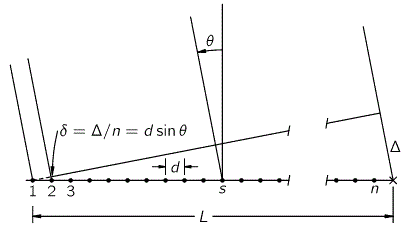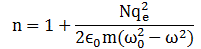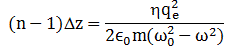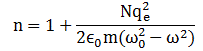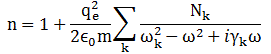Pre-scriptum (dated 26 June 2020): Some of the relevant illustrations in this post were removed as a result of an attack by the dark force. Too bad, because I liked this post. In any case, despite the removal of the illustrations, I think you will still be able to reconstruct the main story line.
Original post:
In this post, we go right at the heart of classical physics. It’s going to be a very long post – and a very difficult one – but it will really give you a good ‘feel’ of what classical physics is all about. To understand classical physics – in order to compare it, later, with quantum mechanics – it’s essential, indeed, to try to follow the math in order to get a good feel for what ‘fields’ and ‘charges’ and ‘atomic oscillators’ actually represent.
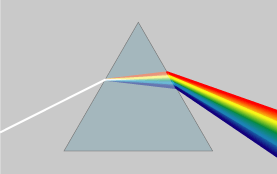
As for the topic of this post itself, we’re going to look at refraction again: light gets dispersed as it travels from one medium to another, as illustrated below.
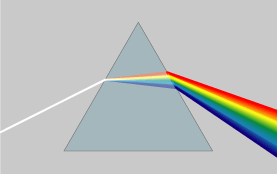
Dispersion literally means “distribution over a wide area”, and so that’s what happens as the light travels through the prism: the various frequencies (i.e. the various colors that make up natural ‘white’ light) are being separated out over slightly different angles. In physics jargon, we say that the index of refraction depends on the frequency of the wave – but so we could also say that the breaking angle depends on the color. But that sounds less scientific, of course. In any case, it’s good to get the terminology right. Generally speaking, the term refraction (as opposed to dispersion) is used to refer to the bending (or ‘breaking’) of light of a specific frequency only, i.e. monochromatic light, as shown in the photograph below. […] OK. We’re all set now.

It is interesting to note that the photograph above shows how the monochromatic light is actually being obtained: if you look carefully, you’ll see two secondary beams on the left-hand side (with an intensity that is much less than the central beam – barely visible in fact). That suggests that the original light source was sent through a diffraction grating designed to filter only one frequency out of the original light beam. That beam is then sent through a bloc of transparent material (plastic in this case) and comes out again, but displaced parallel to itself. So the block of plastics ‘offsets’ the beam. So how do we explain that in classical physics?
The index of refraction and the dispersion equation
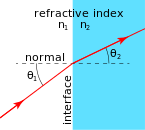
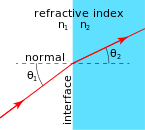
As I mentioned in my previous post, the Greeks had already found out, experimentally, what the index of refraction was. To be more precise, they had measured the θ1 and θ2 – depicted below – for light going from air to water. For example, if the angle in air (θ1) is 20°, then the angle in the water (θ2) will be 15°. It the angle in air is 70°, then the angle in the water will be 45°.
Of course, it should be noted that a lot of the light will also be reflected from the water surface (yes, imagine the romance of the image of the moon reflected on the surface of glacial lake while you’re feeling damn cold) – but so that’s a phenomenon which is better explained by introducing probability amplitudes, and looking at light as a bundle of photons, which we will not do here. I did that in previous posts, and so here, we will just acknowledge that there is a reflected beam but not say anything about it.
In any case, we should go step by step, and I am not doing that right now. Let’s first define the index of refraction. It is a number n which relates the angles above through the following relationship, which is referred to as Snell’s Law:
sinθ1 = n sinθ2
Using the numbers given above, we get: sin(20°) = n sin(15°), and sin(70°) = n sin(45°), so n must be equal to n = sin(20°)/sin(15°) = sin(70°)/sin(45°) ≈ 1.33. Just for the record, Willibrord Snell was a medieval Dutch astronomer but, according to Wikipedia, some smart Persian, Ibn Sahl, had already jotted this down in a treatise – “On Burning Mirrors and Lenses” – while he was serving the Abbasid court of Baghdad, back in 984, i.e. more than a thousand years ago! What to say? It was obviously a time when the Sunni-Shia divide did not matter, and Arabs and ‘Persians’ were leading civilization. I guess I should just salute the Islamic Golden Age here, regret the time lost during Europe’s Dark Ages and, most importantly, regret where Baghdad is right now ! And, as for the ‘burning’ adjective, it just refers to the fact that large convex lenses can concentrate the sun’s rays to a very small area indeed, thereby causing ignition. [It seems that story about Archimedes burning Roman ships with a ‘death ray’ using mirrors – in all likelihood: something that did not happen – fascinated them as well.]
