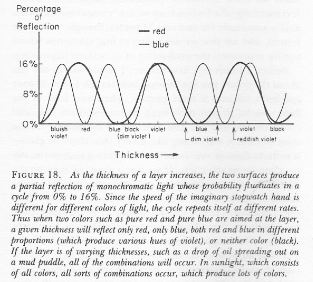
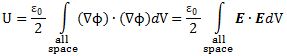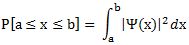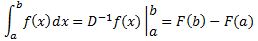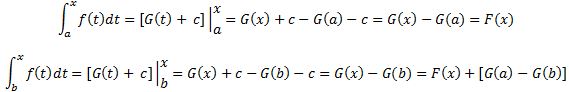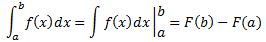Pre-script (dated 26 June 2020): This post has become less relevant (even irrelevant, perhaps) because my views on all things quantum-mechanical have evolved significantly as a result of my progression towards a more complete realist (classical) interpretation of quantum physics. In addition, some of the material was removed by a dark force (that also created problems with the layout, I see now). In any case, we recommend you read our recent papers. I keep blog posts like these mainly because I want to keep track of where I came from. I might review them one day, but I currently don’t have the time or energy for it. 🙂
Original post:
The relationship between math and physics is deep. When studying physics, one sometimes feels physics and math become one and the same. But they are not. In fact, eminent physicists such as Richard Feynman warn against emphasizing the math side of physics too much: “It is not because you understand the Maxwell equations mathematically inside out, that you understand physics inside out.”
We should never lose sight of the fact that all these equations and mathematical constructs represent physical realities. So the math is nothing but the ‘language’ in which we express physical reality and, as Feynman puts it, one (also) needs to develop a ‘physical’ – as opposed to a ‘mathematical’ – understanding of the equations. Now you’ll ask: what’s a ‘physical’ understanding? Well… Let me quote Feynman once again on that: “A physical understanding is a completely unmathematical, imprecise, and inexact thing, but absolutely necessary for a physicist.”
It’s rather surprising to hear that from him: this is a rather philosophical statement, indeed, and Feynman doesn’t like philosophy (see, for example, what he writes on the philosophical implications of the Uncertainty Principle). Indeed, while most physicists – or scientists in general, I’d say – will admit there is some value in a philosophy of science (that’s the branch of philosophy concerned with the foundations and methods of science), they will usually smile derisively when hearing someone talk about metaphysics. However, if metaphysics is the branch of philosophy that deals with ‘first principles’, then it’s obvious that the Standard Model (SM) in physics is, in fact, also some kind of ‘metaphysical’ model! Indeed, what everything is said and done, physicists assume those complex-valued wave functions are, somehow, ‘real’, but all they can ‘see’ (i.e. measure or verify by experiment) are (real-valued) probabilities: we can’t ‘see’ the probability amplitudes.
The only reason why we accept the SM theory is because its predictions agree so well with experiment. Very well indeed. The agreement between theory and experiment is most perfect in the so-called electromagnetic sector of the SM, but the results for the weak force (which I referred to as the ‘weird force’ in some of my posts) are very good too. For example, using CERN data, researchers could finally, recently, observe an extremely rare decay mode which, once again, confirms that the Standard Model, as complicated as it is, is the best we’ve got: just click on the link if you want to hear more about it. [And please do: stuff like this is quite readable and, hence, interesting.]
