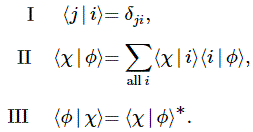Note (22 May 2020): I am in the process of reviewing many of my posts—including the one below—as a result of my realist interpretation of quantum mechanics, which is based on the ring current model of an electron. It is a delicate exercise because I would like to keep track of the old posts. Perhaps I should copy all of them to some new site. Any case, the point is: I would significantly rephrase some of the below because I now believe spin is very real in quantum mechanics as well.
Original post:
Don’t worry: I am not going to introduce the Hamiltonian matrix—not yet, that is. But this post is going a step further than my previous ones, in the sense that it will be more abstract. At the same time, I do want to stick to real physical examples so as to illustrate what we’re doing when working with those amplitudes. The example that I am going to use involves spin. So let’s talk about that first.
Spin, angular momentum and the magnetic moment
You know spin: it allows experienced pool players to do the most amazing tricks with billiard balls, making a joke of what a so-called elastic collision is actually supposed to look like. So it should not come as a surprise that spin complicates the analysis in quantum mechanics too. We dedicated several posts to that (see, for example, my post on spin and angular momentum in quantum physics) and I won’t repeat these here. Let me just repeat the basics:
1. Classical and quantum-mechanical spin do share similarities: the basic idea driving the quantum-mechanical spin model is that of a electric charge – positive or negative – spinning about its own axis (this is often referred to as intrinsic spin) as well as having some orbital motion (presumably around some other charge, like an electron in orbit with a nucleus at the center). This intrinsic spin, and the orbital motion, give our charge some angular momentum (J) and, because it’s an electric charge in motion, there is a magnetic moment (μ). To put things simply: the classical and quantum-mechanical view of things converge in their analysis of atoms or elementary particles as tiny little magnets. Hence, when placed in an external magnetic field, there is some interaction – a force – and their potential and/or kinetic energy changes. The whole system, in fact, acquires extra energy when placed in an external magnetic field.
Note: The formula for that magnetic energy is quite straightforward, both in classical as well as in quantum physics, so I’ll quickly jot it down: U = −μ•B = −|μ|·|B|·cosθ = −μ·B·cosθ. So it’s just the scalar product of the magnetic moment and the magnetic field vector, with a minus sign in front so as to get the direction right. [θ is the angle between the μ and B vectors and determines whether U as a whole is positive or negative.
2. The classical and quantum-mechanical view also diverge, however. They diverge, first, because of the quantum nature of spin in quantum mechanics. Indeed, while the angular momentum can take on any value in classical mechanics, that’s not the case in quantum mechanics: in whatever direction we measure, we get a discrete set of values only. For example, the angular momentum of a proton or an electron is either −ħ/2 or +ħ/2, in whatever direction we measure it. Therefore, they are referred to as spin-1/2 particles. All elementary fermions, i.e. the particles that constitute matter (as opposed to force-carrying particles, like photons), have spin 1/2.
Note: Spin-1/2 particles include, remarkably enough, neutrons too, which has the same kind of magnetic moment that a rotating negative charge would have. The neutron, in other words, is not exactly ‘neutral’ in the magnetic sense. One can explain this by noting that a neutron is not ‘elementary’, really: it consists of three quarks, just like a proton, and, therefore, it may help you to imagine that the electric charges inside are, somehow, distributed unevenly—although physicists hate such simplifications. I am noting this because the famous Stern-Gerlach experiment, which established the quantum nature of particle spin, used silver atoms, rather than protons or electrons. More in general, we’ll tend to forget about the electric charge of the particles we’re describing, assuming, most of the time, or tacitly, that they’re neutral—which helps us to sort of forget about classical theory when doing quantum-mechanical calculations!
3. The quantum nature of spin is related to another crucial difference between the classical and quantum-mechanical view of the angular momentum and the magnetic moment of a particle. Classically, the angular momentum and the magnetic moment can have any direction.
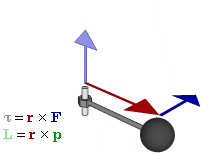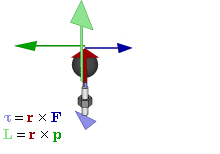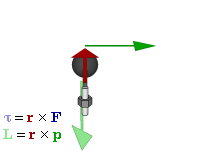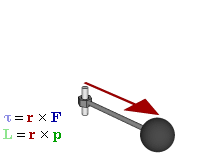
Note: I should probably briefly remind you that J is a so-called axial vector, i.e. a vector product (as opposed to a scalar product) of the radius vector r and the (linear) momentum vector p = m·v, with v the velocity vector, which points in the direction of motion. So we write: J = r×p = r×m·v = |r|·|p|·sinθ·n. The n vector is the unit vector perpendicular to the plane containing r and p (and, hence, v, of course) given by the right-hand rule. I am saying this to remind you that the direction of the magnetic moment and the direction of motion are not the same: the simple illustration below may help to see what I am talking about.]
