Pre-scriptum (dated 26 June 2020): These posts on elementary math and physics have not suffered much the attack by the dark force—which is good because I still like them. While my views on the true nature of light, matter and the force or forces that act on them have evolved significantly as part of my explorations of a more realist (classical) explanation of quantum mechanics, I think most (if not all) of the analysis in this post remains valid and fun to read. In fact, I find the simplest stuff is often the best. 🙂
Original post:
My first working title for this post was Music and Modes. Yes. Modes. Not moods. The relation between music and moods is an interesting research topic as well but so it’s not what I am going to write about. 🙂
It started with me thinking I should write something on modes indeed, because the concept of a mode of a wave, or any oscillator really, is quite central to physics, both in classical physics as well as in quantum physics (quantum-mechanical systems are analyzed as oscillators too!). But I wondered how to approach it, as it’s a rather boring topic if you look at the math only. But then I was flying back from Europe, to Asia, where I live and, as I am also playing a bit of guitar, I suddenly wanted to know why we like music. And then I thought that’s a question you may have asked yourself at some point of time too! And so then I thought I should write about modes as part of a more interesting story: a story about music—or, to be precise, a story about the physics behind music. So… Let’s go for it.
Philosophy versus physics
There is, of course, a very simple answer to the question of why we like music: we like music because it is music. If it would not be music, we would not like it. That’s a rather philosophical answer, and it probably satisfies most people. However, for someone studying physics, that answer can surely not be sufficient. What’s the physics behind? I reviewed Feynman’s Lecture on sound waves in the plane, combined it with some other stuff I googled when I arrived, and then I wrote this post, which gives you a much less philosophical answer. 🙂
The observation at the center of the discussion is deceptively simple: why is it that similar strings (i.e. strings made of the same material, with the same thickness, etc), under the same tension but differing in length, sound ‘pleasant’ when sounded together if – and only if – the ratio of the length of the strings is like 1:2, 2:3, 3:4, 3:5, 4:5, etc (i.e. like whatever other ratio of two small integers)?
You probably wonder: is that the question, really? It is. The question is deceptively simple indeed because, as you will see in a moment, the answer is quite complicated. So complicated, in fact, that the Pythagoreans didn’t have any answer. Nor did anyone else for that matter—until the 18th century or so, when musicians, physicists and mathematicians alike started to realize that a string (of a guitar, or a piano, or whatever instrument Pythagoras was thinking of at the time), or a column of air (in a pipe organ or a trumpet, for example), or whatever other thing that actually creates the musical tone, actually oscillates at numerous frequencies simultaneously.
The Pythagoreans did not suspect that a string, in itself, is a rather complicated thing – something which physicists refer to as a harmonic oscillator – and that its sound, therefore, is actually produced by many frequencies, instead of only one. The concept of a pure note, i.e. a tone that is free of harmonics (i.e. free of all other frequencies, except for the fundamental frequency) also didn’t exist at the time. And if it did, they would not have been able to produce a pure tone anyway: producing pure tones – or notes, as I’ll call them, somewhat inaccurately (I should say: a pure pitch) – is remarkably complicated, and they do not exist in Nature. If the Pythagoreans would have been able to produce pure tones, they would have observed that pure tones do not give any sensation of consonance or dissonance if their relative frequencies respect those simple ratios. Indeed, repeated experiments, in which such pure tones are being produced, have shown that human beings can’t really say whether it’s a musical sound or not: it’s just sound, and it’s neither pleasant (or consonant, we should say) or unpleasant (i.e. dissonant).
The Pythagorean observation is valid, however, for actual (i.e. non-pure) musical tones. In short, we need to distinguish between tones and notes (i.e. pure tones): they are two very different things, and the gist of the whole argument is that musical tones coming out of one (or more) string(s) under tension are full of harmonics and, as I’ll explain in a minute, that’s what explains the observed relation between the lengths of those strings and the phenomenon of consonance (i.e. sounding ‘pleasant’) or dissonance (i.e. sounding ‘unpleasant’).
Of course, it’s easy to say what I say above: we’re 2015 now, and so we have the benefit of hindsight. Back then – so that’s more than 2,500 years ago! – the simple but remarkable fact that the lengths of similar strings should respect some simple ratio if they are to sound ‘nice’ together, triggered a fascination with number theory (in fact, the Pythagoreans actually established the foundations of what is now known as number theory). Indeed, Pythagoras felt that similar relationships should also hold for other natural phenomena! To mention just one example, the Pythagoreans also believed that the orbits of the planets would also respect such simple numerical relationships, which is why they talked of the ‘music of the spheres’ (Musica Universalis).