But let’s get back at it. Where were we? Oh – yes – the refraction index. It’s (usually) a positive number written as n = 1 + some other number which may be positive or negative, and which depends on the properties of the material. To be more specific, it depends on the resonant frequencies of the atoms (or, to be precise, I should say: the resonant frequencies of the electrons bound by the atom, because it’s the charges that generate the radiation). Plus a whole bunch of natural constants that we have encountered already, most of which are related to electrons. Let me jot down the formula – and please don’t be scared away now (you can stop a bit later, but not now 🙂 please):

N is just the number of charges (electrons) per unit volume of the material (e.g. the water, or that block of plastic), and qe and m are just the charge and mass of the electron. And then you have that electric constant once again, ε0, and… Well, that’s it ! That’s not too terrible, is it? So the only variables on the right-hand side are ω0 and ω, so that’s (i) the resonant frequency of the material (or the atoms – well, the electrons bound to the nucleus, to be precise, but then you know what I mean and so I hope you’ll allow me to use somewhat less precise language from time to time) and (ii) the frequency of the incoming light.
The equation above is referred to as the dispersion relation. It’s easy to see why: it relates the frequency of the incoming light to the index of refraction which, in turn, determinates that angle θ. So the formula does indeed determine how light gets dispersed, as a function of the frequencies in it, by some medium indeed (glass, air, water,…).
So the objective of this post is to show how we can derive that dispersion relation using classical physics only. As usual, I’ll follow Feynman – arguably the best physics teacher ever. 🙂 Let me warn you though: it is not a simple thing to do. However, as mentioned above, it goes to the heart of the “classical world view” in physics and so I do think it’s worth the trouble. Before we get going, however, let’s look at the properties of that formula above, and relate it some experimental facts, in order to make sure we more or less understand what it is that we are trying to understand. 🙂
First, we should note that the index of refraction has nothing to do with transparency. In fact, throughout this post, we’ll assume that we’re looking at very transparent materials only, i.e. materials that do not absorb the electromagnetic radiation that tries to go through them, or only absorb it a tiny little bit. In reality, we will have, of course, some – or, in the case of opaque (i.e. non-transparent) materials, a lot – of absorption going on, but so we will deal with that later. So, let me repeat: the index of refraction has nothing to do with transparency. A material can have a (very) high index of refraction but be fully transparent. In fact, diamond is a case in point: it has one of the highest indexes of refraction (2.42) of any material that’s naturally available, but it’s – obviously – perfectly transparent. [In case you’re interested in jewellery, the refraction index of its most popular substitute, cubic zirconia, comes very close (2.15-2.18) and, moreover, zirconia actually works better as a prism, so its disperses light better than diamond, which is why it reflects more colors. Hence, real diamond actually sparkles less than zirconia! So don’t be fooled! :-)]
Second, it’s obvious that the index of refraction depends on two variables indeed: the natural, or resonant frequency, ω0, and the frequency ω, which is the frequency of the incoming light. For most of the ordinary gases, including those that make up air (i.e. nitrogen (78%) and oxygen (21%), plus some vapor (averaging 1%) and the so-called noble gas argon (0.93%) – noble because, just like helium and neon, it’s colorless, odorless and doesn’t react easily), the natural frequencies of the electron oscillators are close to the frequency of ultraviolet light. [The greenhouse gases are a different story – which is why we’re in trouble on this planet. Anyway…] So that’s why air absorbs most of the UV, especially the cancer-causing ultraviolet-C light (UVC), which is formally classified as a carcinogen by the World Health Organization. The wavelength of UVC light is 100 to 300 nanometer – as opposed to visible light, which has a wavelength ranging from 400 to 700 nm – and, hence, the frequency of UV light is in the 1000 to 3000 Teraherz range (1 THz = 1012 oscillations per second) – as opposed to visible light, which has a frequency in the range of 400 to 800 THz. So, because we’re squaring those frequencies in the formula, ω2 can then be disregarded in comparison with ω02: for example, 15002 = 2,250,000 and that’s not very different from 15002 – 5002 = 2,000,000. Hence, if we leave the ω2 out, we are still dividing by a very large number. That’s why n is very close to one for visible light entering the atmosphere from space (i.e. the vacuum). Its value is, in fact, around 1.000292 for incoming light with a wavelength of 589.3 nm (the odd value is the mean of so-called sodium D light, a pretty common yellow-orange light (street lights!), so that’s why it’s used as a reference value – however, don’t worry about it).