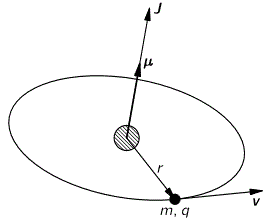
Back to quantum mechanics: the image above doesn’t work in quantum mechanics. We do not have an unambiguous direction of the angular momentum and, hence, of the magnetic moment. That’s where all of the weirdness of the quantum-mechanical concept of spin comes out, really. I’ll talk about that when discussing Feynman’s ‘filters’ – which I’ll do in a moment – but here I just want to remind you of the mathematical argument that I presented in the above-mentioned post. Just like in classical mechanics, we’ll have a maximum (and, hence, also a minimum) value for J, like +ħ, 0 and +ħ for a Lithium-6 nucleus. [I am just giving this rather special example of a spin-1 article so you’re reminded we can have particles with an integer spin number too!] So, when we measure its angular momentum in any direction really, it will take on one of these three values: +ħ, 0 or +ħ. So it’s either/or—nothing in-between. Now that leads to a funny mathematical situation: one would usually equate the maximum value of a quantity like this to the magnitude of the vector, which is equal to the (positive) square root of J2 = J•J = Jx2 + Jy2 + Jz2, with Jx, Jy and Jz the components of J in the x-, y- and z-direction respectively. But we don’t have continuity in quantum mechanics, and so the concept of a component of a vector needs to be carefully interpreted. There’s nothing definite there, like in classical mechanics: all we have is amplitudes, and all we can do is calculate probabilities, or expected values based on those amplitudes.
Huh? Yes. In fact, the concept of the magnitude of a vector itself becomes rather fuzzy: all we can do really is calculate its expected value. Think of it: in the classical world, we have a J2 = J•J product that’s independent of the direction of J. For example, if J is all in the x-direction, then Jy and Jz will be zero, and J2 = Jx2. If it’s all in the y-direction, then Jx and Jz will be zero and all of the magnitude of J will be in the y-direction only, so we write: J2 = Jy2. Likewise, if J does not have any z-component, then our J•J product will only include the x- and y-components: J•J = Jx2 + Jy2. You get the idea: the J2 = J•J product is independent of the direction of J exactly because, in classical mechanics, J actually has a precise and unambiguous magnitude and direction and, therefore, actually has a precise and unambiguous component in each direction. So we’d measure Jx, Jy, and Jz and, regardless of the actual direction of J, we’d find its magnitude |J| = J = +√J2 = +(Jx2 + Jy2 + Jz2)1/2.
In quantum mechanics, we just don’t have quantities like that. We say that Jx, Jy and Jz have an amplitude to take on a value that’s equal to +ħ, 0 or +ħ (or whatever other value is allowed by the spin number of the system). Now that we’re talking spin numbers, please note that this characteristic number is usually denoted by j, which is a bit confusing, but so be it. So j can be 0, 1/2, 1, 3/2, etcetera, and the number of ‘permitted values’ is 2j + 1 values, with each value being separated by an amount equal to ħ. So we have 1, 2, 3, 4, 5 etcetera possible values for Jx, Jy and Jz respectively. But let me get back to the lesson. We just can’t do the same thing in quantum mechanics. For starters, we can’t measure Jx, Jy, and Jz simultaneously: our Stern-Gerlach apparatus has a certain orientation and, hence, measures one component of J only. So what can we do?
Frankly, we can only do some math here. The wave-mechanical approach does allow to think of the expected value of J2 = J•J = Jx2 + Jy2 + Jz2 value, so we write:
E[J2] = E[J•J] = E[Jx2 + Jy2 + Jz2] = ?
[Feynman’s use of the 〈 and 〉 brackets to denote an expected value is hugely confusing, because these brackets are also used to denote an amplitude. So I’d rather use the more commonly used E[X] notation.] Now, it is a rather remarkable property, but the expected value of the sum of two or more random variables is equal to the sum of the expected values of the variables, even if those variables may not be independent. So we can confidently use the linearity property of the expected value operator and write:
E[Jx2 + Jy2 + Jz2] = E[Jx2] + E[Jx2] + E[Jx2]
Now we need something else. It’s also just part of the quantum-mechanical approach to things and so you’ll just have to accept it. It sounds rather obvious but it’s actually quite deep: if we measure the x-, y- or z-component of the angular momentum of a random particle, then each of the possible values is equally likely to occur. So that means, in our case, that the +ħ, 0 or +ħ values are equally likely, so their likelihood is one into three, i.e. 1/3. Again, that sounds obvious but it’s not. Indeed, please note, once again, that we can’t measure Jx, Jy, and Jz simultaneously, so the ‘or’ in x-, y- or z-component is an exclusive ‘or’. Of course, I must add this equipartition of likelihoods is valid only because we do not have a preferred direction for J: the particles in our beam have random ‘orientations’. Let me give you the lingo for this: we’re looking at an unpolarized beam. You’ll say: so what? Well… Again, think about what we’re doing here: we may of may not assume that the Jx, Jy, and Jz variables are related. In fact, in classical mechanics, they surely are: they’re determined by the magnitude and direction of J. Hence, they are not random at all ! But let me continue, so you see what comes out.