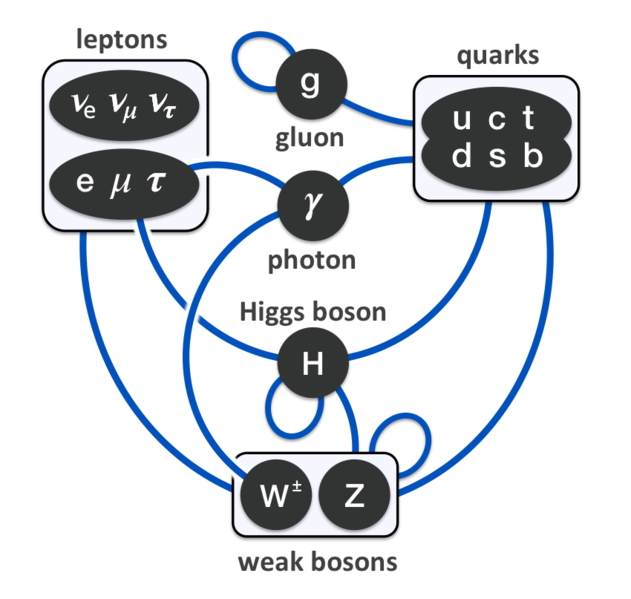
As this blog makes abundantly clear, it’s not easy to ‘summarize’ the Standard Model in a couple of sentences or in one simple diagram. In fact, I’d say that’s impossible. If there’s one or two diagrams sort of ‘covering’ it all, then it’s the two diagrams that you’ve seen ad nauseam already: (a) the overview of the three generations of matter, with the gauge bosons for the electromagnetic, strong and weak force respectively, as well as the Higgs boson, next to it, and (b) the overview of the various interactions between them. [And, yes, these two diagrams come from Wikipedia.]

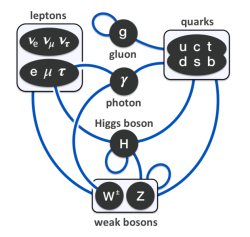
I’ve said it before: the complexity of the Standard Model (it has not less than 61 ‘elementary’ particles taking into account that quarks and gluons come in various ‘colors’, and also including all antiparticles – which we have to include them in out count because they are just as ‘real’ as the particles), and the ‘weirdness’ of the weak force, plus a astonishing range of other ‘particularities’ (these ‘quantum numbers’ or ‘charges’ are really not easy to ‘understand’), do not make for a aesthetically pleasing theory but, let me repeat it again, it’s the best we’ve got. Hence, we may not ‘like’ it but, as Feynman puts it: “Whether we like or don’t like a theory is not the essential question. It is whether or not the theory gives predictions that agree with experiment.” (Feynman, QED – The Strange Theory of Light and Matter, p. 10)
It would be foolish to try to reduce the complexity of the Standard Model to a couple of sentences. That being said, when digging into the subject-matter of quantum mechanics over the past year, I actually got the feeling that, when everything is said and done, modern physics has quite a lot in common with Pythagoras’ ‘simple’ belief that mathematical concepts – and numbers in particular – might have greater ‘actuality’ than the reality they are supposed to describe. To put it crudely, the only ‘update’ to the Pythagorean model that’s needed is to replace Pythagoras’ numerological ideas by the equipartition theorem and quantum-mechanical wave functions, describing probability amplitudes that are represented by complex numbers. Indeed, complex numbers are numbers too, and Pythagoras would have reveled in their beauty. In fact, I can’t help thinking that, if he could have imagined them, he would surely have created a ‘religion’ around Euler’s formula, rather than around the tetrad. 🙂
In any case… Let’s leave the jokes and the silly comparisons aside, as that’s not what I want to write about in this post (if you want to read more about this, I’ll refer you another blog of mine). In this post, I want to present the basics of vector calculus, an understanding of which is absolutely essential in order to gain both a mathematical as well as a ‘physical’ understanding of what fields really are. So that’s classical mechanics once again. However, as I found out, one can’t study quantum mechanics without going through the required prerequisites. So let’s go for it.
