Pre-scriptum (dated 26 June 2020): the material in this post remains interesting but is, strictly speaking, not a prerequisite to understand quantum mechanics. It’s yet another example of how one can get lost in math when studying or teaching physics. ![]()
Original post:
This is my second post on Riemann surfaces, so they must be important. [At least I hope so, because it takes quite some time to understand them. :-)]
From my first post on this topic, you may or may not remember that a Riemann surface is supposed to solve the problem of multivalued complex functions such as, for instance, the complex logarithmic function (log z = ln r + i(θ + 2nπ) or the complex exponential function (zc = ec log z). [Note that the problem of multivaluedness for the (complex) exponential function is a direct consequence of its definition in terms of the (complex) logarithmic function.]
In that same post, I also wrote that it all looked somewhat fishy to me: we first use the function causing the problem of multivaluedness to construct a Riemann surface, and then we use that very same surface as a domain for the function itself to solve the problem (i.e. to reduce the function to a single-valued (analytic) one). Penrose does not have any issues with that though. In Chapter 8 (yes, that’s where I am right now: I am moving very slowly on his Road to Reality, as it’s been three months of reading now, and there are 34 chapters!), he writes that “Complex (analytic) functions have a mind of their own, and decide themselves what their domain should be, irrespective of the region of the complex plane which we ourselves may initially have allotted to it. While we may regard the function’s domain to be represented by the Riemann surface associated with the function, the domain is not given ahead of time: it is the explicit form of the function itself that tells us which Riemann surface the domain actually is.”
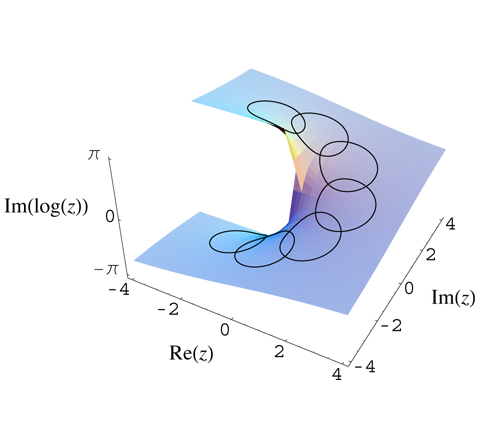
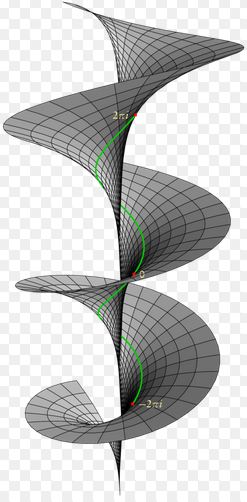
Let me retrieve the graph of the Riemannian domain for the log z function once more:

For each point z in the complex plane (and we can represent z both with rectangular as well as polar coordinates: z = x + iy = reiθ), we have an infinite number of log z values: one for each value of n in the log z = ln r + i(θ + 2nπ) expression (n = 0, ±1, ±2, ±3,…, ±∞). So what we do when we promote this Riemann surface as a domain for the log z function is equivalent to saying that point z is actually not one single point z with modulus r and argument θ + 2nπ, but an infinite collection of points: these points all have the same modulus ¦z¦ = r but we distinguish the various ‘representations’ of z by treating θ, θ ± 2π, θ ±+ 4π, θ ± 6π, etcetera, as separate argument values as we go up or down on that spiral ramp. So that is what is represented by that infinite number of sheets, which are separated from each other by a vertical distance of 2π. These sheets are all connected at or through the origin (at which the log z function is undefined: therefore, the origin is not part of the domain), which is the branch point for this function. Let me copy some formal language on the construction of that surface here:
“We treat the z plane, with the origin deleted, as a thin sheet R0 which is cut along the positive half of the real axis. On that sheet, let θ range from 0 to 2π. Let a second sheet R1 be cut in the same way and placed in front of the sheet R0. The lower edge of the slit in R0 is then joined to the upper edge of the slit in R1. On R1, the angle θ ranges from 2π to 4π; so, when z is represented by a point on R1, the imaginary component of log z ranges from 2π to 4π.” And then we repeat the whole thing, of course: “A sheet R2 is then cut in the same way and placed in front of R1. The lower edge of the slit in R1. is joined to the upper edge of the slit in this new sheet, and similarly for sheets R3, R4… A sheet R-1, R-2, R-3,… are constructed in like manner.” (Brown and Churchill, Complex Variables and Applications, 7th edition, p. 335-336)
The key phrase above for me is this “when z is represented by a point on R1“, because that’s what it is really: we have an infinite number of representations of z here, namely one representation of z for each branch of the log z function. So, as n = 0, ±1, , ±2, ±3 etcetera, we have an infinite number of them indeed. You’ll also remember that each branch covers a range from some random angle α to α + 2π. Imagine a continuous curve around the origin on this Riemann surface: as we move around, the angle of z changes from 0 to 2θ on sheet R0, and then from 2π to 4π on sheet R1 and so on and so on.
