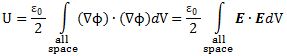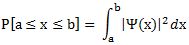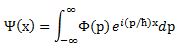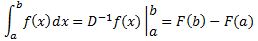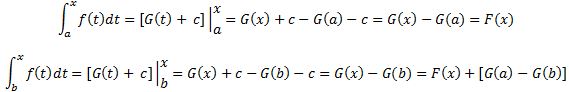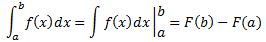Pre-scriptum (dated 26 June 2020): A quick glance at this piece – so many years after I have written it – tells me it is basically OK. However, it is quite obvious that, in terms of interpreting the math, I have come a very long way. However, I would recommend you go through the piece so as to get the basic math, indeed, and then you may or may not be ready for the full development of my realist or classical interpretation of QM. My manuscript may also be a fun read for you.
Original post:
After all those boring pieces on math, it is about time I got back to physics. Indeed, what’s all that stuff on differential equations and complex numbers good for? This blog was supposed to be a journey into physics, wasn’t it? Yes. But wave functions – functions describing physical waves (in classical mechanics) or probability amplitudes (in quantum mechanics) – are the solution to some differential equation, and they will usually involve complex-number notation. However, I agree we have had enough of that now. Let’s see how it works. By the way, the title of this post – An Easy Piece – is an obvious reference to (some of) Feynman’s 1965 Lectures on Physics, some of which were re-packaged in 1994 (six years after his death that is) in ‘Six Easy Pieces’ indeed – but, IMHO, it makes more sense to read all of them as part of the whole series.
Let’s first look at one of the most used mathematical shapes: the sinusoidal wave. The illustration below shows the basic concepts: we have a wave here – some kind of cyclic thing – with a wavelength λ, an amplitude (or height) of (maximum) A0, and a so-called phase shift equal to φ. The Wikipedia definition of a wave is the following: “a wave is a disturbance or oscillation that travels through space and matter, accompanied by a transfer of energy.” Indeed, a wave transports energy as it travels (oh – I forgot to mention the speed or velocity of a wave (v) as an important characteristic of a wave), and the energy it carries is directly proportional to the square of the amplitude of the wave: E ∝ A2 (this is true not only for waves like water waves, but also for electromagnetic waves, like light).

Let’s now look at how these variables get into the argument – literally: into the argument of the wave function. Let’s start with that phase shift. The phase shift is usually defined referring to some other wave or reference point (in this case the origin of the x and y axis). Indeed, the amplitude – or ‘height’ if you want (think of a water wave, or the strength of the electric field) – of the wave above depends on (1) the time t (not shown above) and (2) the location (x), but so we will need to have this phase shift φ in the argument of the wave function because at x = 0 we do not have a zero height for the wave. So, as we can see, we can shift the x-axis left or right with this φ. OK. That’s simple enough. Let’s look at the other independent variables now: time and position.
The height (or amplitude) of the wave will obviously vary both in time as well as in space. On this graph, we fixed time (t = 0) – and so it does not appear as a variable on the graph – and show how the amplitude y = A varies in space (i.e. along the x-axis). We could also have looked at one location only (x = 0 or x1 or whatever other location) and shown how the amplitude varies over time at that location only. The graph would be very similar, except that we would have a ‘time distance’ between two crests (or between two troughs or between any other two points separated by a full cycle of the wave) instead of the wavelength λ (i.e. a distance in space). This ‘time distance’ is the time needed to complete one cycle and is referred to as the period of the wave (usually denoted by the symbol T or T0 – in line with the notation for the maximum amplitude A0). In other words, we will also see time (t) as well as location (x) in the argument of this cosine or sine wave function. By the way, it is worth noting that it does not matter if we use a sine or cosine function because we can go from one to the other using the basic trigonometric identities cos θ = sin(π/2 – θ) and sin θ = cos(π/2 – θ). So all waves of the shape above are referred to as sinusoidal waves even if, in most cases, the convention is to actually use the cosine function to represent them.
So we will have x, t and φ in the argument of the wave function. Hence, we can write A = A(x, t, φ) = cos(x + t + φ) and there we are, right? Well… No. We’re adding very different units here: time is measured in seconds, distance in meter, and the phase shift is measured in radians (i.e. the unit of choice for angles). So we can’t just add them up. The argument of a trigonometric function (like this cosine function) is an angle and, hence, we need to get everything in radians – because that’s the unit we use to measure angles. So how do we do that? Let’s do it step by step.
First, it is worth noting that waves are usually caused by something. For example, electromagnetic waves are caused by an oscillating point charge somewhere, and radiate out from there. Physical waves – like water waves, or an oscillating string – usually also have some origin. In fact, we can look at a wave as a way of transmitting energy originating elsewhere. In the case at hand here – i.e. the nice regular sinusoidal wave illustrated above – it is obvious that the amplitude at some time t = t1 at some point x = x1 will be the same as the amplitude of that wave at point x = 0 some time ago. How much time ago? Well… The time (t0 ) that was needed for that wave to travel from point x = 0 to point x = x1 is easy to calculate: indeed, if the wave originated at t = 0 and x = 0, then x1 (i.e. the distance traveled by the wave) will be equal to its velocity (v) multiplied by t1, so we have x1= v.t1 (note that we assume the wave velocity is constant – which is a very reasonable assumption). In other words, inserting x1and t1 in the argument of our cosine function should yield the same value as inserting zero for x and t. Distance and time can be substituted so to say, and that’s we will have something like x – vt or vt – x in the argument in that cosine function: we measure both time and distance in units of distance so to say. [Note that x – vt and –(x-vt) = vt – x are equivalent because cos θ = cos (-θ)]
Does this sound fishy? It shouldn’t. Think about it. In the (electric) field equation for electromagnetic radiation (that’s one of the examples of a wave which I mentioned above), you’ll find the so-called retarded acceleration a(t – x/c) in the argument: that’s the acceleration (a)of the charge causing the electric field at point x to change not at time t but at time t – x/c. So that’s the retarded acceleration indeed: x/c is the time it took for the wave to travel from its origin (the oscillating point charge) to x and so we subtract that from t. [When talking electromagnetic radiation (e.g. light), the wave velocity v is obviously equal to c, i.e. the speed of light, or of electromagnetic radiation in general.] Of course, you will now object that t – x/c is not the same as vt – x, and you are right: we need time units in the argument of that acceleration function, not distance. We can get to distance units if we would multiply the time with the wave velocity v but that’s complicated business because the velocity of that moving point charge is not a constant.