Vectors in math and physics
What’s a vector? It may surprise you, but the term ‘vector’, in physics and in math, refers to more than a dozen different concepts, and that’s a major source of confusion for people like us–autodidacts. The term ‘vector’ refers to many different things indeed. The most common definitions are:
- The term ‘vector’ often refers to a (one-dimensional) array of numbers. In that case, a vector is, quite simply, an element of Rn, while the array will be referred to as an n-tuple. This definition can be generalized to also include arrays of alphanumerical values, or blob files, or any type of object really, but that’s a definition that’s more relevant for other sciences – most notably computer science. In math and physics, we usually limit ourselves to arrays of numbers. However, you should note that a ‘number’ may also be a complex number, and so we have real as well as complex vector spaces. The most straightforward example of a complex vector space is the set of complex numbers itself: C. In that case, the n-tuple is a ‘1-tuple’, aka as a singleton, but the element in it (i.e. a complex number) will have ‘two dimensions’, so to speak. [Just like the term ‘vector’, the term ‘dimension’ has various definitions in math and physics too, and so it may be quite confusing.] However, we can also have 2-tuples, 3-tuples or, more in general, n-tuples of complex numbers. In that case, the vector space is denoted by Cn. I’ve written about vector spaces before and so I won’t say too much about this.
- A vector can also be a point vector. In that case, it represents the position of a point in physical space – in one, two or three dimensions – in relation to some arbitrarily chosen origin (i.e. the zero point). As such, we’ll usually write it as x (in one dimension) or, in three dimensions, as (x, y, z). More generally, a point vector is often denoted by the bold-face symbol R. This definition is obviously ‘related’ to the definition above, but it’s not the same: we’re talking physical space here indeed, not some ‘mathematical’ space. Physical space can be curved, as you obviously know when you’re reading this blog, and I also wrote about that in the above-mentioned post, so you can re-visit that topic too if you want. Here, I should just mention one point which may or may not confuse you: while (two-dimensional) point vectors and complex numbers have a lot in common, they are not the same, and it’s important to understand both the similarities as well as the differences between both. For example, multiplying two vectors and multiplying two complex numbers is definitely not the same. I’ll come back to this.
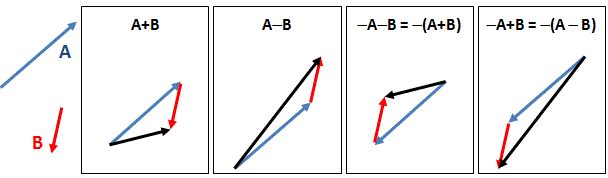
- A vector can also be a displacement vector: in that case, it will specify the change in position of a point relative to its previous position. Again, such displacement vectors may be one-, two-, or three-dimensional, depending on the space we’re envisaging, which may be one-dimensional (a simple line), two-dimensional (i.e. the plane), three-dimensional (i.e. three-dimensional space), or four-dimensional (i.e. space-time). A displacement vector is often denoted by s or ΔR, with the delta indicating we’re talking a a distance or a difference indeed: s = ΔR = R2 – R1 = (x2 – x1, y2 – y1, z2 – z1). That’s kids’ stuff, isn’t it?
- A vector may also refer to a so-called four-vector: a four-vector obeys very specific transformation rules, referred to as the Lorentz transformation. In this regard, you’ve surely heard of space-time vectors, referred to as events, and noted as X = (ct, r), with r the spatial vector r = (x, y, z) and c the speed of light (which, in this case, is nothing but a proportionality constant ensuring that space and time are measured in compatible units). So we can also write X as X = (ct, x, y, z). However, there is another four-vector which you’ve probably also seen already (see, for example, my post on (special) Relativity Theory): P = (E/c, p), which relates energy and momentum in spacetime. Of course, spacetime can also be curved. In fact, Einstein’s (general) Relativity Theory is about the curvature of spacetime, not of ordinary space. But I should not write more about this here, as it’s about time I get back to the main story line of this post.