The illustration above also illustrates the meaning of a branch point. Imagine yourself walking on that surface and approaching the origin, from any direction really. At the origin itself, you can choose what to do: either you take the elevator up or down to some other level or, else, the elevator doesn’t work and so then you have to walk up or down that ramp to get to another level. If you choose to walk along the ramp, the angle θ changes gradually or, to put it in mathematical terms, in a continuous way. However, if you took the elevator and got out at some other level, you’ll find that you’ve literally ‘jumped’ one or more levels. Indeed, remember that log z = ln r + i(θ + 2nπ) and so ln r, the horizontal distance from the origin didn’t change, but you did add some multiple of 2π to the vertical distance, i.e. the imaginary part of the log z value.
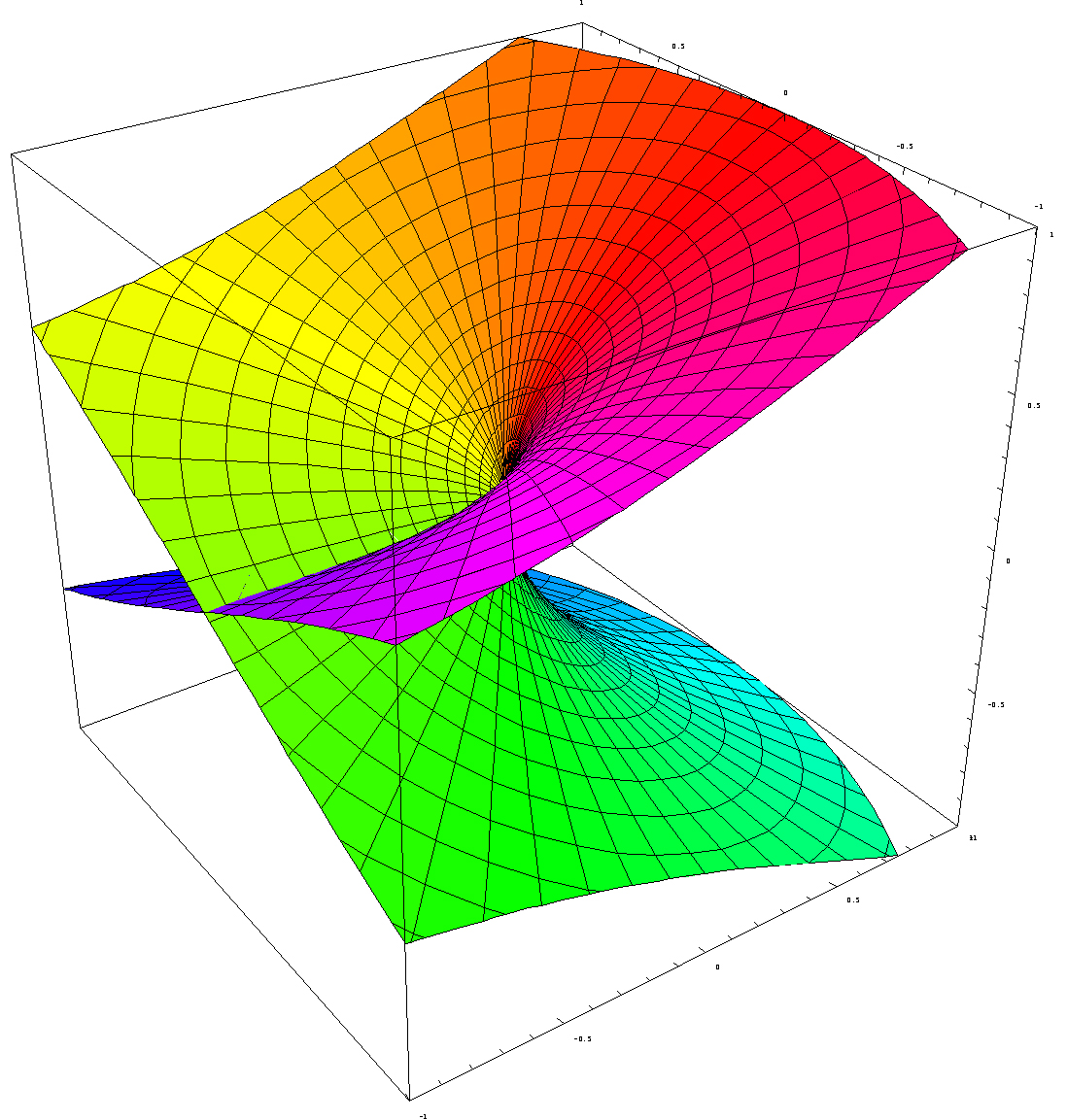
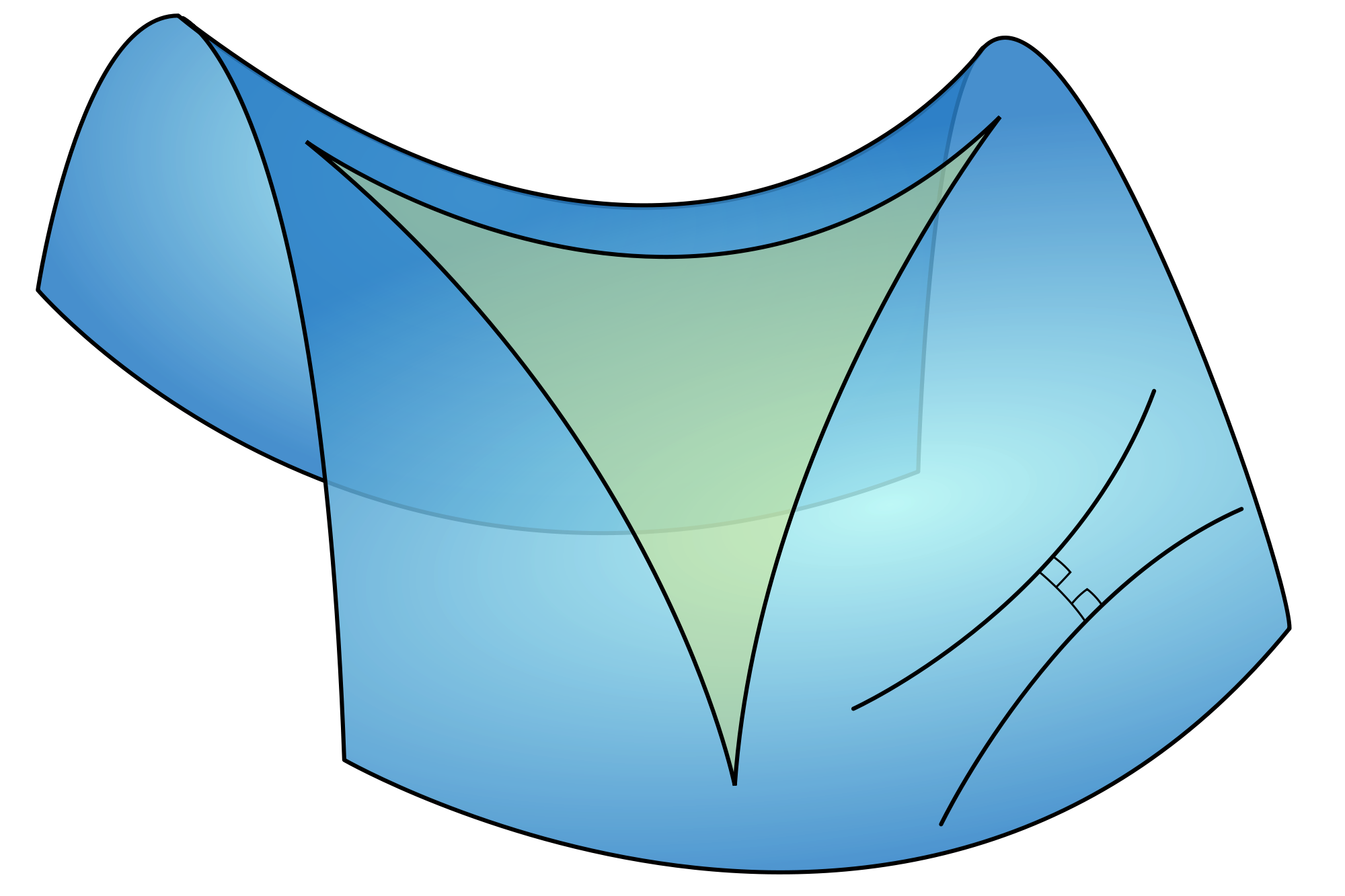
Let us now construct a Riemann surface for some other multiple-valued functions. Let’s keep it simple and start with the square root of z, so c = 1/2, which is nothing else than a specific example of the complex exponential function zc = zc = ec log z: we just take a real number for c here. In fact, we’re taking a very simple rational number value for c: 1/2 = 0.5. Taking the square, cube, fourth or nth root of a complex number is indeed nothing but a special case of the complex exponential function. The illustration below (taken from Wikipedia) shows us the Riemann surface for the square root function.