[…] I am not sure if I made myself clear here. If not, so be it. The thing to remember is that we need an input expressed in radians for our cosine function, not time, nor distance. Indeed, the argument in a sine or cosine function is an angle, not some distance. We will call that angle the phase of the wave, and it is usually denoted by the symbol θ – which we also used above. But so far we have been talking about amplitude as a function of distance, and we expressed time in distance units too – by multiplying it with v. How can we go from some distance to some angle? It is simple: we’ll multiply x – vt with 2π/λ.
Huh? Yes. Think about it. The wavelength will be expressed in units of distance – typically 1 m in the SI International System of Units but it could also be angstrom (10–10 m = 0.1 nm) or nano-meter (10–9 m = 10 Å). A wavelength of two meter (2 m) means that the wave only completes half a cycle per meter of travel. So we need to translate that into radians, which – once again – is the measure used to… well… measure angles, or the phase of the wave as we call it here. So what’s the ‘unit’ here? Well… Remember that we can add or subtract 2π (and any multiple of 2π, i.e. ± 2nπ with n = ±1, ±2, ±3,…) to the argument of all trigonometric functions and we’ll get the same value as for the original argument. In other words, a cycle characterized by a wavelength λ corresponds to the angle θ going around the origin and describing one full circle, i.e. 2π radians. Hence, it is easy: we can go from distance to radians by multiplying our ‘distance argument’ x – vt with 2π/λ. If you’re not convinced, just work it out for the example I gave: if the wavelength is 2 m, then 2π/λ equals 2π/2 = π. So traveling 6 meters along the wave – i.e. we’re letting x go from 0 to 6 m while fixing our time variable – corresponds to our phase θ going from 0 to 6π: both the ‘distance argument’ as well as the change in phase cover three cycles (three times two meter for the distance, and three times 2π for the change in phase) and so we’re fine. [Another way to think about it is to remember that the circumference of the unit circle is also equal to 2π (2π·r = 2π·1 in this case), so the ratio of 2π to λ measures how many times the circumference contains the wavelength.]
In short, if we put time and distance in the (2π/λ)(x-vt) formula, we’ll get everything in radians and that’s what we need for the argument for our cosine function. So our sinusoidal wave above can be represented by the following cosine function:
A = A(x, t) = A0cos[(2π/λ)(x-vt)]
We could also write A = A0cosθ with θ = (2π/λ)(x-vt). […] Both representations look rather ugly, don’t they? They do. And it’s not only ugly: it’s not the standard representation of a sinusoidal wave either. In order to make it look ‘nice’, we have to introduce some more concepts here, notably the angular frequency and the wave number. So let’s do that.
The angular frequency is just like the… well… the frequency you’re used to, i.e. the ‘non-angular’ frequency f, as measured in cycles per second (i.e. in Hertz). However, instead of measuring change in cycles per second, the angular frequency (usually denoted by the symbol ω) will measure the rate of change of the phase with time, so we can write or define ω as ω = ∂θ/∂t. In this case, we can easily see that ω = –2πv/λ. [Note that we’ll take the absolute value of that derivative because we want to work with positive numbers for such properties of functions.] Does that look complicated? In doubt, just remember that ω is measured in radians per second and then you can probably better imagine what it is really. Another way to understand ω somewhat better is to remember that the product of ω and the period T is equal to 2π, so that’s a full cycle. Indeed, the time needed to complete one cycle multiplied with the phase change per second (i.e. per unit time) is equivalent to going round the full circle: 2π = ω.T. Because f = 1/T, we can also relate ω to f and write ω = 2π.f = 2π/T.
Likewise, we can measure the rate of change of the phase with distance, and that gives us the wave number k = ∂θ/∂x, which is like the spatial frequency of the wave. So it is just like the wavelength but then measured in radians per unit distance. From the function above, it is easy to see that k = 2π/λ. The interpretation of this equality is similar to the ω.T = 2π equality. Indeed, we have a similar equation for k: 2π = k.λ, so the wavelength (λ) is for k what the period (T) is for ω. If you’re still uncomfortable with it, just play a bit with some numerical examples and you’ll be fine.
To make a long story short, this, then, allows us to re-write the sinusoidal wave equation above in its final form (and let me include the phase shift φ again in order to be as complete as possible at this stage):
A(x, t) = A0cos(kx – ωt + φ)
You will agree that this looks much ‘nicer’ – and also more in line with what you’ll find in textbooks or on Wikipedia. 🙂 I should note, however, that we’re not adding any new parameters here. The wave number k and the angular frequency ω are not independent: this is still the same wave (A = A0cos[(2π/λ)(x-vt)]), and so we are not introducing anything more than the frequency and – equally important – the speed with which the wave travels, which is usually referred to as the phase velocity. In fact, it is quite obvious from the ω.T = 2π and the k = 2π/λ identities that kλ = ω.T and, hence, taking into account that λ is obviously equal to λ = v.T (the wavelength is – by definition – the distance traveled by the wave in one period), we find that the phase (or wave) velocity v is equal to the ratio of ω and k, so we have that v = ω/k. So x, t, ω and k could be re-scaled or so but their ratio cannot change: the velocity of the wave is what it is. In short, I am introducing two new concepts and symbols (ω and k) but there are no new degrees of freedom in the system so to speak.