We now know that the Pythagoreans were wrong. The proportions in the movements of the planets around the Sun do not respect simple ratios and, with the benefit of hindsight once again, it is regrettable that it took many courageous and brilliant people, such as Galileo Galilei and Copernicus, to convince the Church of that fact. 😦 Also, while Pythagoras’ observations in regard to the sounds coming out of whatever strings he was looking at were correct, his conclusions were wrong: the observation does not imply that the frequencies of musical notes should all be in some simple ratio one to another.
Let me repeat what I wrote above: the frequencies of musical notes are not in some simple relationship one to another. The frequency scale for all musical tones is logarithmic and, while that implies that we can, effectively, do some tricks with ratios based on the properties of the logarithmic scale (as I’ll explain in a moment), the so-called ‘Pythagorean’ tuning system, which is based on simple ratios, was plain wrong, even if it – or some variant of it (instead of the 3:2 ratio, musicians used the 5:4 ratio from about 1510 onwards) – was generally used until the 18th century! In short, Pythagoras was wrong indeed—in this regard at least: we can’t do much with those simple ratios.
Having said that, Pythagoras’ basic intuition was right, and that intuition is still very much what drives physics today: it’s the idea that Nature can be described, or explained (whatever that means), by quantitative relationships only. Let’s have a look at how it actually works for music.
Tones, noise and notes
Let’s first define and distinguish tones and notes. A musical tone is the opposite of noise, and the difference between the two is that musical tones are periodic waveforms, so they have a period T, as illustrated below. In contrast, noise is a non-periodic waveform. It’s as simple as that.

Now, from previous posts, you know we can write any period function as the sum of a potentially infinite number of simple harmonic functions, and that this sum is referred to as the Fourier series. I am just noting it here, so don’t worry about it as for now. I’ll come back to it later.
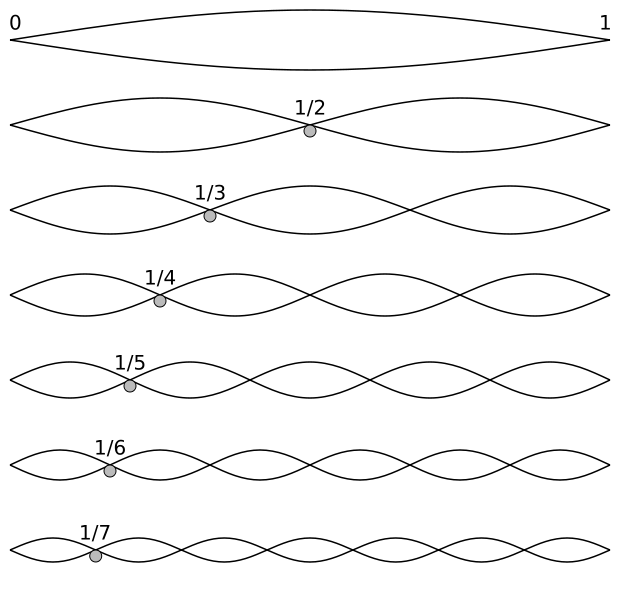
You also know we have seven musical notes: Do-Re-Mi-Fa-Sol-La-Si or, more common in the English-speaking world, A-B-C-D-E-F-G. And then it starts again with A (or Do). So we have two notes, separated by an interval which is referred to as an octave (from the Greek octo, i.e. eight), with six notes in-between, so that’s eight notes in total. However, you also know that there are notes in-between, except between E and F and between B and C. They are referred to as semitones or half-steps. I prefer the term ‘half-step’ over ‘semitone’, because we’re talking notes really, not tones.
We have, for example, F–sharp (denoted by F#), which we can also call G-flat (denoted by Gb). It’s the same thing: a sharp # raises a note by a semitone (aka half-step), and a flat b lowers it by the same amount, so F# is Gb. That’s what shown below: in an octave, we have eight notes but twelve half-steps.
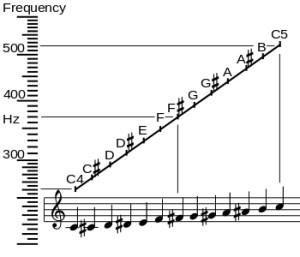
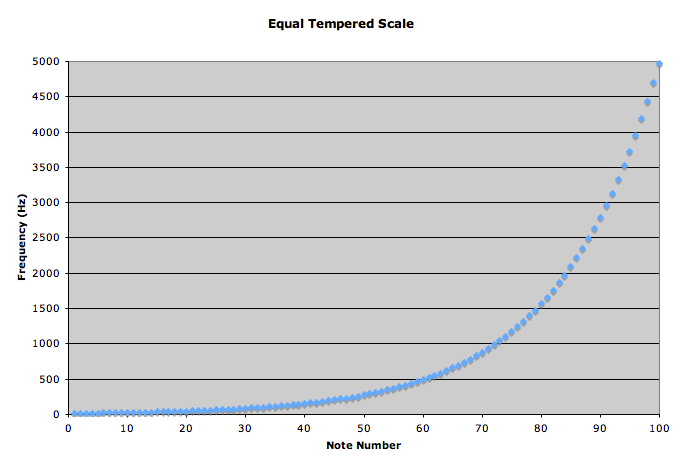
Let’s now look at the frequencies. The frequency scale above (expressed in oscillations per second, so that’s the hertz unit) is a logarithmic scale: frequencies double as we go from one octave to another: the frequency of the C4 note above (the so-called middle C) is 261.626 Hz, while the frequency of the next C note (C5) is double that: 523.251 Hz. [Just in case you’d want to know: the 4 and 5 number refer to its position on a standard 88-key piano keyboard: C4 is the fourth C key on the piano.]