That being said, while the n of air is close to one for all visible light, the index is still slightly higher for blue light as compared to red light, and that’s why the sky is blue, except in the morning and evening, when it’s reddish. Indeed, the illustration below is a bit silly, but it gives you the idea. [I took this from http://mathdept.ucr.edu/ so I’ll refer you to that for the full narrative on that. :-)]

Where are we in this story? Oh… Yes. Two frequencies. So we should also note that – because we have two frequency variables – it also makes sense to talk about, for instance, the index of refraction of graphite (i.e. carbon in its most natural occurrence, like in coal) for x-rays. Indeed, coal is definitely not transparent to visible light (that has to do with the absorption phenomenon, which we’ll discuss later) but it is very ‘transparent’ to x-rays. Hence, we can talk about how graphite bends x-rays, for example. In fact, the frequency of x-rays is much higher than the natural frequency of the carbon atoms and, hence, in this case we can neglect the w02 factor, so we get a denominator that is negative (because only the -w2 remains relevant), so we get a refraction index that is (a bit) smaller than 1. [Of course, our body is transparent to x-rays too – to a large extent – but in different degrees, and that’s why we can take x-ray photographs of, for example, a broken rib or leg.]
OK. […] So that’s just to note that we can have a refraction index that is smaller than one and that’s not ‘anomalous’ – even if that’s a historical term that has survived.
Finally, last but not least as they say, you may have heard that scientists and engineers have managed to construct so-called negative index metamaterials. That matter is (much) more complicated than you might think, however, and so I’ll refer you to the Web if you want to find out more about that.
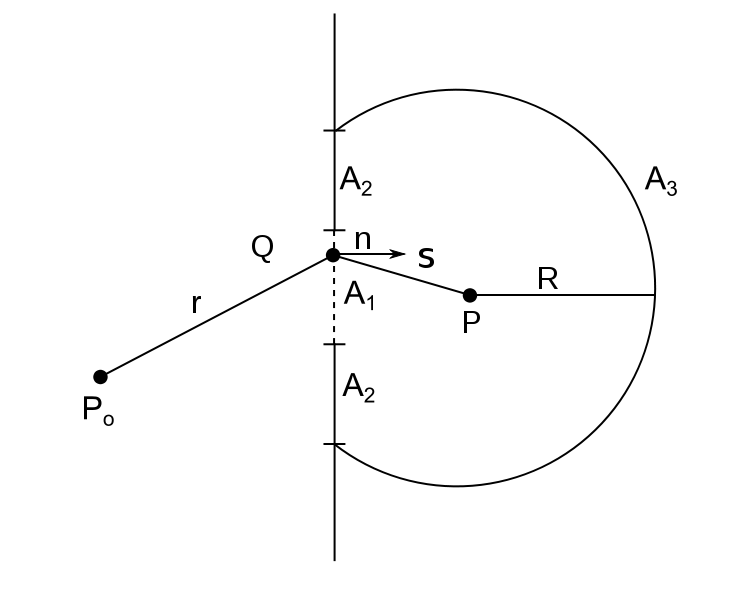
Light going through a glass plate: the classical idea
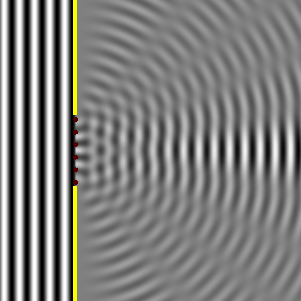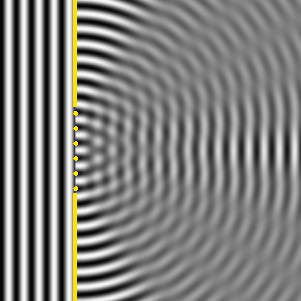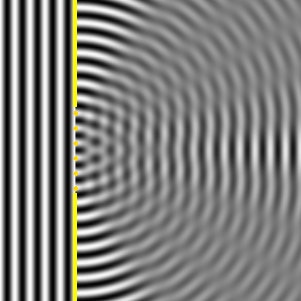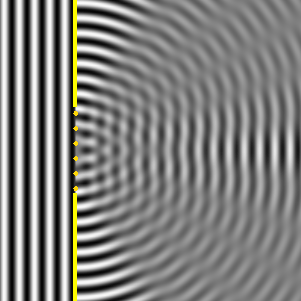
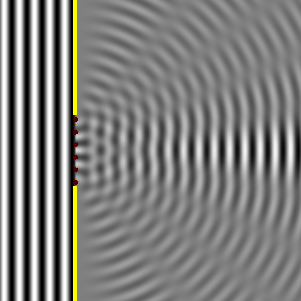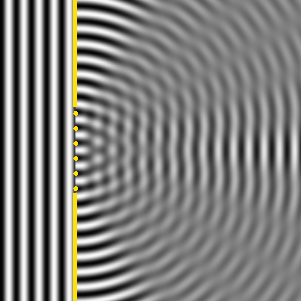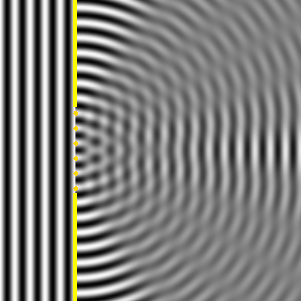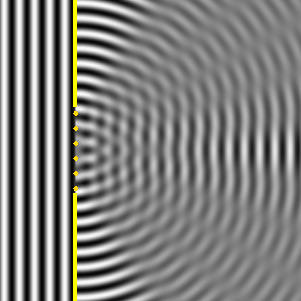
OK. We’re now ready to crack the nut. We’ll closely follow my ‘Great Teacher’ Feynman (Lectures, Vol. I-31) as he derives that formula above. Let me warn you again: the narrative below is quite complicated, but really worth the trouble – I think. The key to it all is the illustration below. The idea is that we have some electromagnetic radiation emanating from a far-away source hitting a glass plate – or whatever other transparent material. [Of course, nothing is to scale here: it’s just to make sure you get the theoretical set-up.]