[At this point, I should probably say something about the difference between the phase velocity and the so-called group velocity of a wave. Let me do that in as brief a way as I can manage. Most real-life waves travel as a wave packet, aka a wave train. So that’s like a burst, or an “envelope” (I am shamelessly quoting Wikipedia here…), of “localized wave action that travels as a unit.” Such wave packet has no single wave number or wavelength: it actually consists of a (large) set of waves with phases and amplitudes such that they interfere constructively only over a small region of space, and destructively elsewhere. The famous Fourier analysis (or infamous if you have problems understanding what it is really) decomposes this wave train in simpler pieces. While these ‘simpler’ pieces – which, together, add up to form the wave train – are all ‘nice’ sinusoidal waves (that’s why I call them ‘simple’), the wave packet as such is not. In any case (I can’t be too long on this), the speed with which this wave train itself is traveling through space is referred to as the group velocity. The phase velocity and the group velocity are usually very different: for example, a wave packet may be traveling forward (i.e. its group velocity is positive) but the phase velocity may be negative, i.e. traveling backward. However, I will stop here and refer to the Wikipedia article on group and phase velocity: it has wonderful illustrations which are much and much better than anything I could write here. Just one last point that I’ll use later: regardless of the shape of the wave (sinusoidal, sawtooth or whatever), we have a very obvious relationship relating wavelength and frequency to the (phase) velocity: v = λ.f, or f = v/λ. For example, the frequency of a wave traveling 3 meter per second and wavelength of 1 meter will obviously have a frequency of three cycles per second (i.e. 3 Hz). Let’s go back to the main story line now.]
With the rather lengthy ‘introduction’ to waves above, we are now ready for the thing I really wanted to present here. I will go much faster now that we have covered the basics. Let’s go.
From my previous posts on complex numbers (or from what you know on complex numbers already), you will understand that working with cosine functions is much easier when writing them as the real part of a complex number A0eiθ = A0ei(kx – ωt + φ). Indeed, A0eiθ = A0(cosθ + isinθ) and so the cosine function above is nothing else but the real part of the complex number A0eiθ. Working with complex numbers makes adding waves and calculating interference effects and whatever we want to do with these wave functions much easier: we just replace the cosine functions by complex numbers in all of the formulae, solve them (algebra with complex numbers is very straightforward), and then we look at the real part of the solution to see what is happening really. We don’t care about the imaginary part, because that has no relationship to the actual physical quantities – for physical and electromagnetic waves that is, or for any other problem in classical wave mechanics. Done. So, in classical mechanics, the use of complex numbers is just a mathematical tool.
Now, that is not the case for the wave functions in quantum mechanics: the imaginary part of a wave equation – yes, let me write one down here – such as Ψ = Ψ(x, t) = (1/x)ei(kx – ωt) is very much part and parcel of the so-called probability amplitude that describes the state of the system here. In fact, this Ψ function is an example taken from one of Feynman’s first Lectures on Quantum Mechanics (i.e. Volume III of his Lectures) and, in this case, Ψ(x, t) = (1/x)ei(kx – ωt) represents the probability amplitude of a tiny particle (e.g. an electron) moving freely through space – i.e. without any external forces acting upon it – to go from 0 to x and actually be at point x at time t. [Note how it varies inversely with the distance because of the 1/x factor, so that makes sense.] In fact, when I started writing this post, my objective was to present this example – because it illustrates the concept of the wave function in quantum mechanics in a fairly easy and relatively understandable way. So let’s have a go at it.
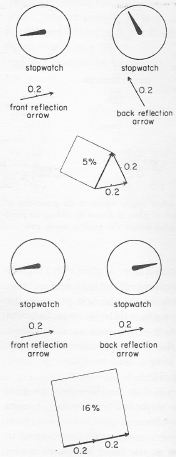
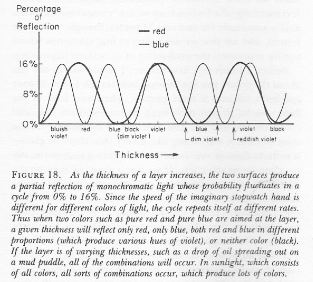
First, it is necessary to understand the difference between probabilities and probability amplitudes. We all know what a probability is: it is a real number between o and 1 expressing the chance of something happening. It is usually denoted by the symbol P. An example is the probability that monochromatic light (i.e. one or more photons with the same frequency) is reflected from a sheet of glass. [To be precise, this probability is anything between 0 and 16% (i.e. P = 0 to 0.16). In fact, this example comes from another fine publication of Richard Feynman – QED (1985) – in which he explains how we can calculate the exact probability, which depends on the thickness of the sheet.]
A probability amplitude is something different. A probability amplitude is a complex number (3 + 2i, or 2.6ei1.34, for example) and – unlike its equivalent in classical mechanics – both the real and imaginary part matter. That being said, probabilities and probability amplitudes are obviously related: to be precise, one calculates the probability of an event actually happening by taking the square of the modulus (or the absolute value) of the probability amplitude associated with that event. Huh? Yes. Just let it sink in. So, if we denote the probably amplitude by Φ, then we have the following relationship:
P =|Φ|2
P = probability
Φ = probability amplitude
In addition, where we would add and multiply probabilities in the classical world (for example, to calculate the probability of an event which can happen in two different ways – alternative 1 and alternative 2 let’s say – we would just add the individual probabilities to arrive at the probably of the event happening in one or the other way, so P = P1+ P2), in the quantum-mechanical world we should add and multiply probability amplitudes, and then take the square of the modulus of that combined amplitude to calculate the combined probability. So, formally, the probability of a particle to reach a given state by two possible routes (route 1 or route 2 let’s say) is to be calculated as follows:
Φ = Φ1+ Φ2
and P =|Φ|2 =|Φ1+ Φ2|2
Also, when we have only one route, but that one route consists of two successive stages (for example: to go from A to C, the particle would have first have to go from A to B, and then from B to C, with different probabilities of stage AB and stage BC actually happening), we will not multiply the probabilities (as we would do in the classical world) but the probability amplitudes. So we have:
Φ = ΦAB ΦBC
and P =|Φ|2 =|ΦAB ΦBC|2
In short, it’s the probability amplitudes (and, as mentioned, these are complex numbers, not real numbers) that are to be added and multiplied etcetera and, hence, the probability amplitudes act as the equivalent, so to say, in quantum mechanics, of the conventional probabilities in classical mechanics. The difference is not subtle. Not at all. I won’t dwell too much on this. Just re-read any account of the double-slit experiment with electrons which you may have read and you’ll remember how fundamental this is. [By the way, I was surprised to learn that the double-slit experiment with electrons has apparently only been done in 2012 in exactly the way as Feynman described it. So when Feynman described it in his 1965 Lectures, it was still very much a ‘thought experiment’ only – even a 1961 experiment (not mentioned by Feynman) had clearly established the reality of electron interference.]