Because the +ħ, 0 and +ħ values are equally, we can write: E[Jx2] = ħ2/3 + 0/3 + (−ħ)2/3 = [ħ2 + 0 + (−ħ)2]/3 = 2ħ2/3. In case you wonder, that’s just the definition of the expected value operator: E[X] = p1x1 + p2x2 + … = ∑pixi, with pi the likelihood of the possible value xi . So we take a weighted average with the respective probabilities as the weights. However, in this case, with an unpolarized beam, the weighted average becomes a simple average.
Now, E[Jy2] and E[Jz2] are – rather unsurprisingly – also equal to 2ħ2/3, so we find that E[J2] = E[Jx2] + E[Jx2] + E[Jx2] = 3·(2ħ2/3) = 2ħ2 and, therefore, we’d say that the magnitude of the angular momentum is equal to |J| = J = +√2·ħ ≈ 1.414·ħ. Now that value is not equal to the maximum value of our x-, y-, z-component of J, or the component of J in whatever direction we’d want to measure it. That maximum value is ħ, without the √2 factor, so that’s some 40% less than the magnitude we’ve just calculated!
Now, you’ve probably fallen asleep by now but, what this actually says, is that the angular momentum, in quantum mechanics, is never completely in any direction. We can state this in another way: it implies that, in quantum mechanics, there’s no such thing really as a ‘definite’ direction of the angular momentum.
[…]
OK. Enough on this. Let’s move on to a more ‘real’ example. Before I continue though, let me generalize the results above:
[I] A particle, or a system, will have a characteristic spin number: j. That number is always an integer or a half-integer, and it determines a discrete set of possible values for the component of the angular momentum J in any direction.
[II] The number of values is equal to 2j + 1, and these values are separated by ħ, which is why they are usually measured in units of ħ, i.e. Planck’s reduced constant: ħ ≈ 1×10−34 J·s, so that’s tiny but real. 🙂 [It’s always good to remind oneself that we’re actually trying to describe reality.] For example, the permitted values for a spin-3/2 particle are +3ħ/2, +ħ/2, −ħ/2 and −3ħ/2 or, measured in units of ħ, +3/2, +1/2, −1/2 and −3/2. When discussing spin-1/2 particles, we’ll often refer to the two possible states as the ‘up’ and the ‘down’ state respectively. For example, we may write the amplitude for an electron or a proton to have a angular momentum in the x-direction equal to +ħ/2 or −ħ/2 as 〈+x〉 and 〈−x〉 respectively. [Don’t worry too much about it right now: you’ll get used to the notation quickly.]
[III] The classical concepts of angular momentum, and the related magnetic moment, have their limits in quantum mechanics. The magnitude of a vector quantity like angular momentum is generally not equal to the maximum value of the component of that quantity in any direction. The general rule is:
J2 = j·(j+1)ħ2 > j2·ħ2
So the maximum value of any component of J in whatever direction (i.e. j·ħ) is smaller than the magnitude of J (i.e. √[ j·(j+1)]·ħ). This implies we cannot associate any precise and unambiguous direction with quantities like the angular momentum J or the magnetic moment μ. As Feynman puts it:
“That the energy of an atom [or a particle] in a magnetic field can have only certain discrete energies is really not more surprising than the fact that atoms in general have only certain discrete energy levels—something we mentioned often in Volume I. Why should the same thing not hold for atoms in a magnetic field? It does. But it is the attempt to correlate this with the idea of an oriented magnetic moment that brings out some of the strange implications of quantum mechanics.”
A real example: the disintegration of a muon in a magnetic field
I talked about muon integration before, when writing a much more philosophical piece on symmetries in Nature and time reversal in particular. I used the illustration below. We’ve got an incoming muon that’s being brought to rest in a block of material, and then, as muons do, it disintegrates, emitting an electron and two neutrinos. As you can see, the decay direction is (mostly) in the direction of the axial vector that’s associated with the spin direction, i.e. the direction of the grey dashed line. However, there’s some angular distribution of the decay direction, as illustrated by the blue arrows, that are supposed to visualize the decay products, i.e. the electron and the neutrinos.