So, as I explained in my previous post, the source creates an oscillating electromagnetic field which will shake the electrons up and down in the glass plate, and then these shaking electrons will generate their own waves. So we look at the glass as an assembly of little “optical-frequency radio stations” indeed, that are all driven with a given phase. It creates two new waves: one reflecting back, and one modifying the original field.
Let’s be more precise. What do we have here? First, we have the field that’s generated by the source, which is denoted by Es above. Then we have the “reflected” wave (or field – not much difference in practice), so that’s Eb. As mentioned above, this is the classical theory, not the quantum-electrodynamical one, so we won’t say anything about this reflection really: just note that the classical theory acknowledges that some of the light is effectively being reflected.
OK. Now we go to the other side of the glass. What do we expect to see there? If we would not have the glass plate in-between, we’d have the same Es field obviously, but so we don’t: there is a glass plate. 🙂 Hence, the “transmitted” wave, or the field that’s arriving at point P let’s say, will be different than Es. Feynman writes it as Es + Ea.
Hmm… OK. So what can we say about that? Not easy…
The index of refraction and the apparent speed of light in a medium
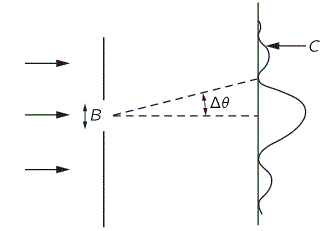
Snell’s Law – or Ibn Sahl’s Law – was re-formulated, by a 17th century French lawyer with an interesting in math and physics, Pierre de Fermat, as the Principle of Least Time. It is a way of looking at things really – but it’s very confusing actually. Fermat assumed that light traveling through a medium (water or glass, for instance) would travel slower, by a certain factor n, which – indeed – turns out to be the index of refraction. But let’s not run before we can walk. The Principle is illustrated below. If light has to travel from point S (the source) to point D (the detector), then the fastest way is not the straight line from S to D, but the broken S-L-D line. Now, I won’t go into the geometry of this but, with a bit of trial and error, you can verify for yourself that it turns out that the factor n will indeed be the same factor n as the one which was ‘discovered’ by Ibn Sahl: sinθ1 = n sinθ2.

What we have then, is that the apparent speed of the wave in the glass plate that we’re considering here will be equal to v = c/n. The apparent speed? So does that mean it is not the real speed? Hmm… That’s actually the crux of the matter. The answer is: yes and no. What? An ambiguous answer in physics? Yes. It’s ambiguous indeed. What’s the speed of a wave? We mentioned above that n could be smaller than one. Hence, in that case, we’d have a wave traveling faster than the speed of light. How can we make sense of that?
We can make sense of that by noting that the wave crests or nodes may be traveling faster than c, but that the wave itself – as a signal – cannot travel faster than light. It’s related to what we said about the difference between the group and phase velocity of a wave. The phase velocity – i.e. the nodes, which are mathematical points only – can travel faster than light, but the signal as such, i.e. the wave envelope in the illustration below, cannot.

What is happening really is the following. A wave will hit one of these electron oscillators and start a so-called transient, i.e. a temporary response preceding the ‘steady state’ solution (which is not steady but dynamic – confusing language once again – so sorry!). So the transient settles down after a while and then we have an equilibrium (or steady state) oscillation which is likely to be out of phase with the driving field. That’s because there is damping: the electron oscillators resist before they go along with the driving force (and they continue to put up resistance, so the oscillation will die out when the driving force stops!). The illustration below shows how it works for the various cases:

In case (b), the phase of the transmitted wave will appear to be delayed, which results in the wave appearing to travel slower, because the distance between the wave crests, i.e. the wavelength λ, is being shortened. In case (c), it’s the other way around: the phase appears to be advanced, which translated into a bigger distance between wave crests, or a lengthening of the wavelength, which translates into an apparent higher speed of the transmitted wave.