OK. Let’s move on. So we have this complex wave function in quantum mechanics and, as Feynman writes, “It is not like a real wave in space; one cannot picture any kind of reality to this wave as one does for a sound wave.” That being said, one can, however, get pretty close to ‘imagining’ what it actually is IMHO. Let’s go by the example which Feynman gives himself – on the very same page where he writes the above actually. The amplitude for a free particle (i.e. with no forces acting on it) with momentum p = mv to go from location r1 to location r2 is equal to
Φ12 = (1/r12)eip.r12/ħ with r12 = r2 – r1
I agree this looks somewhat ugly again, but so what does it say? First, be aware of the difference between bold and normal type: I am writing p and v in bold type above because they are vectors: they have a magnitude (which I will denote by p and v respectively) as well as a direction in space. Likewise, r12 is a vector going from r1 to r2 (and r1 and r2 themselves are space vectors themselves obviously) and so r12 (non-bold) is the magnitude of that vector. Keeping that in mind, we know that the dot product p.r12 is equal to the product of the magnitudes of those vectors multiplied by cosα, with α the angle between those two vectors. Hence, p.r12 .= p.r12.cosα. Now, if p and r12 have the same direction, the angle α will be zero and so cosα will be equal to one and so we just have p.r12 = p.r12 or, if we’re considering a particle going from 0 to some position x, p.r12 = p.r12 = px.
Now we also have Planck’s constant there, in its reduced form ħ = h/2π. As you can imagine, this 2π has something to do with the fact that we need radians in the argument. It’s the same as what we did with x in the argument of that cosine function above: if we have to express stuff in radians, then we have to absorb a factor of 2π in that constant. However, here I need to make an additional digression. Planck’s constant is obviously not just any constant: it is the so-called quantum of action. Indeed, it appears in what may well the most fundamental relations in physics.
The first of these fundamental relations is the so-called Planck relation: E = hf. The Planck relation expresses the wave-particle duality of light (or electromagnetic waves in general): light comes in discrete quanta of energy (photons), and the energy of these ‘wave particles’ is directly proportional to the frequency of the wave, and the factor of proportionality is Planck’s constant.
The second fundamental relation, or relations – in plural – I should say, are the de Broglie relations. Indeed, Louis-Victor-Pierre-Raymond, 7th duc de Broglie, turned the above on its head: if the fundamental nature of light is (also) particle-like, then the fundamental nature of particles must (also) be wave-like. So he boldly associated a frequency f and a wavelength λ with all particles, such as electrons for example – but larger-scale objects, such as billiard balls, or planets, also have a de Broglie wavelength and frequency! The de Broglie relation determining the de Broglie frequency is – quite simply – the re-arranged Planck relation: f = E/h. So this relation relates the de Broglie frequency with energy. However, in the above wave function, we’ve got momentum, not energy. Well… Energy and momentum are obviously related, and so we have a second de Broglie relation relating momentum with wavelength: λ = h/p.
We’re almost there: just hang in there. 🙂 When we presented the sinusoidal wave equation, we introduced the angular frequency (ω) and the wave number (k), instead of working with f and λ. That’s because we want an argument expressed in radians. Here it’s the same. The two de Broglie equations have a equivalent using angular frequency and wave number: ω = E/ħ and k = p/ħ. So we’ll just use the second one (i.e. the relation with the momentum in it) to associate a wave number with the particle (k = p/ħ).
Phew! So, finally, we get that formula which we introduced a while ago already: Ψ(x) = (1/x)eikx, or, including time as a variable as well (we made abstraction of time so far):
Ψ(x, t) = (1/x)ei(kx – ωt)
The formula above obviously makes sense. For example, the 1/x factor makes the probability amplitude decrease as we get farther away from where the particle started: in fact, this 1/x or 1/r variation is what we see with electromagnetic waves as well: the amplitude of the electric field vector E varies as 1/r and, because we’re talking some real wave here and, hence, its energy is proportional to the square of the field, the energy that the source can deliver varies inversely as the square of the distance. [Another way of saying the same is that the energy we can take out of a wave within a given conical angle is the same, no matter how far away we are: the energy flux is never lost – it just spreads over a greater and greater effective area. But let’s go back to the main story.]
We’ve got the math – I hope. But what does this equation mean really? What’s that de Broglie wavelength or frequency in reality? What wave are we talking about? Well… What’s reality? As mentioned above, the famous de Broglie relations associate a wavelength λ and a frequency f to a particle with momentum p and energy E, but it’s important to mention that the associated de Broglie wave function yields probability amplitudes. So it is, indeed, not a ‘real wave in space’ as Feynman would put it. It is a quantum-mechanical wave equation.