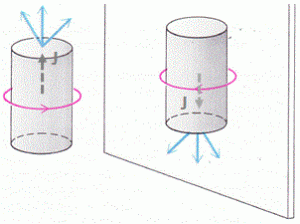
This disintegration process is very interesting from a more philosophical side. The axial vector isn’t ‘real’: it’s a mathematical concept—a pseudovector. A pseudo- or axial vector is the product of two so-called true vectors, aka as polar vectors. Just look back at what I wrote about the angular momentum: the J in the J = r×p = r×m·v formula is such vector, and its direction depends on the spin direction, which is clockwise or counter-clockwise, depending from what side you’re looking at it. Having said that, who’s to judge if the product of two ‘true’ vectors is any less ‘true’ than the vectors themselves? 🙂
The point is: the disintegration process does not respect what is referred to as P-symmetry. That’s because our mathematical conventions (like all of these right-hand rules that we’ve introduced) are unambiguous, and they tell us that the pseudovector in the mirror image of what’s going on, has the opposite direction. It has to, as per our definition of a vector product. Hence, our fictitious muon in the mirror should send its decay products in the opposite direction too! So… Well… The mirror image of our muon decay process is actually something that’s not going to happen: it’s physically impossible. So we’ve got a process in Nature here that doesn’t respect ‘mirror’ symmetry. Physicists prefer to call it ‘P-symmetry’, for parity symmetry, because it involves a flip of sign of all space coordinates, so there’s a parity inversion indeed. So there’s processes in Nature that don’t respect it but, while that’s all very interesting, it’s not what I want to write about. [Just check that post of mine if you’d want to read more.] Let me, therefore, use another illustration—one that’s more to the point in terms of what we do want to talk about here:

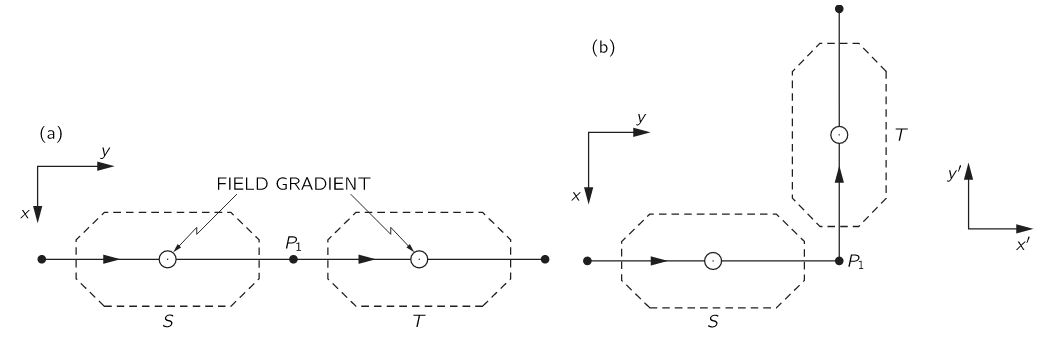
So we’ve got the same muon here – well… A different one, of course! 🙂 – entering that block (A) and coming to a grinding halt somewhere in the middle, and then it disintegrates in a few micro-seconds, which is an eternity at the atomic or sub-atomic scale. It disintegrates into an electron and two neutrinos, as mentioned above, with some spread in the decay direction. [In case you wonder where we can find muons… Well… I’ll let you look it up yourself.] So we have:

Now it turns out that the presence of a magnetic field (represented by the B arrows in the illustration above) can drastically change the angular distribution of decay directions. That shouldn’t surprise us, of course, but how does it work, exactly? Well… To simplify the analysis, we’ve got a polarized beam here: the spin direction of all muons before they enter the block and/or the magnetic field, i.e. at time t = 0, is in the +x-direction. So we filtered them just, before they entered the block. [I will come back to this ‘filtering’ process.] Now, if the muon’s spin would stay that way, then the decay products – and the electron in particular – would just go straight, because all of the angular momentum is in that direction. However, we’re in the quantum-mechanical world here, and so things don’t stay the same. In fact, as we explained, there’s no such things as a definite angular momentum: there’s just an amplitude to be in the +x state, and that amplitude changes in time and in space.