As you can see, the spiraling surface turns back into itself after two turns. So what’s going on here? Well… Our multivalued function here does not have an infinite number of values for each z: it has only two, namely √r ei(θ/2) and √r ei(θ/2 + π). But what’s that? We just said that the log function – of which this function is a special case – had an infinite number of values? Well… To be somewhat more precise: z1/2 actually does have an infinite number of values for each z (just like any other complex exponential function), but it has only two values that are different from each other. All the others coincide with one of the two principal ones. Indeed, we can write the following:
w = √z = z1/2 = e(1/2) log z = e(1/2)[ln r + i(θ + 2nπ)] = r1/2 ei(θ/2 + nπ) = √r ei(θ/2 + nπ)
(n = 0, ±1, ±2, ±3,…)
For n = 0, this expression reduces to z1/2 = √r eiθ/2. For n = ±1, we have z1/2 = √r ei(θ/2 + π), which is different than the value we had for n = 0. In fact, it’s easy to see that this second root is the exact opposite of the first root: √r ei(θ/2 + π) = √r eiθ/2eiπ = – √r eiθ/2). However, for n = 2, we have z1/2 = √r ei(θ/2 + 2π), and so that’s the same value (z1/2 = √r eiθ/2) as for n = 0. Indeed, taking the value of n = 2 amounts to adding 2π to the argument of w and so get the same point as the one we found for n = 0. [As for the plus or minus sign, note that, for n = -1, we have z1/2 = √r ei(θ/2 -π) = √r ei(θ/2 -π+2π) = √r ei(θ/2 +π) and, hence, the plus or minus sign for n does not make any difference indeed.]
In short, as mentioned above, we have only two different values for w = √z = z1/2 and so we have to construct two sheets only, instead of an infinite number of them, like we had to do for the log z function. To be more precise, because the sheet for n = ±2 will be the same sheet as for n = 0, we need to construct one sheet for n = 0 and one sheet for n = ±1, and so that’s what shown above: the surface has two sheets (one for each branch of the function) and so if we make two turns around the origin (one on each sheet), we’re back at the same point, which means that, while we have a one-to-two relationship between each point z on the complex plane and the two values z1/2 for this point, we’ve got a one-on-one relationship between every value of z1/2 and each point on this surface.
For ease of reference in future discussions, I will introduce a personal nonsensical convention here: I will refer to (i) the n = 0 case as the ‘positive’ root, or as w1, i.e. the ‘first’ root, and to (ii) the n = ± 1 case as the ‘negative’ root, or w2, i.e. the ‘second’ root. The convention is nonsensical because there is no such thing as positive or negative complex numbers: only their real and imaginary parts (i.e. real numbers) have a sign. Also, these roots also do not have any particular order: there are just two of them, but neither of the two is like the ‘principal’ one or so. However, you can see where it comes from: the two roots are each other’s exact opposite w2 = u2 + iv2 = —w1 = -u1 – iv1. [Note that, of course, we have w1w1 = w12 = w2w2 = w22 = z, but that the product of the two distinct roots is equal to —z. Indeed, w1w2 = w2w1 = √rei(θ/2)√rei(θ/2 + π) = rei(θ+π) = reiθeiπ = -reiθ = -z.]
What’s the upshot? Well… As I mentioned above already, what’s happening here is that we treat z = rei(θ+2π) as a different ‘point’ than z = reiθ. Why? Well… Because of that square root function. Indeed, we have θ going from 0 to 2π on the first ‘sheet’, and then from 2π0 to 4π on the second ‘sheet’. Then this second sheet turns back into the first sheet and so then we’re back at normal and, hence, while θ going from 0π to 2π is not the same as θ going from 2π to 4π, θ going from 4π to 6π is the same as θ going from 0 to 2π (in the sense that it does not affect the value of w = z1/2). That’s quite logical indeed because, if we denote w as w = √r eiΘ (with Θ = θ/2 + nπ, and n = 0 or ± 1), then it’s clear that arg w = Θ will range from 0 to 2π if (and only if) arg z = θ ranges from 0 to 4π. So as the argument of w makes one loop around the origin – which is what ‘normal’ complex numbers do – the argument of z makes two loops. However, once we’re back at Θ = 2π, then we’ve got the same complex number w again and so then it’s business as usual.