- Finally, we also have vector operators, like the gradient vector ∇. Now that is what I want to write about in this post. Vector operators are also considered to be ‘vectors’ – to some extent, at least: we use them in a ‘vector products’, for example, as I will show below – but, because they are operators and, as such, “hungry for something to operate on”, they are obviously quite different from any of the ‘vectors’ I defined in point (1) to (4) above. [Feynman attributes this ‘hungry for something to operate on’ expression to the British mathematician Sir James Hopwood Jeans, who’s best known from the infamous Rayleigh-Jeans law, whose inconsistency with observations is known as the ultraviolet catastrophe or ‘black-body radiation problem’. But that’s a fairly useless digression so let me got in with it.]
In a text on physics, the term ‘vector’ may refer to any of the above but it’s often the second and third definition (point and/or displacement vectors) that will be implicit. As mentioned above, I want to write about the fifth ‘type’ of vector: vector operators. Now, the title of this post is ‘vector calculus’, and so you’ll immediately wonder why I say these vector operators may or may not be defined as vectors. Moreover, the fact of the matter is that these operators operate on yet another type of ‘vector’ – so that’s a sixth definition I need to introduce here: field vectors.
Now, funnily enough, the term ‘field vector’, while being the most obvious description of what it is, is actually not widely used: what I call a ‘field vector’ is often referred to as a gradient vector, and the vectors E and B are usually referred to as the electric or magnetic field, tout court. Indeed, if you google the terms ‘electromagnetic vector’ (or electric or magnetic vector), you will usually be redirected. However, when everything is said and done, E and B are vectors: they have a magnitude, and they have a direction. To be even more precise, while they depend on both space and time – so we can write E as E = E(x, y, z, t) and we have four independent variables here – they have three components: one of each direction in space, so we can write E as:
E = E(x, y, z, t) = [Ex, Ey, Ez] = [Ex(x, y, z, t), Ey(x, y, z, t), Ez(x, y, z, t)]
So, truth be told, vector calculus (aka vector analysis) in physics is about (vector) fields and (vector) operators,. While the ‘scene’ for these fields and operators is, obviously, physical space (or spacetime) and, hence, a vector space, it’s good to be clear on terminology and remind oneself that, in physics, vector calculus is not about mathematical vectors: it’s about real stuff. That’s why Feynman prefers a much longer term than vector calculus or vector analysis: he calls it differential calculus of vector fields which, indeed, is what it is – but I am sure you would not have bothered starting reading this post if I would have used that term too. 🙂
Now, this has probably become the longest introduction ever to a blog post, and so I had better get on with it. 🙂
Vector fields and scalar fields
Let’s dive straight into it. Vector fields like E and B behave like h, which is the symbol used in a number of textbooks for the heat flow in some body or block of material: E, B and h are all vector fields derived from a scalar field.
Huh? Scalar field? Aren’t we talking vectors? We are. If I say we can derive the vector field h (i.e. the heat flow) from a scalar field, I am basically saying that the relationship between h and the temperature T (i.e. the scalar field) is direct and very straightforward. Likewise, the relationship between E and the scalar field Φ is also direct and very straightforward.
[To be fully precise and complete, I should qualify the latter statement: it’s only true in electrostatics, i.e. when we’re considering charges that don’t move. When we have moving charges, magnetic effects come into play, and then we have a more complicated relationship between (i) two scalar fields, namely A (the magnetic potential – i.e. the ‘magnetic scalar field’) and Φ (the electrostatic potential, or ‘electric scalar field’), and (ii) two vector fields, namely B and E. The relationships between the two are then a bit more complicated than the relationship between T and h. However, the math involved is the same. In fact, the complication arises from the fact that magnetism is actually a relativistic effect. However, at this stage, this statement will only confuse you, and so I will write more about that in my next post.]
Let’s look at h and T. As you know, the temperature is a measure for energy. In a block of material, the temperature T will be a scalar: some real number that we can measure in Kelvin, Fahrenheit or Celsius but – whatever unit we use – any observer using the same unit will measure the same at any given point. That’s what distinguishes a ‘scalar’ quantity from ‘real numbers’ in general: a scalar field is something real. It represents something physical. A real number is just… Well… A real number, i.e. a mathematical concept only.