How exactly? Well… We don’t know, but we can apply some clever tricks here. The first thing to note is that our magnetic field will add to the energy of our muon. So, as I explained in my previous post, the magnetic field adds to the E in the exponent of our complex-valued wavefunction a·e−(i/ħ)(E·t − p∙x). In our example, we’ve got a magnetic field in the z-direction only, so that U = −μ•B reduces to U = −μz·B, and we can re-write our wavefunction as:
a·e−(i/ħ)[(E+U)·t − p∙x] = a·e−(i/ħ)(E·t − p∙x)·e(i/ħ)(μz·B·t)
Of course, the magnetic field only acts from t = 0 to when the muon disintegrates, which we’ll denote by the point t = τ. So what we get is that the probability amplitude of a particle that’s been in a uniform magnetic field changes by a factor e(i/ħ)(μz·B·τ). Note that it’s a factor indeed: we use it to multiply. You should also note that this is a complex exponential, so it’s a periodic function, with its real and imaginary part oscillating between zero and one. Finally, we know that μz can take on only certain values: for a spin-1/2 particle, they are plus or minus some number, which we’ll simply denote as μ, so that’s without the subscript, so our factor becomes:
e(i/ħ)(±μ·B·t)
[The plus or minus sign needs to be explained here, so let’s do that quickly: we have two possible states for a spin-1/2 particle, one ‘up’, and the other ‘down’. But then we also know that the phase of our complex-valued wave function turns clockwise, which is why we have a minus sign in the exponent of our e−iθ expression. In short, for the ‘up’ state, we should take the positive value, i.e. +μ, but the minus sign in the exponent of our e−iθ function makes it negative again, so our factor is e−(i/ħ)(μ·B·t) for the ‘up’ state, and e+(i/ħ)(μ·B·t) for the ‘down’ state.]
OK. We get that, but that doesn’t get us anywhere—yet. We need another trick first. One of the most fundamental rules in quantum-mechanics is that we can always calculate the amplitude to go from one state, say φ (read: ‘phi’), to another, say χ (read: ‘khi’), if we have a complete set of so-called base states, which we’ll denote by the index i or j (which you shouldn’t confuse with the imaginary unit, of course), using the following formula:
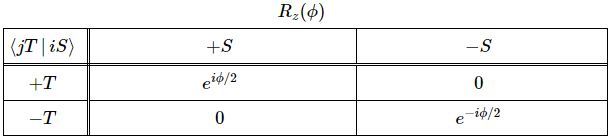
〈 χ | φ 〉 = ∑ 〈 χ | i 〉〈 i | φ 〉
I know this is a lot to swallow, so let me start with the notation. You should read 〈 χ | φ 〉 from right to left: it’s the amplitude to go from state φ to state χ. This notation is referred to as the bra-ket notation, or the Dirac notation. [Dirac notation sounds more scientific, doesn’t it?] The right part, i.e. | φ 〉, is the bra, and the left part, i.e. 〈 χ | is the ket. In our example, we wonder what the amplitude is for our muon staying in the +x state. Because that amplitude is time-dependent, we can write it as A+(τ) = 〈 +x at time t = τ | +x at time t = 0 〉 = 〈 +x at t = τ | +x at t = 0 〉or, using a very misleading shorthand, 〈 +x | +x 〉. [The shorthand is misleading because the +x in the ket obviously means something else than the +x in the bra.]
But let’s apply the rule. We’ve got two states with respect to each coordinate axis only here. For example, in respect to the z-axis, the spin values are +z and −z respectively. [As mentioned above, we actually mean that the angular momentum in this direction is either +ħ/2 or −ħ/2, aka as ‘up’ or ‘down’ respectively, but then quantum theorists seem to like all kinds of symbols better, so we’ll use the +z and −z notations for these two base states here. So now we can use our rule and write:
A+(t) = 〈 +x | +x 〉 = 〈 +x | +z 〉〈 +z | +x 〉 + 〈 +x | −z 〉〈 −z | +x 〉
You’ll say this doesn’t help us any further, but it does, because there is another set of rules, which are referred to as transformation rules, which gives us those 〈 +z | +x 〉 and 〈 −z | +x 〉 amplitudes. They’re real numbers, and it’s the same number for both amplitudes.