OK. That should be clear enough. Perhaps one question remains: how do you construct a nice graph like the one above?
Well, look carefully at the shape of it. The vertical distance reflects the real part of √z for n = 0, i.e. √r cos(θ/2). Indeed, the horizontal plane is the the complex z plane and so the horizontal axes are x and y respectively (i.e. the x and y coordinates of z = x + iy). So this vertical distance equals 1 when x = 1 and y = 0 and that’s the highest point on the upper half of the top sheet on this plot (i.e. the ‘high-water mark’ on the right-hand (back-)side of the cuboid (or rectangular prism) in which this graph is being plotted). So the argument of z is zero there (θ = 0). The value on the vertical axis then falls from one to zero as we turn counterclockwise on the surface of this first sheet, and that’s consistent with a value for θ being equal to π there (θ = π), because then we have cos(π/2) = 0. Then we go underneath the z plane and make another half turn, so we add another π radians to the value θ and we arrive at the lowest point on the lower half of the bottom sheet on this plot, right under the point where we started, where θ = 2π and, hence, Re(√z) = √r cos(θ/2) (for n = 0) = cos(2π/2) = cos(2π/2) = -1.
We can then move up again, counterclockwise on the bottom sheet, to arrive once again at the spot where the bottom sheet passes through the top sheet: the value of θ there should be equal to θ = 3π, as we have now made three half turns around the origin from our original point of departure (i.e. we added three times π to our original angle of departure, which was θ = 0) and, hence, we have Re(√z) = √r cos(3θ/2) = 0 again. Finally, another half turn brings us back to our point of departure, i.e. the positive half of the real axis, where θ has now reached the value of θ = 4π, i.e. zero plus two times 2π. At that point, the argument of w (i.e. Θ) will have reached the value of 2π, i.e. 4π/2, and so we’re talking the same w = z1/2 as when we started indeed, where we had Θ = θ/2 = 0.
What about the imaginary part? Well… Nothing special really (as for now at least): a graph of the imaginary part of √z would be equally easy to establish: Im(√z) = √r sin(θ/2) and, hence, rotating this plot 180 degrees around the vertical axis will do the trick.
Hmm… OK. What’s next? Well… The graphs below show the Riemann surfaces for the third and fourth root of z respectively, i.e. z1/3 and z1/4 respectively. It’s easy to see that we now have three and four sheets respectively (instead of two only), and that we have to take three and four full turns respectively to get back at our starting point, where we should find the same values for z1/3 and z1/4 as where we started. That sounds logical, because we always have three cube roots of any (complex) numbers, and four fourth roots, so we’d expect to need the same number of sheets to differentiate between these three or four values respectively.
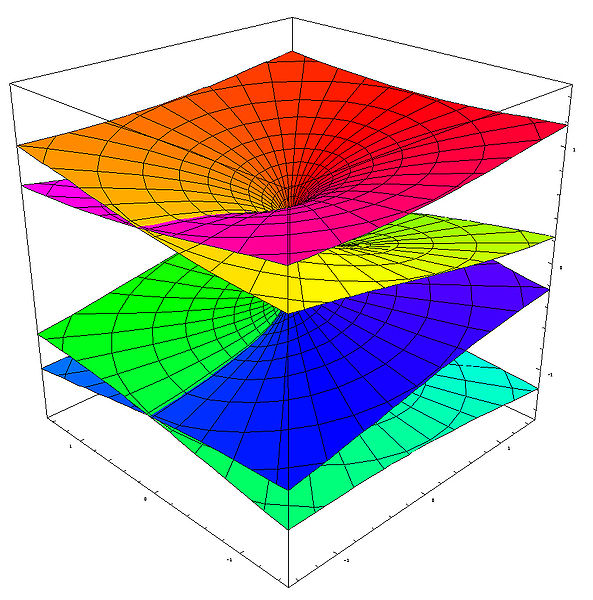
In fact, the table below may help to interpret what’s going on for the cube root function. We have three cube roots of z: w1, w2 and w3. These three values are symmetrical though, as indicated be the red, green and yellow colors in the table below: for example, the value of w for θ ranging from 4π to 6π for the n = 0 case (i.e. w1) is the same as the value of w for θ ranging from 0 to 2π for the n = 1 case (or the n = -2 case, which is equivalent to the n = 1 case).