Now, if we equate the interval between C4 and C5 with 1 (so the octave is our musical ‘unit’), then the interval between the twelve half-steps is, obviously, 1/12. Why? Because we have 12 halve-steps in our musical unit. You can also easily verify that, because of the way logarithms work, the ratio of the frequencies of two notes that are separated by one half-step (between D# and E, for example) will be equal to 21/12. Likewise, the ratio of the frequencies of two notes that are separated by n half-steps is equal to 2n/12. [In case you’d doubt, just do an example. For instance, if we’d denote the frequency of C4 as f0, and the frequency of C# as f1 and so on (so the frequency of D is f2, the frequency of C5 is f12, and everything else is in-between), then we can write the f2/f0 ratio as f2/f0 = ( f2/f1)(f1/f0) = 21/12·21/12 = 22/12 = 21/6. I must assume you’re smart enough to generalize this result yourself, and that f12/f0 is, obviously, equal to 212/12 =21 = 2, which is what it should be!]
Now, because the frequencies of the various C notes are expressed as a number involving some decimal fraction (like 523.251 Hz, and the 0.251 is actually an approximation only), and because they are, therefore, a bit hard to read and/or work with, I’ll illustrate the next idea – i.e. the concept of harmonics – with the A instead of the C. 🙂
Harmonics
The lowest A on a piano is denoted by A0, and its frequency is 27.5 Hz. Lower A notes exist (we have one at 13.75 Hz, for instance) but we don’t use them, because they are near (or actually beyond) the limit of the lowest frequencies we can hear. So let’s stick to our grand piano and start with that 27.5 Hz frequency. The next A note is A1, and its frequency is 55 Hz. We then have A2, which is like the A on my (or your) guitar: its frequency is equal to 2×55 = 110 Hz. The next is A3, for which we double the frequency once again: we’re at 220 Hz now. The next one is the A in the illustration of the C scale above: A4, with a frequency of 440 Hz.
[Let me, just for the record, note that the A4 note is the standard tuning pitch in Western music. Why? Well… There’s no good reason really, except convention. Indeed, we can derive the frequency of any other note from that A4 note using our formula for the ratio of frequencies but, because of the properties of a logarithmic function, we could do the same using whatever other note really. It’s an important point: there’s no such thing as an absolute reference point in music: once we define our musical ‘unit’ (so that’s the so-called octave in Western music), and how many steps we want to have in-between (so that’s 12 steps—again, in Western music, that is), we get all the rest. That’s just how logarithms work. So music is all about structure, i.e. mathematical relationships. Again, Pythagoras’ conclusions were wrong, but his intuition was right.]
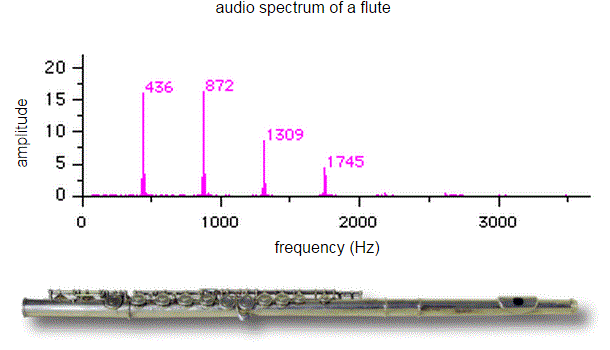
Now, the notes we are talking about here are all so-called pure tones. In fact, when I say that the A on our guitar is referred to as A2 and that it has a frequency of 110 Hz, then I am actually making a huge simplification. Worse, I am lying when I say that: when you play a string on a guitar, or when you strike a key on a piano, all kinds of other frequencies – so-called harmonics – will resonate as well, and that’s what gives the quality to the sound: it’s what makes it sound beautiful. So the fundamental frequency (aka as first harmonic) is 110 Hz alright but we’ll also have second, third, fourth, etc harmonics with frequency 220 Hz, 330 Hz, 440 Hz, etcetera. In music, the basic or fundamental frequency is referred to as the pitch of the tone and, as you can see, I often use the term ‘note’ (or pure tone) as a synonym for pitch—which is more or less OK, but not quite correct actually. [However, don’t worry about it: my sloppiness here does not affect the argument.]