〈 +z | +x 〉 = 〈 −z | +x 〉 = 1/√2
This shouldn’t surprise you too much: the square root disappears when squaring, so we get two equal probabilities – 1/2, to be precise – that add up to one which – you guess it – they have to add up to because of the normalization rule: the sum of all probabilities has to add up to one, always. [I can feel your impatience, but just hang in here for a while, as I guide you through what is likely to be your very first quantum-mechanical calculation.] Now, the 〈 +z | +x 〉 = 〈 −z | +x 〉 = 1/√2 amplitudes are the amplitudes at time t = 0, so let’s be somewhat less sloppy with our notation and write 〈 +z | +x 〉 as C+(0) and 〈 −z | +x 〉 as C−(0), so we write:
〈 +z | +x 〉 = C+(0) = 1/√2
〈 −z | +x 〉 = C−(0) = 1/√2
Now we know what happens with those amplitudes over time: that e(i/ħ)(±μ·B·t) factor kicks in, and so we have:
C+(t) = C+(0)·e−(i/ħ)(μ·B·t) = e−(i/ħ)(μ·B·t)/√2
C−(t) = C−(0)·e+(i/ħ)(μ·B·t) = e+(i/ħ)(μ·B·t)/√2
As for the plus and minus signs, see my remark on the tricky ± business in regard to μ. To make a long story somewhat shorter :-), our expression for A+(t) = 〈 +x at t | +x 〉 now becomes:
A+(t) = 〈 +x | +z 〉·C+(t) + 〈 +x | −z 〉·C−(t)
Now, you wouldn’t be too surprised if I’d just tell you that the 〈 +x | +z 〉 and 〈 +x | −z 〉 amplitudes are also real-valued and equal to 1/√2, but you can actually use yet another rule we’ll generalize shortly: the amplitude to go from state φ to state χ is the complex conjugate of the amplitude to to go from state χ to state φ, so we write 〈 χ | φ 〉 = 〈 φ | χ 〉*, and therefore:
〈 +x | +z 〉 = 〈 +z | +x 〉* = (1/√2)* = (1/√2)
〈 +x | −z 〉 = 〈 −z | +x 〉* = (1/√2)* = (1/√2)
So our expression for A+(t) = 〈 +x at t | +x 〉 now becomes:
A+(t) = e−(i/ħ)(μ·B·t)/2 + e(i/ħ)(μ·B·t)/2
That’s the sum of a complex-valued function and its complex conjugate, and we’ve shown more than once (see my page on the essentials, for example) that such sum reduces to the sum of the real parts of the complex exponentials. [You should not expect any explanation of Euler’s eiθ = cosθ + i·sinθ rule at this level of understanding.] In short, we get the following grand result:
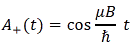
The big question, of course: what does this actually mean? 🙂 Well… Just square this thing and you get the probabilities shown below. [Note that the period of a squared cosine function is π, instead of 2π, which you can easily verify using an online graphing tool.]
Because you’re tired of this business, you probably don’t realize what we’ve just done. It’s spectacular and mundane at the same time. Let me quote Feynman to summarize the results:
“We find that the chance of catching the decay electron in the electron counter varies periodically with the length of time the muon has been sitting in the magnetic field. The frequency depends on the magnetic moment μ. The magnetic moment of the muon has, in fact, been measured in just this way.”
As far as I am concerned, the key result is that we’ve learned how to work with those mysterious amplitudes, and the wavefunction, in a practical way, thereby using all of the theoretical rules of the quantum-mechanical approach to real-life physical situations. I think that’s a great leap forward, and we’ll re-visit those rules in a more theoretical and philosophical démarche in the next post. As for the example itself, Feynman takes it much further, but I’ll just copy the Grand Master here:
Huh? Well… I am afraid I have to leave it at this, as I discussed the precession of ‘atomic’ magnets elsewhere (see my post on precession and diamagnetism), which gives you the same formula: ωp = μ·B/J (just substitute J for ±ħ/2). However, the derivation above approaches it from an entirely different angle, which is interesting. Of course, all fits. 🙂 However, I’ll let you do your own homework now. I hope to see you tomorrow for the mentioned theoretical discussion. Have a nice evening, or weekend – or whatever ! 🙂
Some content on this page was disabled on June 16, 2020 as a result of a DMCA takedown notice from The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 16, 2020 as a result of a DMCA takedown notice from The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 16, 2020 as a result of a DMCA takedown notice from The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 16, 2020 as a result of a DMCA takedown notice from The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/

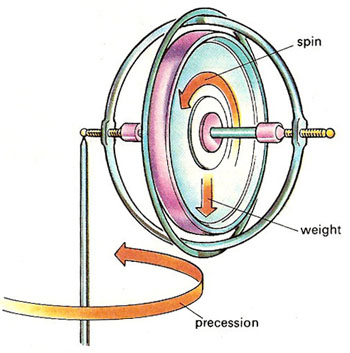
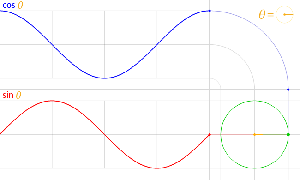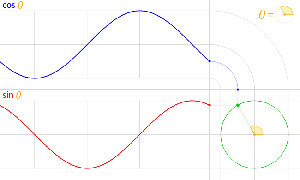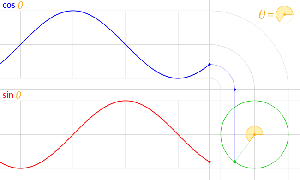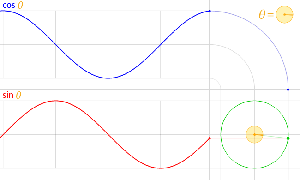