Huh? […] It’s obviously about time I add some illustrations here, and so that’s what I’ll do. Look at the two cases below. The case on top is pretty close to the situation I described above: it’s a de Broglie wave – so that’s a complex wave – traveling through space (in one dimension only here). The real part of the complex amplitude is in blue, and the green is the imaginary part. So the probability of finding that particle at some position x is the modulus squared of this complex amplitude. Now, this particular wave function ignores the 1/x variation and, hence, the squared modulus of Aei(kx – ωt) is equal to a constant. To be precise, it’s equal to A2 (check it: the squared modulus of a complex number z equals the product of z and its complex conjugate, and so we get A2 as a result indeed). So what does this mean? It means that the probability of finding that particle (an electron, for example) is the same at all points! In other words, we don’t know where it is! In the illustration below (top part), that’s shown as the (yellow) color opacity: the probability is spread out, just like the wave itself, so there is no definite position of the particle indeed.

[Note that the formula in the illustration above (which I took from Wikipedia once again) uses p instead of k as the factor in front of x. While it does not make a big difference from a mathematical point of view (ħ is just a factor of proportionality: k = p/ħ), it does make a big difference from a conceptual point of view and, hence, I am puzzled as to why the author of this article did this. Also, there is some variation in the opacity of the yellow (i.e. the color of our tennis (or ping pong) ball representing our ‘wavicle’) which shouldn’t be there because the probability associated with this particular wave function is a constant indeed: so there is no variation in the probability (when squaring the absolute value of a complex number, the phase factor does not come into play). Also note that, because all probabilities have to add up to 100% (or to 1), a wave function like this is quite problematic. However, don’t worry about it just now: just try to go with the flow.]
By now, I must assume you shook your head in disbelief a couple of time already. Surely, this particle (let’s stick to the example of an electron) must be somewhere, yes? Of course.
The problem is that we gave an exact value to its momentum and its energy and, as a result, through the de Broglie relations, we also associated an exact frequency and wavelength to the de Broglie wave associated with this electron. Hence, Heisenberg’s Uncertainty Principle comes into play: if we have exact knowledge on momentum, then we cannot know anything about its location, and so that’s why we get this wave function covering the whole space, instead of just some region only. Sort of. Here we are, of course, talking about that deep mystery about which I cannot say much – if only because so many eminent physicists have already exhausted the topic. I’ll just state Feynman once more: “Things on a very small scale behave like nothing that you have any direct experience with. […] It is very difficult to get used to, and it appears peculiar and mysterious to everyone – both to the novice and to the experienced scientist. Even the experts do not understand it the way they would like to, and it is perfectly reasonable that they should not because all of direct, human experience and of human intuition applies to large objects. We know how large objects will act, but things on a small scale just do not act that way. So we have to learn about them in a sort of abstract or imaginative fashion and not by connection with our direct experience.” And, after describing the double-slit experiment, he highlights the key conclusion: “In quantum mechanics, it is impossible to predict exactly what will happen. We can only predict the odds [i.e. probabilities]. Physics has given up on the problem of trying to predict exactly what will happen. Yes! Physics has given up. We do not know how to predict what will happen in a given circumstance. It is impossible: the only thing that can be predicted is the probability of different events. It must be recognized that this is a retrenchment in our ideal of understanding nature. It may be a backward step, but no one has seen a way to avoid it.”
[…] That’s enough on this I guess, but let me – as a way to conclude this little digression – just quickly state the Uncertainty Principle in a more or less accurate version here, rather than all of the ‘descriptions’ which you may have seen of it: the Uncertainty Principle refers to any of a variety of mathematical inequalities asserting a fundamental limit (fundamental means it’s got nothing to do with observer or measurement effects, or with the limitations of our experimental technologies) to the precision with which certain pairs of physical properties of a particle (these pairs are known as complementary variables) such as, for example, position (x) and momentum (p), can be known simultaneously. More in particular, for position and momentum, we have that σxσp ≥ ħ/2 (and, in this formulation, σ is, obviously the standard symbol for the standard deviation of our point estimate for x and p respectively).
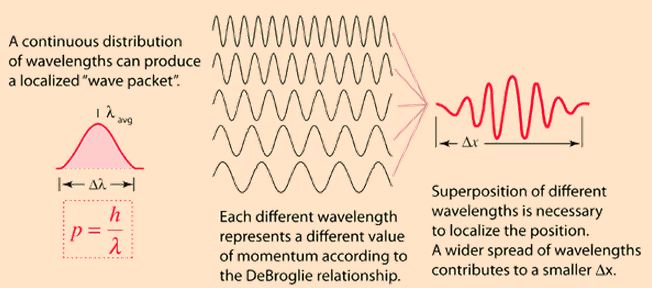
OK. Back to the illustration above. A particle that is to be found in some specific region – rather than just ‘somewhere’ in space – will have a probability amplitude resembling the wave equation in the bottom half: it’s a wave train, or a wave packet, and we can decompose it, using the Fourier analysis, in a number of sinusoidal waves, but so we do not have a unique wavelength for the wave train as a whole, and that means – as per the de Broglie equations – that there’s some uncertainty about its momentum (or its energy).
