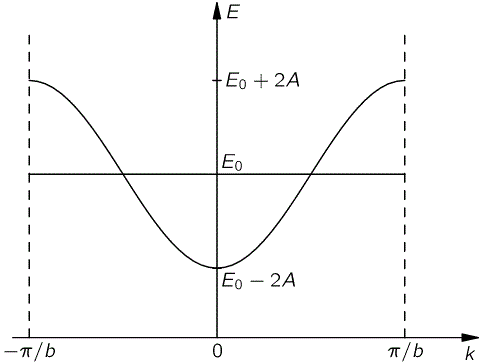
Indeed, he first writes, as he starts developing the model, that E0 is, physically, the energy the electron would have if it couldn’t leak away from one of the atoms, but then he also adds: “It represents really nothing but our choice of the zero of energy.”
This is all quite enigmatic because we cannot just do whatever we want when discussing the energy of a particle. As I pointed out in one of my previous posts, when discussing the energy of a particle in the context of the wavefunction, we generally consider it to be the sum of three different energy concepts:
- The particle’s rest energy m0c2, which de Broglie referred to as internal energy (Eint), and which includes the rest mass of the ‘internal pieces’, as Feynman puts it (now we call those ‘internal pieces’ quarks), as well as their binding energy (i.e. the quarks’ interaction energy).
- Any potential energy it may have because of some field (i.e. if it is not traveling in free space), which we usually denote by U. This field can be anything—gravitational, electromagnetic: it’s whatever changes the energy of the particle because of its position in space.
- The particle’s kinetic energy, which we write in terms of its momentum p: m·v2/2 = m2·v2/(2m) = (m·v)2/(2m) = p2/(2m).
It’s obvious that we cannot just “choose” the zero point here: the particle’s rest energy is its rest energy, and its velocity is its velocity. So it’s not quite clear what the E0 in our model really is. As far as I am concerned, it represents the average energy of the system really, so it’s just like the E0 for our ammonia molecule, or the E0 for whatever two-state system we’ve seen so far. In fact, when Feynman writes that we can “choose our zero of energy so that E0 − 2A = 0″ (so the minimum of that curve above is at the zero of energy), he actually makes some assumption in regard to the relative magnitude of the various amplitudes involved.
We should probably think about it in this way: −(i/ħ)·E0 is the amplitude for the electron to just stay where it is, while i·A/ħ is the amplitude to go somewhere else—and note we’ve got two possibilities here: the electron can go to |xn+1〉, or, alternatively, it can go to |xn−1〉. Now, amplitudes can be associated with probabilities by taking the absolute square, so I’d re-write the E0 − 2A = 0 assumption as:
E0 = 2A ⇔ |−(i/ħ)·E0|2 = |(i/ħ)·2A|2
Hence, in my humble opinion, Feynman’s assumption that E0 − 2A = 0 has nothing to do with ‘choosing the zero of energy’. It’s more like a symmetry assumption: we’re basically saying it’s as likely for the electron to stay where it is as it is to move to the next position. It’s an idea I need to develop somewhat further, as Feynman seems to just gloss over these little things. For example, I am sure it is not a coincidence that the EI, EII, EIII and EIV energy levels we found when discussing the hyperfine splitting of the hydrogen ground state also add up to 0. In fact, you’ll remember we could actually measure those energy levels (EI = EII = EIII = A ≈ 9.23×10−6 eV, and EIV = −3A ≈ −27.7×10−6 eV), so saying that we can “choose” some zero energy point is plain nonsense. The question just doesn’t arise. In any case, as I have to continue the development here, I’ll leave this point for further analysis in the future. So… Well… Just note this E0 − 2A = 0 assumption, as we’ll need it in a moment.
The second assumption we’ll need concerns the variation in k. As you know, we can only get a wave packet if we allow for uncertainty in k which, in turn, translates into uncertainty for E. We write:
ΔE = Δ[E0 − 2A·cos(kb)]
Of course, we’d need to interpret the Δ as a variance (σ2) or a standard deviation (σ) so we can apply the usual rules – i.e. var(a) = 0, var(aX) = a2·var(X), and var(aX ± bY) = a2·var(X) + b2·var(Y) ± 2ab·cov(X, Y) – to be a bit more precise about what we’re writing here, but you get the idea. In fact, let me quickly write it out:
var[E0 − 2A·cos(kb)] = var(E0) + 4A2·var[cos(kb)] ⇔ var(E) = 4A2·var[cos(kb)]
Now, you should check my post scriptum to my page on the Essentials, to see how the probability density function of the cosine of a randomly distributed variable looks like, and then you should go online to find a formula for its variance, and then you can work it all out yourself, because… Well… I am not going to do it for you. What I want to do here is just show how Feynman gets Schrödinger’s equation out of all of these simplifications.
So what’s the second assumption? Well… As the graph shows, our k can take any value between −π/b and +π/b, and therefore, the kb argument in our cosine function can take on any value between −π and +π. In other words, kb could be any angle. However, as Feynman puts it—we’ll be assuming that kb is ‘small enough’, so we can use the small-angle approximations whenever we see the cos(kb) and/or sin(kb) functions. So we write: sin(kb) ≈ kb and cos(kb) ≈ 1 − (kb)2/2 = 1 − k2b2/2. Now, that assumption led to another grand result, which we also derived in our previous post. It had to do with the group velocity of our wave packet, which we calculated as:
v = dω/dk = (2Ab2/ħ)·k
Of course, we should interpret our k here as “the typical k“. Huh? Yes… That’s how Feynman refers to it, and I have no better term for it. It’s some kind of ‘average’ of the Δk interval, obviously, but… Well… Feynman does not give us any exact definition here. Of course, if you look at the graph once more, you’ll say that, if the typical kb has to be “small enough”, then its expected value should be zero. Well… Yes and no. If the typical kb is zero, or if k is zero, then v is zero, and then we’ve got a stationary electron, i.e. an electron with zero momentum. However, because we’re doing what we’re doing (that is, we’re studying “stuff that moves”—as I put it unrespectfully in a few of my posts, so as to distinguish from our analyses of “stuff that doesn’t move”, like our two-state systems, for example), our “typical k” should not be zero here. OK… We can now calculate what’s referred to as the effective mass of the electron, i.e. the mass that appears in the classical kinetic energy formula: K.E. = m·v2/2. Now, there are two ways to do that, and both are somewhat tricky in their interpretation:
1. Using both the E0 − 2A = 0 as well as the “small kb” assumption, we find that E = E0 − 2A·(1 − k2b2/2) = A·k2b2. Using that for the K.E. in our formula yields:
meff = 2A·k2b2/v2 = 2A·k2b2/[(2Ab2/ħ)·k]2 = ħ2/(2Ab2)
2. We can use the classical momentum formula (p = m·v), and then the 2nd de Broglie equation, which tells us that each wavenumber (k) is to be associated with a value for the momentum (p) using the p = ħk (so p is proportional to k, with ħ as the factor of proportionality). So we can now calculate meff as meff = ħk/v. Substituting v again for what we’ve found above, gives us the same:
meff = 2A·k2b2/v = ħ·k/[(2Ab2/ħ)·k] = ħ2/(2Ab2)
Of course, we’re not supposed to know the de Broglie relations at this point in time. 🙂 But, now that you’ve seen them anyway, note how we have two formulas for the momentum:
- The classical formula (p = m·v) tells us that the momentum is proportional to the classical velocity of our particle, and m is then the factor of proportionality.
- The quantum-mechanical formula (p = ħk) tells us that the (typical) momentum is proportional to the (typical) wavenumber, with Planck’s constant (ħ) as the factor of proportionality. Combining both combines the classical and quantum-mechanical perspective of a moving particle:
m·v = ħk
I know… It’s an obvious equation but… Well… Think of it. It’s time to get back to the main story now. Remember we were trying to find Schrödinger’s equation? So let’s get on with it. 🙂
To do so, we need one more assumption. It’s the third major simplification and, just like the others, the assumption is obvious on first, but not on second thought. 😦 So… What is it? Well… It’s easy to see that, in our meff = ħ2/(2Ab2) formula, all depends on the value of 2Ab2. So, just like we should wonder what happens with that kb factor in the argument of our sine or cosine function if b goes to zero—i.e. if we’re letting the lattice spacing go to zero, so we’re moving from a discrete to a continuous analysis now—we should also wonder what happens with that 2Ab2 factor! Well… Think about it. Wouldn’t it be reasonable to assume that the effective mass of our electron is determined by some property of the material, or the medium (so that’s the silicon in our previous post) and, hence, that it’s constant really. Think of it: we’re not changing the fundamentals really—we just have some electron roaming around in some medium and all that we’re doing now is bringing those xn closer together. Much closer. It’s only logical, then, that our amplitude to jump from xn±1 to xn would also increase, no? So what we’re saying is that 2Ab2 is some constant which we write as ħ2/meff or, what amounts to the same, that Ab2 = ħ2/2·meff.
Of course, you may raise two objections here:
- The Ab2 = ħ2/2·meff assumption establishes a very particular relation between A and b, as we can write A as A = [ħ2/(2meff)]·b−2 now. So we’ve got like an y = 1/x2 relation here. Where the hell does that come from?
- We were talking some real stuff here: a crystal lattice with atoms that, in reality, do have some spacing, so that corresponds to some real value for b. So that spacing gives some actual physical significance to those xn values.
Well… What can I say? I think you should re-read that quote of Feynman when I started this post. We’re going to get Schrödinger’s equation – i.e. the ultimate prize for all of the hard work that we’ve been doing so far – but… Yes. It’s really very heuristic, indeed! 🙂 But let’s get on with it now! We can re-write our Hamiltonian equation as:
iħ·(∂C(xn)/∂t) = E0C(xn) − AC(xn+b) − AC(xn−b)]
= (E0−2A)C(xn) + A[2C(xn) − C(xn+b) − C(xn−b) = A[2C(xn) − C(xn+b) − C(xn−b)]
Now, I know your brain is about to melt down but, fiddling with this equation as we’re doing right now, Schrödinger recognized a formula for the second-order derivative of a function. I’ll just jot it down, and you can google it so as to double-check where it comes from:
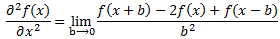
Just substitute f(x) for C(xn) in the second part of our equation above, and you’ll see we can effectively write that 2C(xn) − C(xn+b) − C(xn−b) factor as:
![]()
We’re done. We just iħ·(∂C(xn)/∂t) on the left-hand side now and multiply the expression above with A, to get what we wanted to get, and that’s – YES! – Schrödinger’s equation:

Whatever your objections to this ‘derivation’, it is the correct equation. For a particle in free space, we just write m instead of meff, but it’s exactly the same. I’ll now give you Feynman’s full quote, which is quite enlightening:
“We do not intend to have you think we have derived the Schrödinger equation but only wish to show you one way of thinking about it. When Schrödinger first wrote it down, he gave a kind of derivation based on some heuristic arguments and some brilliant intuitive guesses. Some of the arguments he used were even false, but that does not matter; the only important thing is that the ultimate equation gives a correct description of nature. The purpose of our discussion is then simply to show you that the correct fundamental quantum mechanical equation [i.e. Schrödinger’s equation] has the same form you get for the limiting case of an electron moving along a line of atoms. We can think of it as describing the diffusion of a probability amplitude from one point to the next along the line. That is, if an electron has a certain amplitude to be at one point, it will, a little time later, have some amplitude to be at neighboring points. In fact, the equation looks something like the diffusion equations which we have used in Volume I. But there is one main difference: the imaginary coefficient in front of the time derivative makes the behavior completely different from the ordinary diffusion such as you would have for a gas spreading out along a thin tube. Ordinary diffusion gives rise to real exponential solutions, whereas the solutions of Schrödinger’s equation are complex waves.”
So… That says it all, I guess. Isn’t it great to be where we are? We’ve really climbed a mountain here. And I think the view is gorgeous. 🙂
Oh—just in case you’d think I did not give you Schrödinger’s equation, let me write it in the form you’ll usually see it:
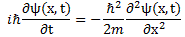
Done! 🙂
Some content on this page was disabled on June 16, 2020 as a result of a DMCA takedown notice from The California Institute of Technology. You can learn more about the DMCA here:

7 thoughts on “Schrödinger’s equation: the original approach”