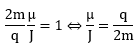 Let us now look at the other frequency fs. It is the Larmor or precession frequency. It is (also) a classical thing: if we think of the electron as a tiny magnet with a magnetic moment that is proportional to its angular momentum, then it should, effectively, precess in a magnetic field. The analysis of precession is quite straightforward. The geometry of the situation is shown below and we may refer to (almost) any standard physics textbook for the derivation.[6]
Let us now look at the other frequency fs. It is the Larmor or precession frequency. It is (also) a classical thing: if we think of the electron as a tiny magnet with a magnetic moment that is proportional to its angular momentum, then it should, effectively, precess in a magnetic field. The analysis of precession is quite straightforward. The geometry of the situation is shown below and we may refer to (almost) any standard physics textbook for the derivation.[6]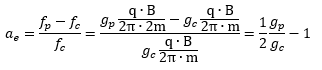 Hence, the so-called anomalous magnetic moment of an electron is nothing but the ratio of two mathematical factors – definitions, basically – which we can express in terms of actual frequencies:
Hence, the so-called anomalous magnetic moment of an electron is nothing but the ratio of two mathematical factors – definitions, basically – which we can express in terms of actual frequencies: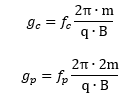 Our formula for ae now becomes:
Our formula for ae now becomes: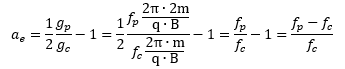 Of course, if we use the μ/J = 2m/q equality, then the fp/fc ratio will be equal to 1/2, and ae will not be zero but −1/2:
Of course, if we use the μ/J = 2m/q equality, then the fp/fc ratio will be equal to 1/2, and ae will not be zero but −1/2: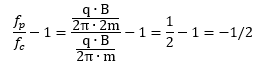 However, as mentioned above, we should not do that. The precession causes the magnetic moment and the angular momentum to wobble. Hence, there is nothing anomalous about the anomalous magnetic moment. We should not wonder why its value is not zero. We should wonder why it is so nearly zero.
However, as mentioned above, we should not do that. The precession causes the magnetic moment and the angular momentum to wobble. Hence, there is nothing anomalous about the anomalous magnetic moment. We should not wonder why its value is not zero. We should wonder why it is so nearly zero.

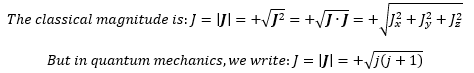 The J·J in the classical formula above is, of course, the equally classical vector dot product, and the formula itself is nothing but Pythagoras’ Theorem in three dimensions. Easy. I just put a + sign in front of the square roots so as to remind you we actually always have two square roots and that we should take the positive one. 🙂
The J·J in the classical formula above is, of course, the equally classical vector dot product, and the formula itself is nothing but Pythagoras’ Theorem in three dimensions. Easy. I just put a + sign in front of the square roots so as to remind you we actually always have two square roots and that we should take the positive one. 🙂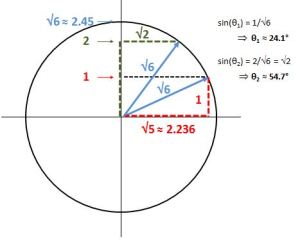 But… Well… Note those weird angles: we get something close to 24.1° and then another value close to 54.7°. No symmetry here. 😦 The table below gives some more values for larger j. They’re easy to calculate – it’s, once again, just Pythagoras’ Theorem – but… Well… No symmetries here. Just weird values. [I am not saying the formula for these angles is not straightforward. That formula is easy enough: θ = sin-1(m/√[j(j+1)]). It’s just… Well… No symmetry. You’ll see why that matters in a moment.]
But… Well… Note those weird angles: we get something close to 24.1° and then another value close to 54.7°. No symmetry here. 😦 The table below gives some more values for larger j. They’re easy to calculate – it’s, once again, just Pythagoras’ Theorem – but… Well… No symmetries here. Just weird values. [I am not saying the formula for these angles is not straightforward. That formula is easy enough: θ = sin-1(m/√[j(j+1)]). It’s just… Well… No symmetry. You’ll see why that matters in a moment.]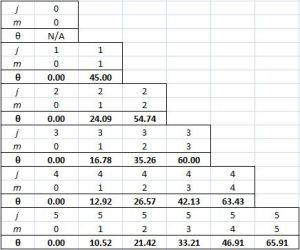 I skipped the half-integer values for j in the table above so you might think they might make it easier to come up with some kind of sensible explanation for the angles. Well… No. They don’t. For example, for j = 1/2 and m = ± 1/2, the angles are ±35.2644° – more or less, that is. 🙂 As you can see, these angles do not nicely cut up our circle in equal pieces, which triggers the obvious question: are these angles really equally likely? Equal angles do not correspond to equal distances on the z-axis (in case you don’t appreciate the point, look at the illustration below).