So here we just have a mathematical relationship between the (apparent) speed of a wave and its wavelength. The wavelength is the (apparent) speed of the wave (that’s the speed with which the nodes of the wave travel through space, or the phase velocity) divided by the frequency: λ = vp/f. However, from the illustration above, it is obvious that the signal, i.e. the start of the wave, is not earlier – or later – for either wave (b) and (c). In fact, the start of the wave, in time, is exactly the same for all three cases. Hence, the electromagnetic signal travels at the same speed c, always.
While this may seem obvious, it’s quite confusing, and therefore I’ll insert one more illustration below. What happens when the various wave fronts of the traveling field hit the glass plate (coming from the top-left hand corner), let’s say at time t = t0, as shown below, is that the wave crests will have the same spacing along the surface. That’s obvious because we have a regular wave with a fixed frequency and, hence, a fixed wavelength λ0, here. Now, these wave crests must also travel together as the wave continues its journey through the glass, which is what is shown by the red and green arrows below: they indicate where the wave crest is after one and two periods (T and 2T) respectively.
To understand what’s going on, you should note that the frequency f of the wave that is going through the glass sheet and, hence, its period T, has not changed. Indeed, the driven oscillation, which was illustrated for the two possible cases above (n > 1 and n < 1), after the transient has settled down, has the same frequency (f) as the driving source. It must. Always. That being said, the driven oscillation does have that phase delay (remember: we’re in the (b) case here, but we can make a similar analysis for the (c) case). In practice, that means that the (shortest) distance between the crests of the wave fronts at time t = t0 and the crests at time t0 + T will be smaller. Now, the (shortest) distance between the crests of a wave is, obviously, the wavelength divided by the frequency: λ = vp/f, with vp the speed of propagation, i.e. the phase velocity, of the wave, and f = 1/T. [The frequency f is the reciprocal of the period T – always. When studying physics, I found out it’s useful to keep track of a few relationships that hold always, and so this is one of them. :-)]
Now, the frequency is the same, but so the wavelength is shortened as the wave travels through the various layers of electron oscillators, each causing a delay of phase – and, hence, a shortening of the wavelength, as shown above. But, if f is the same, and the wavelength is shorter, then vp cannot be equal to the speed of the incoming light, so vp ≠ c. The apparent speed of the wave traveling through the glass, and the associated shortening of the wavelength, can be calculated using Snell’s Law. Indeed, knowing that n ≈ 1.33, we can calculate the apparent speed of light through the glass as v = c/n ≈ 0.75c and, therefore, we can calculate the wavelength of the wave in the glass l as λ = 0.75λ0.
OK. I’ve been way too lengthy here. Let’s sum it all up:
- The field in the glass sheet must have the shape that’s depicted above: there is no other way. So that means the direction of ‘propagation’ has been changed. As mentioned above, however, the direction of propagation is a ‘mathematical’ property of the field: it’s not the speed of the ‘signal’.
- Because the direction of propagation is normal to the wave front, it implies that the bending of light rays comes about because the effective speed of the waves is different in the various materials or, to be even more precise, because the electron oscillators cause a delay of phase.
- While the speed and direction of propagation of the wave, i.e. the phase velocity, accurately describes the behavior of the field, it is not the speed with which the signal is traveling (see above). That is why it can be larger or smaller than c, and so it should not raise any eyebrow. For x-rays in particular, we have a refractive index smaller than one. [It’s only slightly less than one, though, and, hence, x-ray images still have a very good resolution. So don’t worry about your doctor getting a bad image of your broken leg. 🙂 In case you want to know more about this: just Google x-ray optics, and you’ll find loads of information. :-)]
Calculating the field
Are you still there? Probably not. If you are, I am afraid you won’t be there ten or twenty minutes from now. Indeed, you ain’t done nothing yet. All of the above was just setting the stage: we’re now ready for the pièce de résistance, as they say in French. We’re back at that illustration of the glass plate and the various fields in front and behind the plate. So we have electron oscillators in the glass plate. Indeed, as Feynman notes: “As far as problems involving light are concerned, the electrons behave as though they were held by springs. So we shall suppose that the electrons have a linear restoring force which, together with their mass m, makes them behave like little oscillators, with a resonant frequency ω0.”
So here we go:
1. From everything I wrote about oscillators in previous posts, you should remember that the equation for this motion can be written as m[d2x/dt2 + ω02) = F. That’s just Newton’s Law. Now, the driving force F comes from the electric field and will be equal to F = qeEs.