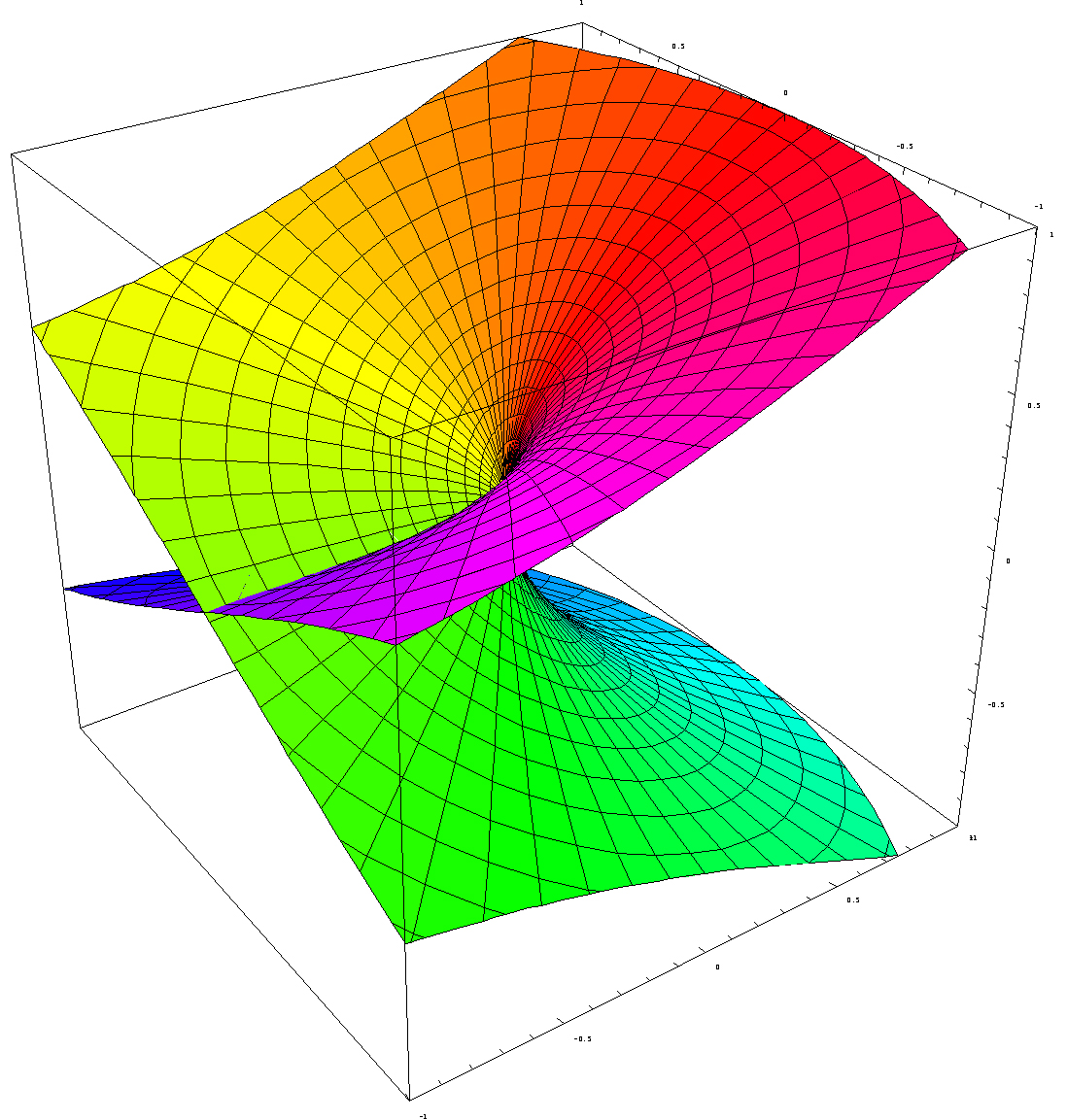
I will let this sink in for now. In my next post, I will write some more about these wave equations. They are usually a solution to some differential equation – and that’s where my next post will connect with my previous ones (on differential equations). Just to say goodbye – as for now that is – I will just copy another beautiful illustration from Wikipedia. See below: it represents the (likely) space in which a single electron on the 5d atomic orbital of a hydrogen atom would be found. The solid body shows the places where the electron’s probability density (so that’s the squared modulus of the probability amplitude) is above a certain value – so it’s basically the area where the likelihood of finding the electron is higher than elsewhere. The hue on the colored surface shows the complex phase of the wave function.

It is a wonderful image, isn’t it? At the very least, it increased my understanding of the mystery surround quantum mechanics somewhat. I hope it helps you too. 🙂
Post scriptum 1: On the need to normalize a wave function
In this post, I wrote something about the need for probabilities to add up to 1. In mathematical terms, this condition will resemble something like

In this integral, we’ve got – once again – the squared modulus of the wave function, and so that’s the probability of find the particle somewhere. The integral just states that all of the probabilities added all over space (Rn) should add up to some finite number (a2). Hey! But that’s not equal to 1 you’ll say. Well… That’s a minor problem only: we can create a normalized wave function ψ out of ψ0 by simply dividing ψ by a so we have ψ = ψ0/a, and then all is ‘normal’ indeed. 🙂
Post scriptum 2: On using colors to represent complex numbers
When inserting that beautiful 3D graph of that 5d atomic orbital (again acknowledging its source: Wikipedia), I wrote that “the hue on the colored surface shows the complex phase of the wave function.” Because this kind of visual representation of complex numbers will pop up in other posts as well (and you’ve surely encountered it a couple of times already), it’s probably useful to be explicit on what it represents exactly. Well… I’ll just copy the Wikipedia explanation, which is clear enough: “Given a complex number z = reiθ, the phase (also known as argument) θ can be represented by a hue, and the modulus r =|z| is represented by either intensity or variations in intensity. The arrangement of hues is arbitrary, but often it follows the color wheel. Sometimes the phase is represented by a specific gradient rather than hue.” So here you go…

Post scriptum 3: On the de Broglie relations
The de Broglie relations are a wonderful pair. They’re obviously equivalent: energy and momentum are related, and wavelength and frequency are obviously related too through the general formula relating frequency, wavelength and wave velocity: fλ = v (the product of the frequency and the wavelength must yield the wave velocity indeed). However, when it comes to the relation between energy and momentum, there is a little catch. What kind of energy are we talking about? We were describing a free particle (e.g. an electron) traveling through space, but with no (other) charges acting on it – in other words: no potential acting upon it), and so we might be tempted to conclude that we’re talking about the kinetic energy (K.E.) here. So, at relatively low speeds (v), we could be tempted to use the equations p = mv and K.E. = p2/2m = mv2/2 (the one electron in a hydrogen atom travels at less than 1% of the speed of light, and so that’s a non-relativistic speed indeed) and try to go from one equation to the other with these simple formulas. Well… Let’s try it.