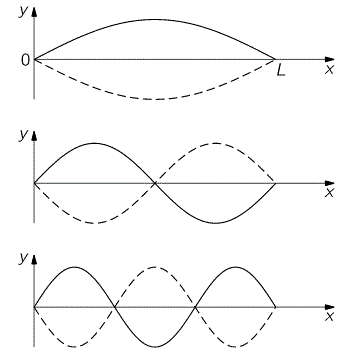
What’s the physics behind? Look at the illustration below (I borrowed it from the Physics Classroom site). The thick black line is the string, and the wavelength of its fundamental frequency (i.e. the first harmonic) is twice its length, so we write λ1 = 2·L or, the other way around, L = (1/2)·λ1. Now that’s the so-called first mode of the string. [One often sees the term fundamental or natural or normal mode, but the adjective is not necessary really. In fact, I find it confusing, although I sometimes find myself using it too.]
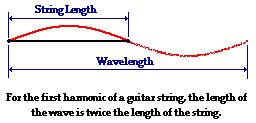
We also have a second, third, etc mode, depicted below, and these modes correspond to the second, third, etc harmonic respectively.
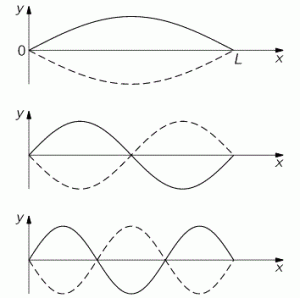
For the second, third, etc mode, the relationship between the wavelength and the length of the string is, obviously, the following: L = (2/2)·λ2 = λ2, L = L = (3/2)·λ3, etc. More in general, for the nth mode, L will be equal to L = (n/2)·λn, with n = 1, 2, etcetera. In fact, because L is supposed to be some fixed length, we should write it the other way around: λn = (2/n)·L.
What does it imply for the frequencies? We know that the speed of the wave – let’s denote it by c – as it travels up and down the string, is a property of the string, and it’s a property of the string only. In other words, it does not depend on the frequency. Now, the wave velocity is equal to the frequency times the wavelength, always, so we have c = f·λ. To take the example of the (classical) guitar string: its length is 650 mm, i.e. 0.65 m. Hence, the identities λ1 = (2/1)·L, λ2 = (2/2)·L, λ3 = (2/3)·L etc become λ1 = (2/1)·0.65 = 1.3 m, λ2 = (2/2)·0.65 = 0.65 m, λ3 = (2/3)·0.65 = 0.433.. m and so on. Now, combining these wavelengths with the above-mentioned frequencies, we get the wave velocity c = (110 Hz)·(1.3 m) = (220 Hz)·(0.65 m) = (330 Hz)·(0.433.. m) = 143 m/s.
Let me now get back to Pythagoras’ string. You should note that the frequencies of the harmonics produced by a simple guitar string are related to each other by simple whole number ratios. Indeed, the frequencies of the first and second harmonics are in a simple 2 to 1 ratio (2:1). The second and third harmonics have a 3:2 frequency ratio. The third and fourth harmonics a 4:3 ratio. The fifth and fourth harmonic 5:4, and so on and so on. They have to be. Why? Because the harmonics are simple multiples of the basic frequency. Now that is what’s really behind Pythagoras’ observation: when he was sounding similar strings with the same tension but different lengths, he was making sounds with the same harmonics. Nothing more, nothing less.
Let me be quite explicit here, because the point that I am trying to make here is somewhat subtle. Pythagoras’ string is Pythagoras’ string: he talked similar strings. So we’re not talking some actual guitar or a piano or whatever other string instrument. The strings on (modern) string instruments are not similar, and they do not have the same tension. For example, the six strings of a guitar strings do not differ in length (they’re all 650 mm) but they’re different in tension. The six strings on a classical guitar also have a different diameter, and the first three strings are plain strings, as opposed to the bottom strings, which are wound. So the strings are not similar but very different indeed. To illustrate the point, I copied the values below for just one of the many commercially available guitar string sets.  It’s the same for piano strings. While they are somewhat more simple (they’re all made of piano wire, which is very high quality steel wire basically), they also differ—not only in length but in diameter as well, typically ranging from 0.85 mm for the highest treble strings to 8.5 mm (so that’s ten times 0.85 mm) for the lowest bass notes.
It’s the same for piano strings. While they are somewhat more simple (they’re all made of piano wire, which is very high quality steel wire basically), they also differ—not only in length but in diameter as well, typically ranging from 0.85 mm for the highest treble strings to 8.5 mm (so that’s ten times 0.85 mm) for the lowest bass notes.