So the origin (i.e. the point zero) for all of the above surfaces is referred to as the branch point, and the number of turns one has to make to get back at the same point determines the so-called order of the branch point. So, for w = z1/2, we have a branch point of order 2; for for w = z1/3, we have a branch point of order 3; etcetera. In fact, for the log z function, the branch point does not have a finite order: it is said to have infinite order.
After a very brief discussion of all of this, Penrose then proceeds and transforms a ‘square root Riemann surface’ into a torus (i.e. a donut shape). The correspondence between a ‘square root Riemann surface’ and a torus does not depend on the number of branch points: it depends on the number of sheets, i.e. the order of the branch point. Indeed, Penrose’s example of a square root function is w = (1 – z3)1/2, and so that’s a square root function with three branch points (the three roots of unity), but so these branch points are all of order two and, hence, there are two sheets only and, therefore, the torus is the appropriate shape for this kind of ‘transformation’. I will come back to that in the next post.
OK… But I still don’t quite get why this Riemann surfaces are so important. I must assume it has something to do with the mystery of rolled-up dimensions and all that (so that’s string theory), but I guess I’ll be able to shed some more light on that question only once I’ve gotten through that whole chapter on them (and the chapters following that one). I’ll keep you posted. 🙂
Post scriptum: On page 138 (Fig. 8.3), Penrose shows us how to construct the spiral ramp for the log z function. He insists on doing this by taking overlapping patches of space, such as the L(z) and Log z branch of the log z function, with θ going from 0 to 2π for the L(z) branch) and from -π to +π for the Log z branch (so we have an overlap here from 0 to +π). Indeed, one cannot glue or staple patches together if the patch surfaces don’t overlap to some extent… unless you use sellotape of course. 🙂 However, continuity requires some overlap and, hence, just joining the edges of patches of space with sellotape, instead of gluing overlapping areas together, is not allowed. 🙂
So, constructing a model of that spiral ramp is not an extraordinary intellectual challenge. However, constructing a model of the Riemann surfaces described above (i.e. z1/2, z1/3, z1/4 or, more in general, constructing a Riemann surface for any rational power of z, i.e. any function w = zn/m, is not all that easy: Brown and Churchill, for example, state that is actually ‘physically impossible’ to model that (see Brown and Churchill, Complex Variables and Applications (7th ed.), p. 337).
Huh? But so we just did that for z1/2, z1/3 and z1/4, didn’t we? Well… Look at that plot for w = z1/2 once again. The problem is that the two sheets cut through each other. They have to do that, of course, because, unlike the sheets of the log z function, they have to join back together again, instead of just spiraling endlessly up or down. So we just let these sheets cross each other. However, at that spot (i.e. the line where the sheets cross each other), we would actually need two representations of z. Indeed, as the top sheet cuts through the bottom sheet (so as we’re moving down on that surface), the value of θ will be equal to π, and so that corresponds to a value for w equal to w = z1/2 = √r eiπ/2 (I am looking at the n = 0 case here). However, when the bottom sheet cuts through the top sheet (so if we’re moving up instead of down on that surface), θ’s value will be equal to 3π (because we’ve made three half-turns now, instead of just one) and, hence, that corresponds to a value for w equal to w = z1/2 = √r e3iπ/2, which is obviously different from √r eiπ/2. I could do the same calculation for the n = ±1 case: just add ±π to the argument of w.
Huh? You’ll probably wonder what I am trying to say here. Well, what I am saying here is that plot of the surface gives us the impression that we do not have two separate roots w1 and w2 on the (negative) real axis. But so that’s not the case: we do have two roots there, but we can’t distinguish them with that plot of the surface because we’re only looking at the real part of w.
So what?
Well… I’d say that shouldn’t worry us all that much. When building a model, we just need to be aware that it’s a model only and, hence, we need to be aware of the limitations of what we’re doing. I actually build a paper model of that surface by taking two paper disks: one for the top sheet, and one for the bottom sheet. Then I cut those two disks along the radius and folded and glued both of them like a Chinese hat (yes, like the one the girl below is wearing). And then I took those two little paper Chinese hats, put one of them upside down, and ‘connected’ them (or should I say, ‘stitched’ or ‘welded’ perhaps? :-)) with the other one along the radius where I had cut into these disks. [I could go through the trouble of taking a digital picture of it but it’s better you try it yourself.]