Now, we assume that we can chose the origin of time (i.e. the moment from which we start counting) such that the field Es = E0cos(ωt). To make calculations easier, we look at this as the real part of a complex function Es = E0eiωt. So we get:
m[d2x/dt2 + ω02] = qeE0eiωt
We’ve solved this before: its solution is x = x0eiωt. We can just substitute this in the equation above to find x0 (just substitute and take the first- and then second-order derivative of x indeed): x0 = qeE0/m(ω02-ω2). That, then, gives us the first piece in this lengthy derivation:
x = qeE0eiωt/m(ω02 -ω2)
Just to make sure you understand what we’re doing: this piece gives us the motion of the electrons in the plate. That’s all.
2. Now, we need an equation for the field produced by a plane of oscillating charges, because that’s what we’ve got here: a plate or a plane of oscillating charges. That’s a complicated derivation in its own, which I won’t do there. I’ll just refer to another chapter of Feynman’s Lectures (Vol. I-30-7) and give you the solution for it (if I wouldn’t do that, this post would be even longer than it already is):
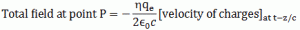
This formula introduces just one new variable, η, which is the number of charges per unit area of the plate (as opposed to N, which was the number of charges per unit volume in the plate), so that’s quite straightforward. Less straightforward is the formula itself: this formula says that the magnitude of the field is proportional to the velocity of the charges at time t – z/c, with z the shortest distance from P to the plane of charges. That’s a bit odd, actually, but so that’s the way it comes out: “a rather simple formula”, as Feynman puts it.
In any case, let’s use it. Differentiating x to get the velocity of the charges, and plugging it into the formula above yields:

Note that this is only Ea, the additional field generated by the oscillating charges in the glass plate. To get the total electric field at P, we still have to add Es, i.e. the field generated by the source itself. This may seem odd, because you may think that the glass plate sort of ‘shields’ the original field but, no, as Feynman puts it: “The total electric field in any physical circumstance is the sum of the fields from all the charges in the universe.”
3. As mentioned above, z is the distance from P to the plate. Let’s look at the set-up here once again. The transmitted wave, or Eafter the plate as we shall note it, consists of two components: Es and Ea. Es here will be equal to (the real part of) Es = E0eiω(t-z/c). Why t – z/c instead of just t? Well… We’re looking at Es here as measured in P, not at Es at the glass plate itself.
Now, we know that the wave ‘travels slower’ through the glass plate (in the sense that its phase velocity is less, as should be clear from the rather lengthy explanation on phase delay above, or – if n would be greater than one – a phase advance). So if the glass plate is of thickness Δz, and the phase velocity is is v = c/n, then the time it will take to travel through the glass plate will be Δz/(c/n) instead of Δz/c (speed is distance divided by time and, hence, time = distance divided by speed). So the additional time that is needed is Δt = Δz/(c/n) – Δz/c = nΔz/c – Δz/c = (n-1)Δz/c. That, then, implies that Eafter the plate is equal to a rather monstrously looking expression:
Eafter plate = E0eiω[t – (n–1)Δz/c – z/c) = e–iω(n–1)Δz/c)E0eiω(t – z/c)
We get this by just substituting t for t – Δt.
So what? Well… We have a product of two complex numbers here and so we know that this involves adding angles – or substracting angles in this case, rather, because we’ve got a minus sign in the exponent of the first factor. So, all that we are saying here is that the insertion of the glass plate retards the phase of the field with an amount equal to w(n-1)Δz/c. What about that sum Eafter the plate = Es + Ea that we were supposed to get?
Well… We’ll use the formula for a first-order (linear) approximation of an exponential once again: ex ≈ 1 + x. Yes. We can do that because Δz is assumed to be very small, infinitesimally small in fact. [If it is not, then we’ll just have to assume that the plate consists of a lot of very thin plates.] So we can write that e–iω(n-1)Δz/c) = 1 – iω(n-1)Δz/c, and then we, finally, get that sum we wanted:
Eafter plate = E0eiω[t – z/c) − iω(n-1)Δz·E0eiω(t – z/c)/c
The first term is the original Es field, and the second term is the Ea field. Geometrically, they can be represented as follows:
Why is Ea perpendicular to Es? Well… Look at the –i = 1/i factor. Multiplication with –i amounts to a clockwise rotation by 90°, and then just note that the magnitude of the vector must be small because of the ω(n-1)Δz/c factor.
4. By now, you’ve either stopped reading (most probably) or, else, you wonder what I am getting at. Well… We have two formulas for Ea now:

and Ea = – iω(n-1)Δz·E0eiω(t – z/c)/c
Equating both yields:

But η, the number of charges per unit area, must be equal to NΔz, with N the number of charges per unit volume. Substituting and then cancelling the Δz finally gives us the formula we wanted, and that’s the classical dispersion relation whose properties we explored above:
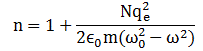
Absorption and the absorption index
The model we used to explain the index of refraction had electron oscillators at its center. In the analysis we did, we did not introduce any damping factor. That’s obviously not correct: it means that a glass plate, once it had illuminated, would continue to emit radiation, because the electrons would oscillate forever. When introducing damping, the denominator in our dispersion relation becomes m(ω02 – ω2 + iγω), instead of m(ω02 – ω2). We derived this in our posts on oscillators. What it means is that the oscillator continues to oscillate with the same frequency as the driving force (i.e. not its natural frequency) – so that doesn’t change – but that there is an envelope curve, ensuring the oscillation dies out when the driving force is no longer being applied. The γ factor is the damping factor and, hence, determines how fast the damping happens.