In short, Pythagoras was not playing the guitar or the piano (or whatever other more sophisticated string instrument that the Greeks surely must have had too) when he was thinking of these harmonic relationships. The physical explanation behind his famous observation is, therefore, quite simple: musical tones that have the same harmonics sound pleasant, or consonant, we should say—from the Latin con-sonare, which, literally, means ‘to sound together’ (from sonare = to sound and con = with). And otherwise… Well… Then they do not sound pleasant: they are dissonant.
To drive the point home, let me emphasize that, when we’re plucking a string, we produce a sound consisting of many frequencies, all in one go. One can see it in practice: if you strike a lower A string on a piano – let’s say the 110 Hz A2 string – then its second harmonic (220 Hz) will make the A3 string vibrate too, because it’s got the same frequency! And then its fourth harmonic will make the A4 string vibrate too, because they’re both at 440 Hz. Of course, the strength of these other vibrations (or their amplitude we should say) will depend on the strength of the other harmonics and we should, of course, expect that the fundamental frequency (i.e. the first harmonic) will absorb most of the energy. So we pluck one string, and so we’ve got one sound, one tone only, but numerous notes at the same time!
In this regard, you should also note that the third harmonic of our 110 Hz A2 string corresponds to the fundamental frequency of the E4 tone: both are 330 Hz! And, of course, the harmonics of E, such as its second harmonic (2·330 Hz = 660 Hz) correspond to higher harmonics of A too! To be specific, the second harmonic of our E string is equal to the sixth harmonic of our A2 string. If your guitar is any good, and if your strings are of reasonable quality too, you’ll actually see it: the (lower) E and A strings co-vibrate if you play the A major chord, but by striking the upper four strings only. So we’ve got energy – motion really – being transferred from the four strings you do strike to the two strings you do not strike! You’ll say: so what? Well… If you’ve got any better proof of the actuality (or reality) of various frequencies being present at the same time, please tell me! 🙂
So that’s why A and E sound very well together (A, E and C#, played together, make up the so-called A major chord): our ear likes matching harmonics. And so that why we like musical tones—or why we define those tones as being musical! 🙂 Let me summarize it once more: musical tones are composite sound waves, consisting of a fundamental frequency and so-called harmonics (so we’ve got many notes or pure tones altogether in one musical tone). Now, when other musical tones have harmonics that are shared, and we sound those notes too, we get the sensation of harmony, i.e. the combination sounds consonant.
Now, i’s not difficult to see that we will always have such shared harmonics if we have similar strings, with the same tension but different lengths, being sounded together. In short, what Pythagoras observed has nothing much to do with notes, but with tones. Let’s go a bit further in the analysis now by introducing some more math. And, yes, I am very sorry: it’s the dreaded Fourier analysis indeed! 🙂
Fourier analysis
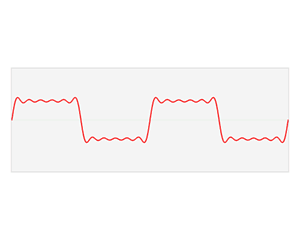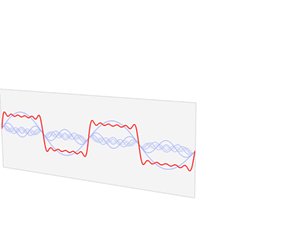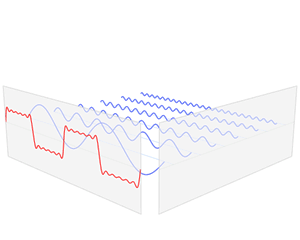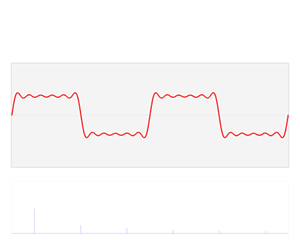
You know that we can decompose any periodic function into a sum of a (potentially infinite) series of simple sinusoidal functions, as illustrated below. I took the illustration from Wikipedia: the red function s6(x) is the sum of six sine functions of different amplitudes and (harmonically related) frequencies. The so-called Fourier transform S(f) (in blue) relates the six frequencies with the respective amplitudes.
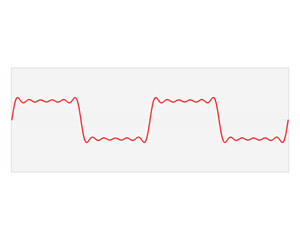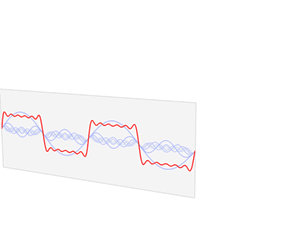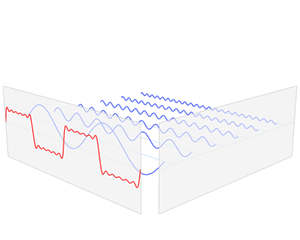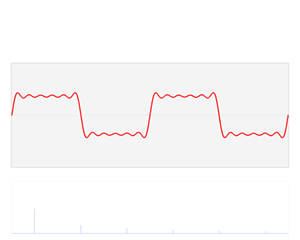
In light of the discussion above, it is easy to see what this means for the sound coming from a plucked string. Using the angular frequency notation (so we write everything using ω instead of f), we know that the normal or natural modes of oscillation have frequencies ω = 2π/T = 2πf (so that’s the fundamental frequency or first harmonic), 2ω (second harmonic), 3ω (third harmonic), and so on and so on.