Wow! I did not expect to be used as an illustration in a blog on math and physics! 🙂
🙂 OK. Let’s get somewhat more serious again. The point to note is that, while these models (both the plot as well as the two paper Chinese hats :-)) look nice enough, Brown and Churchill are right when they note that ‘the points where two of the edges are joined are distinct from the points where the two other edges are joined’. However, I don’t agree with their conclusion in the next phrase, which states that it is ‘thus physically impossible to build a model of that Riemann surface.’ Again, the plot above and my little paper Chinese hats are OK as a model – as long as we’re aware of how we should interpret that line where the sheets cross each other: that line represents two different sets of points.
Let me go one step further here (in an attempt to fully exhaust the topic) and insert a table here with the values of both the real and imaginary parts of √z for both roots (i.e. the n = 0 and n = ± 1 case). The table shows what is to be expected: the values for the n = ± 1 case are the same as for n = 0 but with the opposite sign. That reflects the fact that the two roots are each other’s opposite indeed, so when you’re plotting the two square roots of a complex number z = reiθ, you’ll see they are on opposite sides on a circle with radius √r. Indeed, rei(θ/2 + π) = rei(θ/2)eiπ = –rei(θ/2). [If the illustration below is too small to read the print, then just click on it and it should expand.]
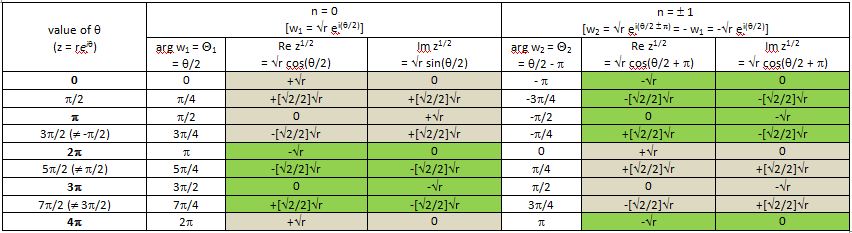
The grey and green colors in the table have the same role as the red, green and yellow colors I used to illustrated how the cube roots of z come back periodically. We have the same thing here indeed: the values we get for the n = 0 case are exactly the same as for the n = ± 1 case but with a difference in ‘phase’ I’d say of one turn around the origin, i.e. a ‘phase’ difference of 2π. In other words, the value of √z in the n = 0 case for θ going from 0 to 2π is equal to the value of √z in the n = ± 1 case but for θ going from 2π to 4π and, vice versa, the value of √z in the n = ±1 case for θ going from 0 to 2π is equal to the value of √z in the n = 0 case for θ going from 2π to 4π. Now what’s the meaning of that?
It’s quite simple really. The two different values of n mark the different branches of the w function, but branches of functions always overlap of course. Indeed, look at the value of the argument of w, i.e. Θ: for the n = 0 case, we have 0 < Θ < 2π, while for the n = ± 1 case, we have -π < Θ < +π. So we’ve got two different branches here indeed, but they overlap for all values Θ between 0 and π and, for these values, where Θ1 = Θ2, we will obviously get the same value for w, even if we’re looking at two different branches (Θ1 is the argument of w1, and Θ2 is the argument of w2).
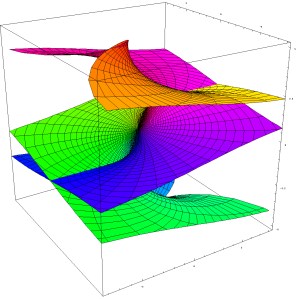
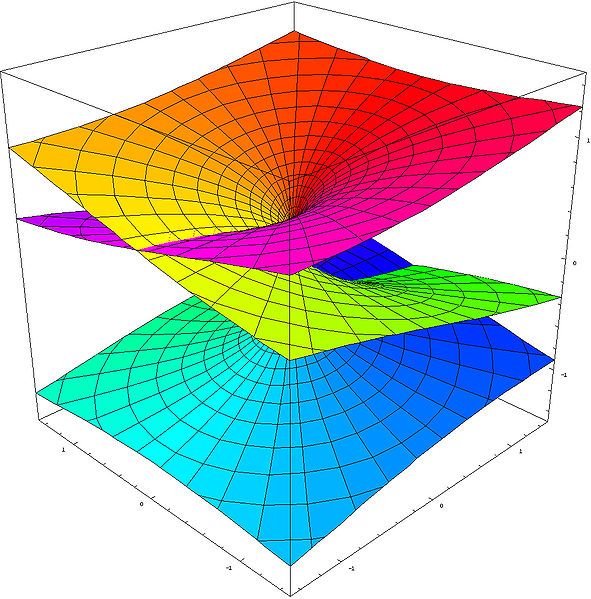
OK. I guess that’s all very self-evident and so I should really stop here. However, let me conclude by noting the following: to understand the ‘fully story’ behind the graph, we should actually plot both the surface of the imaginary part of √z as well as the surface of the real part of of √z, and superimpose both. We’d obviously get something that would much more complicated than the ‘two Chinese hats’ picture. I haven’t learned how to master math software (such as Maple for instance), as yet, and so I’ll just copy a plot which I found on the web: it’s a plot of both the real and imaginary part of the function w = z2. That’s obviously not the same as the w = z1/2 function, because w = z2 is a single-valued function and so we don’t have all these complications. However, the graph is illustrative because it shows how two surfaces – one representing the real part and the other the imaginary part of a function value – cut through each other thereby creating four half-lines (or rays) which join at the origin.