We can see what it means by writing the complex index of refraction as n = n’ – in’’, with n’ and n’’ real numbers, describing the real and imaginary part of n respectively. Putting that complex n in the equation for the electric field behind the plate yields:
Eafter plate = e–ωn’’Δz/ce–iω(n’–1)Δz/cE0eiω(t – z/c)
This is the same formula that we had derived already, but so we have an extra exponential factor: e–ωn’’Δz/c. It’s an exponential factor with a real exponent, because there were two i‘s that cancelled. The e-x function has a familiar shape (see below): e-x is 1 for x = 0, and between 0 and 1 for any value in-between. That value will depend on the thickness of the glass sheet. Hence, it is obvious that the glass sheet weakens the wave as it travels through it. Hence, the wave must also come out with less energy (the energy being proportional to the square of the amplitude). That’s no surprise: the damping we put in for the electron oscillators is a friction force and, hence, must cause a loss of energy.
Note that it is the n’’ term – i.e. the imaginary part of the refractive index n – that determines the degree of absorption (or attenuation, if you want). Hence, n’’ is usually referred to as the “absorption index”.
The complete dispersion relation
We need to add one more thing in order to get a fully complete dispersion relation. It’s the last thing: then we have a formula which can really be used to describe real-life phenomena. The one thing we need to add is that atoms have several resonant frequencies – even an atom with only one electron, like hydrogen ! In addition, we’ll usually want to take into account the fact that a ‘material’ actually consists of various chemical substances, so that’s another reason to consider more than one resonant frequency. The formula is easily derived from our first formula (see the previous post), when we assumed there was only one resonant frequency. Indeed, when we have Nk electrons per unit of volume, whose natural frequency is ωk and whose damping factor is γk, then we can just add the contributions of all oscillators and write:

The index described by this formula yields the following curve:
So we have a curve with a positive slope, and a value n > 1, for most frequencies, except for a very small range of ω’s for which the slope is negative, and for which the index of refraction has a value n < 1. As Feynman notes, these ω’s– and the negative slope – is sometimes referred to as ‘anomalous’ dispersion but, in fact, there’s nothing ‘abnormal’ about it.
The interesting thing is the iγkω term in the denominator, i.e. the imaginary component of the index, and how that compares with the (real) “resonance term” ωk2– ω2. If the resonance term becomes very small compared to iγkω, then the index will become almost completely imaginary, which means that the absorption effect becomes dominant. We can see that effect in the spectrum of light that we receive from the sun: there are ‘dark lines’, i.e. frequencies that have been strongly absorbed at the resonant frequencies of the atoms in the Sun and its ‘atmosphere’, and that allows us to actually tell what the Sun’s ‘atmosphere’ (or that of other stars) actually consists of.
So… There we are. I am aware of the fact that this has been the longest post of all I’ve written. I apologize. But so it’s quite complete now. The only piece that’s missing is something on energy and, perhaps, some more detail on these electron oscillators. But I don’t think that’s so essential. It’s time to move on to another topic, I think.
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/




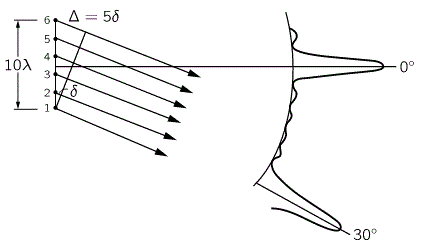
 Hence, if S0 is the action for r0, then S1 = S0 + ħ and S2 = S0 + 2·ħ are still good, but S3 = S0 + 3·ħ is not good. Why? Because the difference in the phase angles is Δθ = S1/ħ − S0/ħ = (S0 + ħ)/ħ − S0/ħ = 1 and Δθ = S2/ħ − S0/ħ = (S0 + 2·ħ)/ħ − S0/ħ = 2 respectively, so that’s 57.3° and 114.6° respectively and that’s, effectively, less than 120°. In contrast, for the next path, we find that Δθ = S3/ħ − S0/ħ = (S0 + 3·ħ)/ħ − S0/ħ = 3, so that’s 171.9°. So that amplitude gives us a negative contribution.