f = E/h according to de Broglie and, hence, substituting E with p2/2m and f with v/λ, we get v/λ = m2v2/2mh. Some simplification and re-arrangement should then yield the second de Broglie relation: λ = 2h/mv = 2h/p. So there we are. Well… No. The second de Broglie relation is just λ = h/p: there is no factor 2 in it. So what’s wrong? The problem is the energy equation: de Broglie does not use the K.E. formula. [By the way, you should note that the K.E. = mv2/2 equation is only an approximation for low speeds – low compared to c that is.] He takes Einstein’s famous E = mc2 equation (which I am tempted to explain now but I won’t) and just substitutes c, the speed of light, with v, the velocity of the slow-moving particle. This is a very fine but also very deep point which, frankly, I do not yet fully understand. Indeed, Einstein’s E = mc2 is obviously something much ‘deeper’ than the formula for kinetic energy. The latter has to do with forces acting on masses and, hence, obeys Newton’s laws – so it’s rather familiar stuff. As for Einstein’s formula, well… That’s a result from relativity theory and, as such, something that is much more difficult to explain. While the difference between the two energy formulas is just a factor of 1/2 (which is usually not a big problem when you’re just fiddling with formulas like this), it makes a big conceptual difference.
Hmm… Perhaps we should do some examples. So these de Broglie equations associate a wave with frequency f and wavelength λ with particles with energy E, momentum p and mass m traveling through space with velocity v: E = hf and p = h/λ. [And, if we would want to use some sine or cosine function as an example of such wave function – which is likely – then we need an argument expressed in radians rather than in units of time or distance. In other words, we will need to convert frequency and wavelength to angular frequency and wave number respectively by using the 2π = ωT = ω/f and 2π = kλ relations, with the wavelength (λ), the period (T) and the velocity (v) of the wave being related through the simple equations f = 1/T and λ = vT. So then we can write the de Broglie relations as: E = ħω and p = ħk, with ħ = h/2π.]
In these equations, the Planck constant (be it h or ħ) appears as a simple factor of proportionality (we will worry about what h actually is in physics in later posts) – but a very tiny one: approximately 6.626×10–34 J·s (Joule is the standard SI unit to measure energy, or work: 1 J = 1 kg·m2/s2), or 4.136×10–15 eV·s when using a more appropriate (i.e. larger) measure of energy for atomic physics: still, 10–15 is only 0.000 000 000 000 001. So how does it work? First note, once again, that we are supposed to use the equivalent for slow-moving particles of Einstein’s famous E = mc2 equation as a measure of the energy of a particle: E = mv2. We know velocity adds mass to a particle – with mass being a measure for inertia. In fact, the mass of so-called massless particles, like photons, is nothing but their energy (divided by c2). In other words, they do not have a rest mass, but they do have a relativistic mass m = E/c2, with E = hf (and with f the frequency of the light wave here). Particles, such as electrons, or protons, do have a rest mass, but then they don’t travel at the speed of light. So how does that work out in that E = mv2 formula which – let me emphasize this point once again – is not the standard formula (for kinetic energy) that we’re used to (i.e. E = mv2/2)? Let’s do the exercise.
For photons, we can re-write E = hf as E = hc/λ. The numerator hc in this expression is 4.136×10–15 eV·s (i.e. the value of the Planck constant h expressed in eV·s) multiplied with 2.998×108 m/s (i.e. the speed of light c) so that’s (more or less) hc ≈ 1.24×10–6 eV·m. For visible light, the denominator will range from 0.38 to 0.75 micrometer (1 μm = 10–6 m), i.e. 380 to 750 nanometer (1 nm = 10–6 m), and, hence, the energy of the photon will be in the range of 3.263 eV to 1.653 eV. So that’s only a few electronvolt (an electronvolt (eV) is, by definition, the amount of energy gained (or lost) by a single electron as it moves across an electric potential difference of one volt). So that’s 2.6 to 5.2 Joule (1 eV = 1.6×10–19 Joule) and, hence, the equivalent relativistic mass of these photons is E/c2 or 2.9 to 5.8×10–34 kg. That’s tiny – but not insignificant. Indeed, let’s look at an electron now.
The rest mass of an electron is about 9.1×10−31 kg (so that’s a scale factor of a thousand as compared to the values we found for the relativistic mass of photons). Also, in a hydrogen atom, it is expected to speed around the nucleus with a velocity of about 2.2×106 m/s. That’s less than 1% of the speed of light but still quite fast obviously: at this speed (2,200 km per second), it could travel around the earth in less than 20 seconds (a photon does better: it travels not less than 7.5 times around the earth in one second). In any case, the electron’s energy – according to the formula to be used as input for calculating the de Broglie frequency – is 9.1×10−31 kg multiplied with the square of 2.2×106 m/s, and so that’s about 44×10–19 Joule or about 70 eV (1 eV = 1.6×10–19 Joule). So that’s – roughly – 35 times more than the energy associated with a photon.
The frequency we should associate with 70 eV can be calculated from E = hv/λ (we should, once again, use v instead of c), but we can also simplify and calculate directly from the mass: λ = hv/E = hv/mv2 = h/mv (however, make sure you express h in J·s in this case): we get a value for λ equal to 0.33 nanometer, so that’s more than one thousand times shorter than the above-mentioned wavelengths for visible light. So, once again, we have a scale factor of about a thousand here. That’s reasonable, no? [There is a similar scale factor when moving to the next level: the mass of protons and neutrons is about 2000 times the mass of an electron.] Indeed, note that we would get a value of 0.510 MeV if we would apply the E = mc2, equation to the above-mentioned (rest) mass of the electron (in kg): MeV stands for mega-electronvolt, so 0.510 MeV is 510,000 eV. So that’s a few hundred thousand times the energy of a photon and, hence, it is obvious that we are not using the energy equivalent of an electron’s rest mass when using de Broglie’s equations. No. It’s just that simple but rather mysterious E = mv2 formula. So it’s not mc2 nor mv2/2 (kinetic energy). Food for thought, isn’t it? Let’s look at the formulas once again.