Now, there’s no reason to assume that all of the sinusoidal functions that make up our tone should have the same phase: some phase shift Φ may be there and, hence, we should write our sinusoidal function not as cos(ωt), but as cos(ωt + Φ) in order to ensure our analysis is general enough. [Why not a sine function? It doesn’t matter: the cosine and sine function are the same, except for another phase shift of 90° = π/2.] Now, from our geometry classes, we know that we can re-write cos(ωt + Φ) as
cos(ωt + Φ) = [cos(Φ)cos(ωt) – sin(Φ)sin(ωt)]
We have a lot of these functions of course – one for each harmonic, in fact – and, hence, we should use subscripts, which is what we do in the formula below, which says that any function f(t) that is periodic with the period T can be written mathematically as:
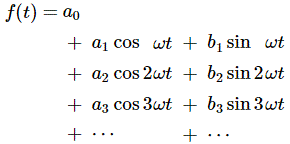
You may wonder: what’s that period T? It’s the period of the fundamental mode, i.e. the first harmonic. Indeed, the period of the second, third, etc harmonic will only be one half, one third etcetera of the period of the first harmonic. Indeed, T2 = (2π)/(2ω) = (1/2)·(2π)/ω = (1/2)·T1, and T3 = (2π)/(3ω) = (1/3)·(2π)/ω = (1/3)·T1, and so on. However, it’s easy to see that these functions also repeat themselves after two, three, etc periods respectively. So all is alright, and the general idea behind the Fourier analysis is further illustrated below. [Note that both the formula as well as the illustration below (which I took from Feynman’s Lectures) add a ‘zero-frequency term’ a0 to the series. That zero-frequency term will usually be zero for a musical tone, because the ‘zero’ level of our tone will be zero indeed. Also note that the an and bn coefficients are, of course, equal to an = cos Φn and bn = –sinΦn, so you can relate the illustration and the formula easily.]
 You’ll say: What the heck! Why do we need the mathematical gymnastics here? It’s just to understand that other characteristic of a musical tone: its quality (as opposed to its pitch). A so-called rich tone will have strong harmonics, while a pure tone will only have the first harmonic. All other characteristics – the difference between a tone produced by a violin as opposed to a piano – are then related to the ‘mix’ of all those harmonics.
You’ll say: What the heck! Why do we need the mathematical gymnastics here? It’s just to understand that other characteristic of a musical tone: its quality (as opposed to its pitch). A so-called rich tone will have strong harmonics, while a pure tone will only have the first harmonic. All other characteristics – the difference between a tone produced by a violin as opposed to a piano – are then related to the ‘mix’ of all those harmonics.
So we have it all now, except for loudness which is, of course, related to the magnitude of the air pressure changes as our waveform moves through the air: pitch, loudness and quality. that’s what makes a musical tone. 🙂
Dissonance
As mentioned above, if the sounds are not consonant, they’re dissonant. But what is dissonance really? What’s going on? The answer is the following: when two frequencies are near to a simple fraction, but not exact, we get so-called beats, which our ear does not like.
Huh? Relax. The illustration below, which I copied from the Wikipedia article on piano tuning, illustrates the phenomenon. The blue wave is the sum of the red and the green wave, which are originally identical. But then the frequency of the green wave is increased, and so the two waves are no longer in phase, and the interference results in a beating pattern. Of course, our musical tone involves different frequencies and, hence, different periods T1,T2, T3 etcetera, but you get the idea: the higher harmonics also oscillate with period T1, and if the frequencies are not in some exact ratio, then we’ll have a similar problem: beats, and our ear will not like the sound.
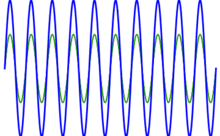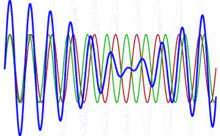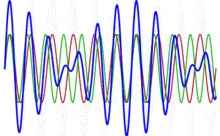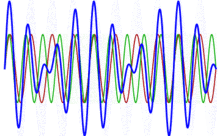
Of course, you’ll wonder: why don’t we like beats in tones? We can ask that, can’t we? It’s like asking why we like music, isn’t it? […] Well… It is and it isn’t. It’s like asking why our ear (or our brain) likes harmonics. We don’t know. That’s how we are wired. The ‘physical’ explanation of what is musical and what isn’t only goes so far, I guess. 😦
Pythagoras versus Bach
From all of what I wrote above, it is obvious that the frequencies of the harmonics of a musical tone are, indeed, related by simple ratios of small integers: the frequencies of the first and second harmonics are in a simple 2 to 1 ratio (2:1); the second and third harmonics have a 3:2 frequency ratio; the third and fourth harmonics a 4:3 ratio; the fifth and fourth harmonic 5:4, etcetera. That’s it. Nothing more, nothing less.