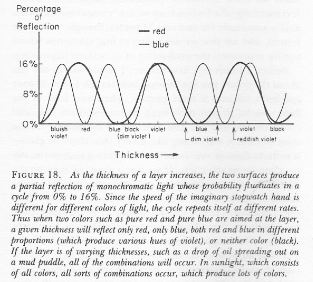
Hence, if S0 is the action for r0, then S1 = S0 + ħ and S2 = S0 + 2·ħ are still good, but S3 = S0 + 3·ħ is not good. Why? Because the difference in the phase angles is Δθ = S1/ħ − S0/ħ = (S0 + ħ)/ħ − S0/ħ = 1 and Δθ = S2/ħ − S0/ħ = (S0 + 2·ħ)/ħ − S0/ħ = 2 respectively, so that’s 57.3° and 114.6° respectively and that’s, effectively, less than 120°. In contrast, for the next path, we find that Δθ = S3/ħ − S0/ħ = (S0 + 3·ħ)/ħ − S0/ħ = 3, so that’s 171.9°. So that amplitude gives us a negative contribution. Well… We get a weird result. It reminds me of Feynman’s explanation of the partial reflection of light, shown below, but… Well… That doesn’t make much sense, does it?
Well… We get a weird result. It reminds me of Feynman’s explanation of the partial reflection of light, shown below, but… Well… That doesn’t make much sense, does it?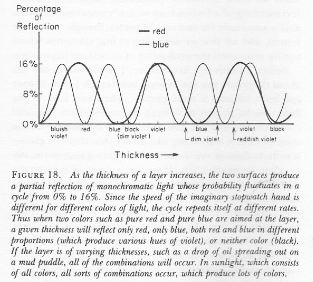

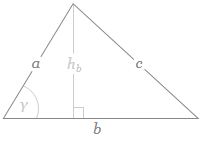 If b is the straight-line path (r0), then ac could be one of the crooked paths (rn). To simplify, we’ll assume isosceles triangles, so a equals c and, hence, rn = 2·a = 2·c. We will also assume the successive paths are separated by the same vertical distance (h = h1) right in the middle, so hb = hn = n·h1. It is then easy to show the following:
If b is the straight-line path (r0), then ac could be one of the crooked paths (rn). To simplify, we’ll assume isosceles triangles, so a equals c and, hence, rn = 2·a = 2·c. We will also assume the successive paths are separated by the same vertical distance (h = h1) right in the middle, so hb = hn = n·h1. It is then easy to show the following:
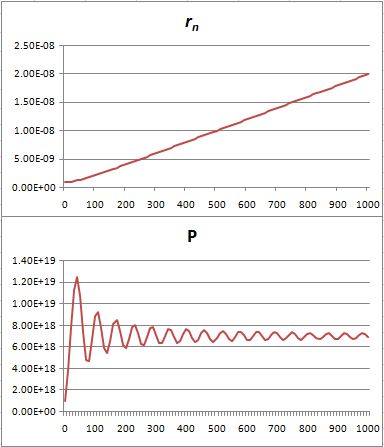
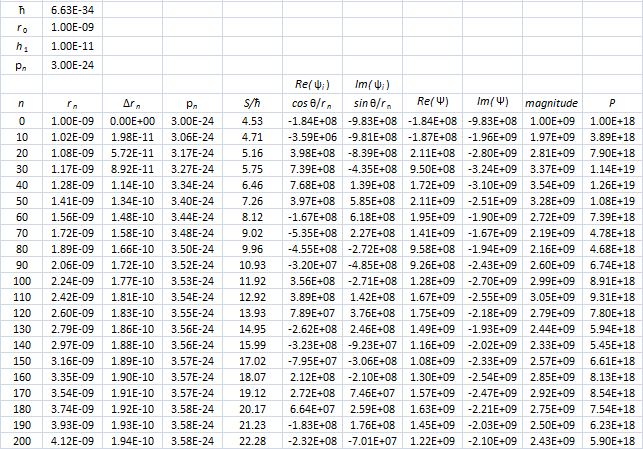
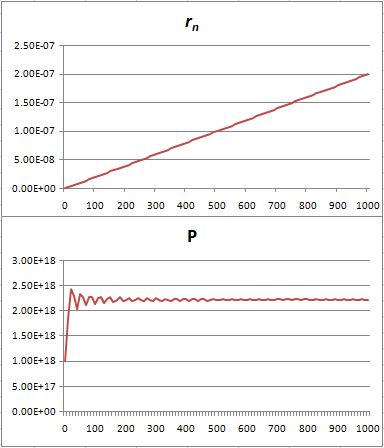

 That’s because we increase the weight of the paths that are further removed from the center. So… Well… We shouldn’t be doing that, I guess. 🙂 I’ll you look for the right formula, OK? Let me know when you found it. 🙂
That’s because we increase the weight of the paths that are further removed from the center. So… Well… We shouldn’t be doing that, I guess. 🙂 I’ll you look for the right formula, OK? Let me know when you found it. 🙂