They can easily be linked: we can re-write the frequency formula as λ = hv/E = hv/mv2 = h/mv and then, using the general definition of momentum (p = mv), we get the second de Broglie equation: p = h/λ. In fact, de Broglie‘s rather particular definition of the energy of a particle (E = mv2) makes v a simple factor of proportionality between the energy and the momentum of a particle: v = E/p or E = pv. [We can also get this result in another way: we have h = E/f = pλ and, hence, E/p = fλ = v.]
Again, this is serious food for thought: I have not seen any ‘easy’ explanation of this relation so far. To appreciate its peculiarity, just compare it to the usual relations relating energy and momentum: E =p2/2m or, in its relativistic form, p2c2 = E2 – m02c4 . So these two equations are both not to be used when going from one de Broglie relation to another. [Of course, it works for massless photons: using the relativistic form, we get p2c2 = E2 – 0 or E = pc, and the de Broglie relation becomes the Planck relation: E = hf (with f the frequency of the photon, i.e. the light beam it is part of). We also have p = h/λ = hf/c, and, hence, the E/p = c comes naturally. But that’s not the case for (slower-moving) particles with some rest mass: why should we use mv2 as a energy measure for them, rather than the kinetic energy formula?
But let’s just accept this weirdness and move on. After all, perhaps there is some mistake here and so, perhaps, we should just accept that factor 2 and replace λ = h/p by λ = 2h/p. Why not? 🙂 In any case, both the λ = h/mv and λ = 2h/p = 2h/mv expressions give the impression that both the mass of a particle as well as its velocity are on a par so to say when it comes to determining the numerical value of the de Broglie wavelength: if we double the speed, or the mass, the wavelength gets shortened by half. So, one would think that larger masses can only be associated with extremely short de Broglie wavelengths if they move at a fairly considerable speed. But that’s where the extremely small value of h changes the arithmetic we would expect to see. Indeed, things work different at the quantum scale, and it’s the tiny value of h that is at the core of this. Indeed, it’s often referred to as the ‘smallest constant’ in physics, and so here’s the place where we should probably say a bit more about what h really stands for.
Planck’s constant h describes the tiny discrete packets in which Nature packs energy: one cannot find any smaller ‘boxes’. As such, it’s referred to as the ‘quantum of action’. But, surely, you’ll immediately say that it’s cousin, ħ = h/2π, is actually smaller. Well… Yes. You’re actually right: ħ = h/2π is actually smaller. It’s the so-called quantum of angular momentum, also (and probably better) known as spin. Angular momentum is a measure of… Well… Let’s call it the ‘amount of rotation’ an object has, taking into account its mass, shape and speed. Just like p, it’s a vector. To be precise, it’s the product of a body’s so-called rotational inertia (so that’s similar to the mass m in p = mv) and its rotational velocity (so that’s like v, but it’s ‘angular’ velocity), so we can write L = Iω but we’ll not go in any more detail here. The point to note is that angular momentum, or spin as it’s known in quantum mechanics, also comes in discrete packets, and these packets are multiples of ħ. [OK. I am simplifying here but the idea or principle that I am explaining here is entirely correct.]
But let’s get back to the de Broglie wavelength now. As mentioned above, one would think that larger masses can only be associated with extremely short de Broglie wavelengths if they move at a fairly considerable speed. Well… It turns out that the extremely small value of h upsets our everyday arithmetic. Indeed, because of the extremely small value of h as compared to the objects we are used to ( in one grain of salt alone, we will find about 1.2×1018 atoms – just write a 1 with 18 zeroes behind and you’ll appreciate this immense numbers somewhat more), it turns out that speed does not matter all that much – at least not in the range we are used to. For example, the de Broglie wavelength associated with a baseball weighing 145 grams and traveling at 90 mph (i.e. approximately 40 m/s) would be 1.1×10–34 m. That’s immeasurably small indeed – literally immeasurably small: not only technically but also theoretically because, at this scale (i.e. the so-called Planck scale), the concepts of size and distance break down as a result of the Uncertainty Principle. But, surely, you’ll think we can improve on this if we’d just be looking at a baseball traveling much slower. Well… It does not much get better for a baseball traveling at a snail’s pace – let’s say 1 cm per hour, i.e. 2.7×10–6 m/s. Indeed, we get a wavelength of 17×10–28 m, which is still nowhere near the nanometer range we found for electrons. Just to give an idea: the resolving power of the best electron microscope is about 50 picometer (1 pm = ×10–12 m) and so that’s the size of a small atom (the size of an atom ranges between 30 and 300 pm). In short, for all practical purposes, the de Broglie wavelength of the objects we are used to does not matter – and then I mean it does not matter at all. And so that’s why quantum-mechanical phenomena are only relevant at the atomic scale.

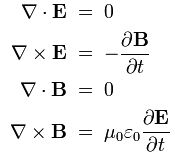
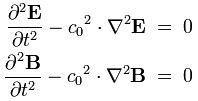
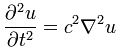
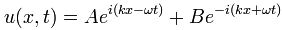
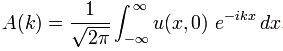
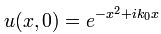
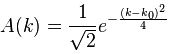
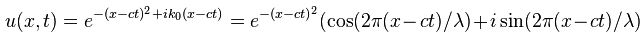
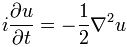

 Now if we plug that in the equation above, we get our time-dependent Schrödinger equation:
Now if we plug that in the equation above, we get our time-dependent Schrödinger equation: