
Pre-script (dated 26 June 2020): This post got mutilated by the removal of some material by the dark force. You should be able to follow the main story line, however. If anything, the lack of illustrations might actually help you to think things through for yourself. In any case, we now have different views on these concepts as part of our realist interpretation of quantum mechanics, so we recommend you read our recent papers instead of these old blog posts.
Original post:
On the 10th of December, last year, I wrote that my next post would generalize the results we got for two-state systems. That didn’t happen: I didn’t write the ‘next post’—not till now, that is. No. Instead, I started digging—as you can see from all the posts in-between this one and the 10 December piece. And you may also want to take a look at my new Essentials page. 🙂 In any case, it is now time to get back to Feynman’s Lectures on quantum mechanics. Remember where we are: halfway, really. The first half was all about stuff that doesn’t move in space. The second half, i.e. all that we’re going to study now, is about… Well… You guessed it. 🙂 That’s going to be about stuff that does move in space. To see how that works, we first need to generalize the two-state model to an N-state model. Let’s do it.
You’ll remember that, in quantum mechanics, we describe stuff by saying it’s in some state which, as long as we don’t measure in what state exactly, is written as some linear combination of a set of base states. [And please do think about what I highlight here: some state, measure, exactly. It all matters. Think about it!] The coefficients in that linear combination are complex-valued functions, which we referred to as wavefunctions, or (probability) amplitudes. To make a long story short, we wrote:
![]()
These Ci coefficients are a shorthand for 〈 i | ψ(t) 〉 amplitudes. As such, they give us the amplitude of the system to be in state i as a function of time. Their dynamics (i.e. the way they evolve in time) are governed by the Hamiltonian equations, i.e.:

The Hij coefficients in this set of equations are organized in the Hamiltonian matrix, which Feynman refers to as the energy matrix, because these coefficients do represent energies indeed. So we applied all of this to two-state systems and, hence, things should not be too hard now, because it’s all the same, except that we have N base states now, instead of just two.
So we have a N×N matrix whose diagonal elements Hij are real numbers. The non-diagonal elements may be complex numbers but, if they are, the following rule applies: Hij* = Hji. [In case you wonder: that’s got to do with the fact that we can write any final 〈χ| or 〈φ| state as the conjugate transpose of the initial |χ〉 or |φ〉 state, so we can write: 〈χ| = |χ〉*, or 〈φ| = |φ〉*.]
As usual, the trick is to find those N Ci(t) functions: we do so by solving that set of N equations, assuming we know those Hamiltonian coefficients. [As you may suspect, the real challenge is to determine the Hamiltonian, which we assume to be given here. But… Well… You first need to learn how to model stuff. Once you get your degree, you’ll be paid to actually solve problems using those models. 🙂 ] We know the complex exponential is a functional form that usually does that trick. Hence, generalizing the results from our analysis of two-state systems once more, the following general solution is suggested:
Ci(t) = ai·e−i·(E/ħ)·t
Note that we introduce only one E variable here, but N ai coefficients, which may be real- or complex-valued. Indeed, my examples – see my previous posts – often involved real coefficients, but that’s not necessarily the case. Think of the C2(t) = i·e−(i/ħ)·E0·t·sin[(A/ħ)·t] function describing one of the two base state amplitudes for the ammonia molecule—for example. 🙂
Now, that proposed general solution allows us to calculate the derivatives in our Hamiltonian equations (i.e. the d[Ci(t)]/dt functions) as follows:
d[Ci(t)]/dt = −i·(E/ħ)·ai·e−i·(E/ħ)·t
You can now double-check that the set of equations reduces to the following:
![]()
Please do write it out: because we have one E only, the e−i·(E/ħ)·t factor is common to all terms, and so we can cancel it. The other stuff is plain arithmetic: −i·i = −i2 = 1, and the ħ constants cancel out too. So there we are: we’ve got a very simple set of N equations here, with N unknowns (i.e. these a1, a2,…, aN coefficients, to be specific). We can re-write this system as:
The δij here is the Kronecker delta, of course (it’s one for i = j and zero for i ≠ j), and we are now looking at a homogeneous system of equations here, i.e. a set of linear equations in which all the constant terms are zero. You should remember it from your high school math course. To be specific, you’d write it as Ax = 0, with A the coefficient matrix. The trivial solution is the zero solution, of course: all a1, a2,…, aN coefficients are zero. But we don’t want the trivial solution. Now, as Feynman points out – tongue-in-cheek, really – we actually have to be lucky to have a non-trivial solution. Indeed, you may or may not remember that the zero solution was actually the only solution if the determinant of the coefficient matrix was not equal to zero. So we only had a non-trivial solution if the determinant of A was equal to zero, i.e. if Det[A] = 0. So A has to be some so-called singular matrix. You’ll also remember that, in that case, we got an infinite number of solutions, to which we could apply the so-called superposition principle: if x and y are two solutions to the homogeneous set of equations Ax = 0, then any linear combination of x and y is also a solution. I wrote an addendum to this post (just scroll down and you’ll find it), which explains what systems of linear equations are all about, so I’ll refer you to that in case you’d need more detail here. I need to continue our story here. The bottom line is: the [Hij–δijE] matrix needs to be singular for the system to have meaningful solutions, so we will only have a non-trivial solution for those values of E for which
Det[Hij–δijE] = 0
Let’s spell it out. The condition above is the same as writing:
So far, so good. What’s next? Well… The formula for the determinant is the following:

That looks like a monster, and it is, but, in essence, what we’ve got here is an expression for the determinant in terms of the permutations of the matrix elements. This is not a math course so I’ll just refer you Wikipedia for a detailed explanation of this formula for the determinant. The bottom line is: if we write it all out, then Det[Hij–δijE] is just an Nth order polynomial in E. In other words: it’s just a sum of products with powers of E up to EN, and so our Det[Hij–δijE] = 0 condition amounts to equating it with zero.
In general, we’ll have N roots, but – sorry you need to remember so much from your high school math classes here – some of them may be multiple roots (i.e. two or more roots may be equal). We’ll call those roots—you guessed it:
EI, EII,…, En,…, EN
Note I am following Feynman’s exposé, and so he uses n, rather than k, to denote the nth Roman numeral (as opposed to Latin numerals). Now, I know your brain is near the melting point… But… Well… We’re not done yet. Just hang on. For each of these values E = EI, EII,…, En,…, EN, we have an associated set of solutions ai. As Feynman puts it: you get a set which belongs to En. In order to not forget that, for each En, we’re talking a set of N coefficients ai (i = 1, 2,…, N), we denote that set not by ai(n) but by ai(n). So that’s why we use boldface for our index n: it’s special—and not only because it denotes a Roman numeral! It’s just one of Feynman’s many meaningful conventions.
Now remember that Ci(t) = ai·e−i·(E/ħ)·t formula. For each set of ai(n) coefficients, we’ll have a set of Ci(n) functions which, naturally, we can write as:
Ci(n) = ai(n)·e−i·(En/ħ)·t
So far, so good. We have N ai(n) coefficients and N Ci(n) functions. That’s easy enough to understand. Now we’ll define also define a set of N new vectors, which we’ll write as |n〉, and which we’ll refer to as the state vectors that describe the configuration of the definite energy states En (n = I, II,… N). [Just breathe right now: I’ll (try to) explain this in a moment.] Moreover, we’ll write our set of coefficients ai(n) as 〈i|n〉. Again, the boldface n reminds us we’re talking a set of N complex numbers here. So we re-write that set of N Ci(n) functions as follows:
Ci(n) = 〈i|n〉·e−i·(En/ħ)·t
We can expand this as follows:
Ci(n) = 〈 i | ψn(t) 〉 = 〈 i | n 〉·e−i·(En/ħ)·t
which, of course, implies that:
| ψn(t) 〉 = |n〉·e−i·(En/ħ)·t
So now you may understand Feynman’s description of those |n〉 vectors somewhat better. As he puts it:
“The |n〉 vectors – of which there are N – are the state vectors that describe the configuration of the definite energy states En (n = I, II,… N), but have the time dependence factored out.”
Hmm… I know. This stuff is hard to swallow, but we’re not done yet: if your brain hasn’t melted yet, it may do so now. You’ll remember we talked about eigenvalues and eigenvectors in our post on the math behind the quantum-mechanical model of our ammonia molecule. Well… We can generalize the results we got there:
- The energies EI, EII,…, En,…, EN are the eigenvalues of the Hamiltonian matrix H.
- The state vectors |n〉 that are associated with each energy En, i.e. the set of vectors |n〉, are the corresponding eigenstates.
So… Well… That’s it! We’re done! This is all there is to it. I know it’s a lot but… Well… We’ve got a general description of N-state systems here, and so that’s great!
Let me make some concluding remarks though.
First, note the following property: if we let the Hamiltonian matrix act on one of those state vectors |n〉, the result is just En times the same state. We write:
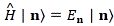
We’re writing nothing new here really: it’s just a consequence of the definition of eigenstates and eigenvalues. The more interesting thing is the following. When describing our two-state systems, we saw we could use the states that we associated with the EI and EII as a new base set. The same is true for N-state systems: the state vectors |n〉 can also be used as a base set. Of course, for that to be the case, all of the states must be orthogonal, meaning that for any two of them, say |n〉 and |m〉, the following equation must hold:
〈n|m〉 = 0
Feynman shows this will be true automatically if all the energies are different. If they’re not – i.e. if our polynomial in E would accidentally have two (or more) roots with the same energy – then things are more complicated. However, as Feynman points out, this problem can be solved by ‘cooking up’ two new states that do have the same energy but are also orthogonal. I’ll refer you to him for the detail, as well as for the proof of that 〈n|m〉 = 0 equation.
Finally, you should also note that – because of the homogeneity principle – it’s possible to multiply the N ai(n) coefficients by a suitable factor so that all the states are normalized, by which we mean:
〈n|n〉 = 1
Well… We’re done! For today, at least! 🙂
Addendum on Systems of Linear Equations
It’s probably good to briefly remind you of your high school math class on systems of linear equations. First note the difference between homogeneous and non-homogeneous equations. Non-homogeneous equations have a non-zero constant term. The following three equations are an example of a non-homogeneous set of equations:
- 3x + 2y − z = 1
- 2x − 2y + 4z = −2
- −x + y/2 − z = 0
We have a point solution here: (x, y, z) = (1, −2, −2). The geometry of the situation is something like this:

One of the equations may be a linear combination of the two others. In that case, that equation can be removed without affecting the solution set. For the three-dimensional case, we get a line solution, as illustrated below. 
Homogeneous and non-homogeneous sets of linear equations are closely related. If we write a homogeneous set as Ax = 0, then a non-homogeneous set of equations can be written as Ax = b. They are related. More in particular, the solution set for Ax = b is going to be a translation of the solution set for Ax = 0. We can write that more formally as follows:
If p is any specific solution to the linear system Ax = b, then the entire solution set can be described as {p + v|v is any solution to Ax = 0}
The solution set for a homogeneous system is a linear subspace. In the example above, which had three variables and, hence, for which the vector space was three-dimensional, there were three possibilities: a point, line or plane solution. All are (linear) subspaces—although you’d want to drop the term ‘linear’ for the point solution, of course. 🙂 Formally, a subspace is defined as follows: if V is a vector space, then W is a subspace if and only if:
- The zero vector (i.e. 0) is in W.
- If x is an element of W, then any scalar multiple ax will be an element of W too (this is often referred to as the property of homogeneity).
- If x and y are elements of W, then the sum of x and y (i.e. x + y) will be an element of W too (this is referred to as the property of additivity).
As you can see, the superposition principle actually combines the properties of homogeneity and additivity: if x and y are solutions, then any linear combination of them will be a solution too.
The solution set for a non-homogeneous system of equations is referred to as a flat. It’s a subset too, so it’s like a subspace, except that it need not pass through the origin. Again, the flats in two-dimensional space are points and lines, while in three-dimensional space we have points, lines and planes. In general, we’ll have flats, and subspaces, of every dimension from 0 to n−1 in n-dimensional space.
OK. That’s clear enough, but what is all that talk about eigenstates and eigenvalues about? Mathematically, we define eigenvectors, aka as characteristic vectors, as follows:
- The non-zero vector v is an eigenvector of a square matrix A if Av is a scalar multiple of v, i.e. Av = λv.
- The associated scalar λ is known as the eigenvalue (or characteristic value) associated with the eigenvector v.
Now, in physics, we talk states, rather than vectors—although our states are vectors, of course. So we’ll call them eigenstates, rather than eigenvectors. But the principle is the same, really. Now, I won’t copy what you can find elsewhere—especially not in an addendum to a post, like this one. So let me just refer you elswhere. Paul’s Online Math Notes, for example, are quite good on this—especially in the context of solving a set of differential equations, which is what we are doing here. And you can also find a more general treatment in the Wikipedia article on eigenvalues and eigenstates which, while being general, highlights their particular use in quantum math.
Some content on this page was disabled on June 20, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 20, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 20, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 20, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 20, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:

4 thoughts on “N-state systems”