In other words, Pythagoras was observing musical tones: he could not observe the pure tones behind, i.e. the actual notes. However, aesthetics led Pythagoras, and all musicians after him – until the mid-18th century – to also think that the ratio of the frequencies of the notes within an octave should also be simple ratios. From what I explained above, it’s obvious that it should not work that way: the ratio of the frequencies of two notes separated by n half-steps is 2n/12, and, for most values of n, 2n/12 is not some simple ratio. [Why? Just take your pocket calculator and calculate the value of 21/12: it’s 20.08333… = 1.0594630943… and so on… It’s an irrational number: there are no repeating decimals. Now, 2n/12 is equal to 21/12·21/12·…·21/12 (n times). Why would you expect that product to be equal to some simple ratio?]
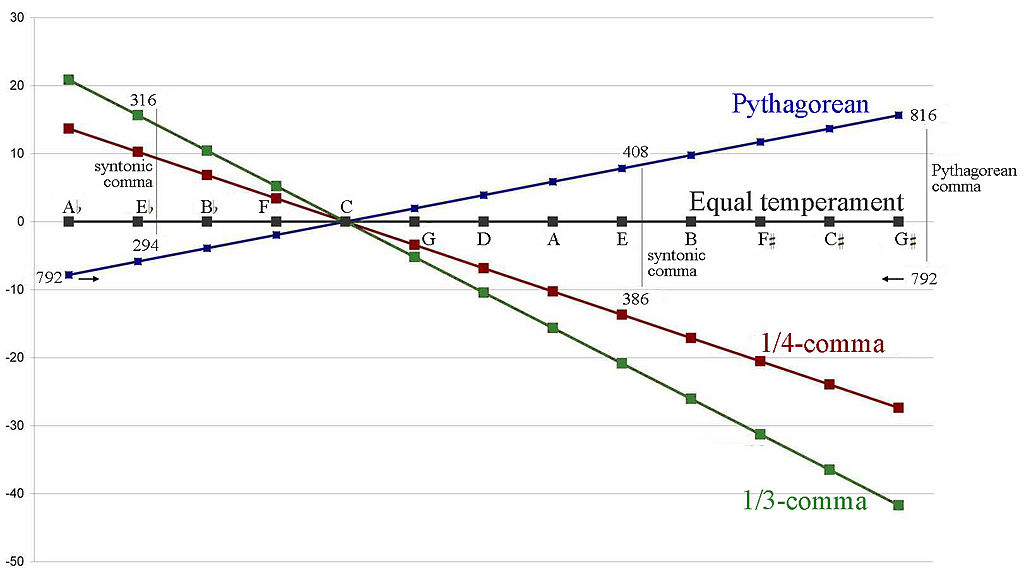
So – I said it already – Pythagoras was wrong—not only in this but also in other regards, such as when he espoused his views on the solar system, for example. Again, I am sorry to have to say that, but it is what is: the Pythagoreans did seem to prefer mathematical ideas over physical experiment. 🙂 Having said that, musicians obviously didn’t know about any alternative to Pythagoras, and they had surely never heard about logarithmic scales at the time. So… Well… They did use the so-called Pythagorean tuning system. To be precise, they tuned their instruments by equating the frequency ratio between the first and the fifth tone in the C scale (i.e. the C and G, as they did not include the C#, D# and F# semitones when counting) with the ratio 3/2, and then they used other so-called harmonic ratios for the notes in-between.
Now, the 3/2 ratio is actually almost correct, because the actual frequency ratio is 27/12 (we have seven tones, including the semitones—not five!), and so that’s 1.4983, approximately. Now, that’s pretty close to 3/2 = 1.5, I’d say. 🙂 Using that approximation (which, I admit, is fairly accurate indeed), the tuning of the other strings would then also be done assuming certain ratios should be respected, like the ones below.

So it was all quite good. Having said that, good musicians, and some great mathematicians, felt something was wrong—if only because there were several so-called just intonation systems around (for an overview, check out the Wikipedia article on just intonation). More importantly, they felt it was quite difficult to transpose music using the Pythagorean tuning system. Transposing music amounts to changing the so-called key of a musical piece: what one does, basically, is moving the whole piece up or down in pitch by some constant interval that is not equal to an octave. Today, transposing music is a piece of cake—Western music at least. But that’s only because all Western music is played on instruments that are tuned using that logarithmic scale (technically, it’s referred to as the 12-tone equal temperament (12-TET) system). When you’d use one of the Pythagorean systems for tuning, a transposed piece does not sound quite right.