I skipped the half-integer values for j in the table above so you might think they might make it easier to come up with some kind of sensible explanation for the angles. Well… No. They don’t. For example, for j = 1/2 and m = ± 1/2, the angles are ±35.2644° – more or less, that is. 🙂 As you can see, these angles do not nicely cut up our circle in equal pieces, which triggers the obvious question: are these angles really equally likely? Equal angles do not correspond to equal distances on the z-axis (in case you don’t appreciate the point, look at the illustration below). 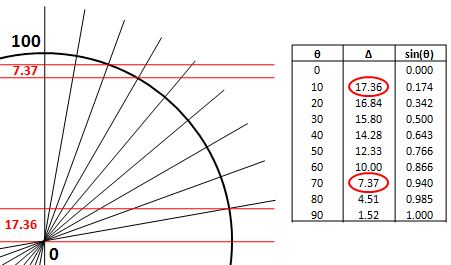
 That’s why
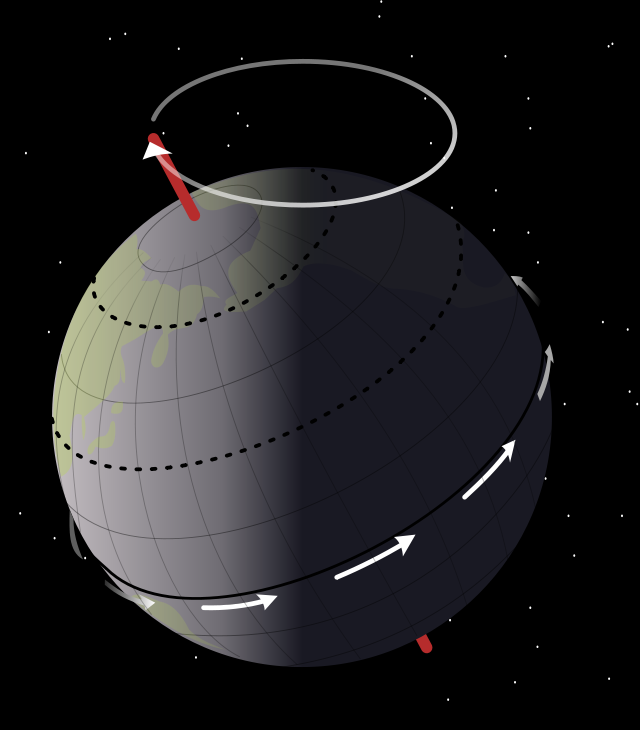
That’s why 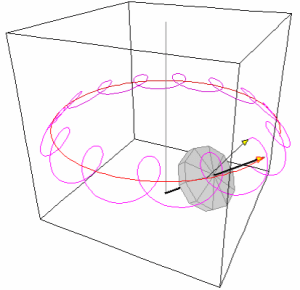 The nutation is caused by the gravitational force field, and the nutation movement usually dies out quickly because of dampening forces (read: friction). Now, we don’t think of gravitational fields when analyzing angular momentum in quantum mechanics, and we shouldn’t. But there is something else we may want to think of. There is also a phenomenon which is referred to as free nutation, i.e. a nutation that is not caused by an external force field. The Earth, for example, nutates slowly because of a gravitational pull from the Sun and the other planets – so that’s not a free nutation – but, in addition to this, there’s an even smaller wobble – which is an example of free nutation – because the Earth is not exactly spherical. In fact, the Great Mathematician, Leonhard Euler, had already predicted this, back in 1765, but it took another 125 years or so before an astronomist, Seth Chandler, could finally experimentally confirm and measure it. So they named this wobble
The nutation is caused by the gravitational force field, and the nutation movement usually dies out quickly because of dampening forces (read: friction). Now, we don’t think of gravitational fields when analyzing angular momentum in quantum mechanics, and we shouldn’t. But there is something else we may want to think of. There is also a phenomenon which is referred to as free nutation, i.e. a nutation that is not caused by an external force field. The Earth, for example, nutates slowly because of a gravitational pull from the Sun and the other planets – so that’s not a free nutation – but, in addition to this, there’s an even smaller wobble – which is an example of free nutation – because the Earth is not exactly spherical. In fact, the Great Mathematician, Leonhard Euler, had already predicted this, back in 1765, but it took another 125 years or so before an astronomist, Seth Chandler, could finally experimentally confirm and measure it. So they named this wobble 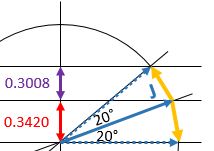 I am not sure if this approach would solve the problem of our angles and distances – the issue of whether we should think in equally likely angles or equally likely distances along the z-axis, really – but… Well… I’ll let you play with this. Please do send me some feedback if you think you’ve found something. 🙂
I am not sure if this approach would solve the problem of our angles and distances – the issue of whether we should think in equally likely angles or equally likely distances along the z-axis, really – but… Well… I’ll let you play with this. Please do send me some feedback if you think you’ve found something. 🙂