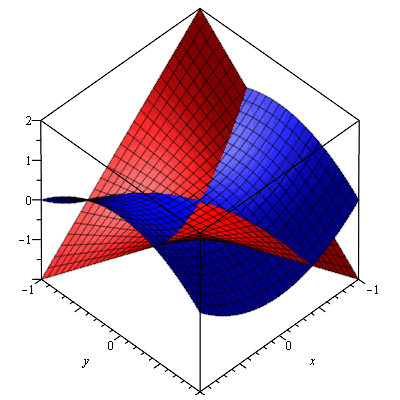
So we could have something similar for the w = z1/2 function if we’d have one surface representing the imaginary part of z1/2 and another representing the real part of z1/2. The sketch below illustrates the point. It is a cross-section of the Riemann surface along the x-axis (so the imaginary part of z is zero there, as the values of θ are limited to 0, π, 2π, 3π, back to 4π = 0), but with both the real as well as the imaginary part of z1/2 on it. It is obvious that, for the w = z1/2 function, two of the four half-lines marking where the two surfaces are crossing each other coincide with the positive and negative real axis respectively: indeed, Re( z1/2) = 0 for θ = π and 3π (so that’s the negative real axis), and Im(z1/2) = 0 for θ = 0, 2π and 4π (so that’s the positive real axis).
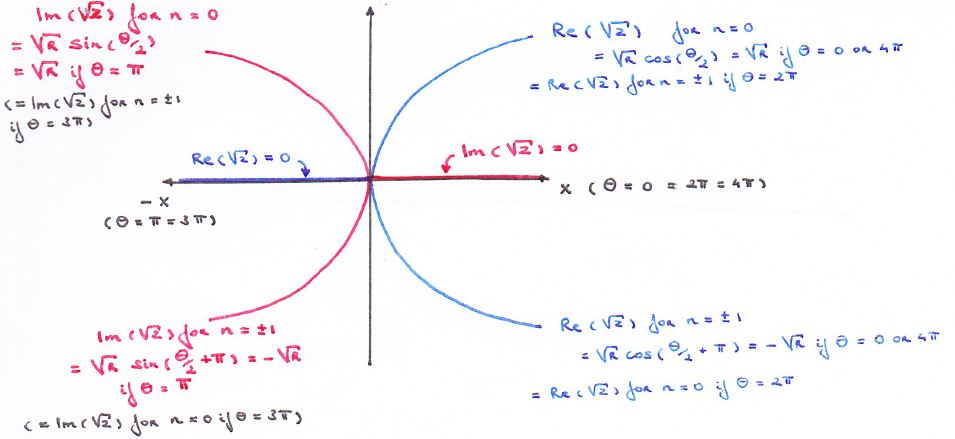
The other two half-lines are orthogonal to the real axis. They follow a curved line, starting from the origin, whose orthogonal projection on the z plane coincides with the y axis. The shape of these two curved lines (i.e. the place where the two sheets intersect above and under the y axis) is given by the values for the real and imaginary parts of the √z function, i.e. the vertical distance from the y axis is equal to ± (√2√r)/2.
Hmm… I guess that, by now, you’re thinking that this is getting way too complicated. In addition, you’ll say that the representation of the Riemann surface by just one number (i.e. either the real or the imaginary part) makes sense, because we want one point to represent one value of w only, don’t we? So we want one point to represent one point only, and that’s not what we’re getting when plotting both the imaginary as well as the real part of w in a combined graph. Well… Yes and no. Insisting that we shouldn’t forget about the imaginary part of the surface makes sense in light of the next post, in which I’ll say a think or two about ‘compactifying’ surfaces (or spaces) like the one above. But so that’s for the next post only and, yes, you’re right: I should stop here.