The first mathematician who really seemed to know what was wrong (and, hence, who also knew what to do) was Simon Stevin, who wrote a manuscript based on the ’12th root of 2 principle’ around AD 1600. It shouldn’t surprise us: the thinking of this mathematician from Bruges would inspire John Napier’s work on logarithms. Unfortunately, while that manuscript describes the basic principles behind the 12-TET system, it didn’t get published (Stevin had to run away from Bruges, to Holland, because he was protestant and the Spanish rulers at the time didn’t like that). Hence, musicians, while not quite understanding the math (or the physics, I should say) behind their own music, kept trying other tuning systems, as they felt it made their music sound better indeed.
One of these ‘other systems’ is the so-called ‘good’ temperament, which you surely heard about, as it’s referred to in Bach’s famous composition, Das Wohltemperierte Klavier, which he finalized in the first half of the 18th century. What is that ‘good’ temperament really? Well… It is what it is: it’s one of those tuning systems which made musicians feel better about their music for a number of reasons, all of which are well described in the Wikipedia article on it. But the main reason is that the tuning system that Bach recommended was a great deal better when it came to playing the same piece in another key. However, it still wasn’t quite right, as it wasn’t the equal temperament system (i.e. the 12-TET system) that’s in place now (in the West at least—the Indian music scale, for instance, is still based on simple ratios).
Why do I mention this piece of Bach? The reason is simple: you probably heard of it because it’s one of the main reference points in a rather famous book: Gödel, Escher and Bach—an Eternal Golden Braid. If not, then just forget about it. I am mentioning it because one of my brothers loves it. It’s on artificial intelligence. I haven’t read it, but I must assume Bach’s master piece is analyzed there because of its structure, not because of the tuning system that one’s supposed to use when playing it. So… Well… I’d say: don’t make that composition any more mystic than it already is. 🙂 The ‘magic’ behind it is related to what I said about A4 being the ‘reference point’ in music: since we’re using a universal logarithmic scale now, there’s no such thing as an absolute reference point any more: once we define our musical ‘unit’ (so that’s the so-called octave in Western music), and also define how many steps we want to have in-between (so that’s 12—in Western music, that is), we get all the rest. That’s just how logarithms work.
So, in short, music is all about structure, i.e. it’s all about mathematical relations, and about mathematical relations only. Again, Pythagoras’ conclusions were wrong, but his intuition was right. And, of course, it’s his intuition that gave birth to science: the simple ‘models’ he made – of how notes are supposed to be related to each other, or about our solar system – were, obviously, just the start of it all. And what a great start it was! Looking back once again, it’s rather sad conservative forces (such as the Church) often got in the way of progress. In fact, I suddenly wonder: if scientists would not have been bothered by those conservative forces, could mankind have sent people around the time that Charles V was born, i.e. around A.D. 1500 already? 🙂
Post scriptum: My example of the the (lower) E and A guitar strings co-vibrating when playing the A major chord striking the upper four strings only, is somewhat tricky. The (lower) E and A strings are associated with lower pitches, and we said overtones (i.e. the second, third, fourth, etc harmonics) are multiples of the fundamental frequency. So why is that the lower strings co-vibrate? The answer is easy: they oscillate at the higher frequencies only. If you have a guitar: just try it. The two strings you do not pluck do vibrate—and very visibly so, but the low fundamental frequencies that come out of them when you’d strike them, are not audible. In short, they resonate at the higher frequencies only. 🙂
The example that Feynman gives is much more straightforward: his example mentions the lower C (or A, B, etc) notes on a piano causing vibrations in the higher C strings (or the higher A, B, etc string respectively). For example, striking the C2 key (and, hence, the C2 string inside the piano) will make the (higher) C3 string vibrate too. But few of us have a grand piano at home, I guess. That’s why I prefer my guitar example. 🙂
Some content on this page was disabled on June 16, 2020 as a result of a DMCA takedown notice from The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/


 The point at the center is really interesting: the straight horizontal and vertical red lines through it are limits really. Feynman’s illustration below shows the point represents an unstable equilibrium: the hollow tube prevents the charge from going sideways. So if it wouldn’t be there, the charge would go sideways, of course! So it’s some kind of saddle point. Onward!
The point at the center is really interesting: the straight horizontal and vertical red lines through it are limits really. Feynman’s illustration below shows the point represents an unstable equilibrium: the hollow tube prevents the charge from going sideways. So if it wouldn’t be there, the charge would go sideways, of course! So it’s some kind of saddle point. Onward!