The same is true for a vector field: it is something real. As Feynman puts it: “It is not true that any three numbers form a vector [in physics]. It is true only if, when we rotate the coordinate system, the components of the vector transform among themselves in the correct way.” What’s the ‘correct way’? It’s a way that ensures that any observer using the same unit will measure the same at any given point.
How does it work?
In physics, we associate a point in space with physical realities, such as:
- Temperature, the ‘height‘ of a body in a gravitational field, or the pressure distribution in a gas or a fluid, are all examples of scalar fields: they are just (real) numbers from a math point of view but, because they do represent a physical reality, these ‘numbers’ respect certain mathematical conditions: in practice, they will be a continuous or continuously differentiable function of position.
- Heat flow (h), the velocity (v) of the molecules/atoms in a rotating object, or the electric field (E), are examples of vector fields. As mentioned above, the same condition applies: any observer using the same unit should measure the same at any given point.
- Tensors, which represent, for example, stress or strain at some point in space (in various directions), or the curvature of space (or spacetime, to be fully correct) in the general theory of relativity.
- Finally, there are also spinors, which are often defined as a “generalization of tensors using complex numbers instead of real numbers.” They are very relevant in quantum mechanics, it is said, but I don’t know enough about them to write about them, and so I won’t.
How do we derive a vector field, like h, from a scalar field (i.e. T in this case)? The two illustrations below (taken from Feynman’s Lectures) illustrate the ‘mechanics’ behind it: heat flows, obviously, from the hotter to the colder places. At this point, we need some definitions. Let’s start with the definition of the heat flow: the (magnitude of the) heat flow (h) is the amount of thermal energy (ΔJ) that passes, per unit time and per unit area, through an infinitesimal surface element at right angles to the direction of flow.

A vector has both a magnitude and a direction, as defined above, and, hence, if we define ef as the unit vector in the direction of flow, we can write:
h = h·ef = (ΔJ/Δa)·ef
ΔJ stands for the thermal energy flowing through an area marked as Δa in the diagram above per unit time. So, if we incorporate the idea that the aspect of time is already taken care of, we can simplify the definition above, and just say that the heat flow is the flow of thermal energy per unit area. Simple trigonometry will then yield an equally simple formula for the heat flow through any surface Δa2 (i.e. any surface that is not at right angles to the heat flow h):
ΔJ/Δa2 = (ΔJ/Δa1)cosθ = h·n

When I say ‘simple’, I must add that all is relative, of course, Frankly, I myself did not immediately understand why the heat flow through the Δa1 and Δa2 areas below must be the same. That’s why I added the blue square in the illustration above (which I took from Feynman’s Lectures): it’s the same area as Δa1, but it shows more clearly – I hope! – why the heat flow through the two areas is the same indeed, especially in light of the fact that we are looking at infinitesimally small areas here (so we’re taking a limit here).
As for the cosine factor in the formula above, you should note that, in that ΔJ/Δa2 = (ΔJ/Δa1)cosθ = h·n equation, we have a dot product (aka as a scalar product) of two vectors: (1) h, the heat flow and (2) n, the unit vector that is normal (orthogonal) to the surface Δa2. So let me remind you of the definition of the scalar (or dot) product of two vectors. It yields a (real) number:
A·B = |A||B|cosθ, with θ the angle between A and B
In this case, h·n = |h||n|cosθ = |h|·1·cosθ = |h|cosθ = h·cosθ. What we are saying here is that we get the component of the heat flow that’s perpendicular (or normal, as physicists and mathematicians seem to prefer to say) to the surface Δa2 by taking the dot product of the heat flow h and the unit normal n. We’ll use this formula later, and so it’s good to take note of it here.
OK. Let’s get back to the lesson. The only thing that we need to do to prove that ΔJ/Δa2 = (ΔJ/Δa1)cosθ formula is show that Δa2 = Δa1/cosθ or, what amounts to the same, that Δa1 = Δa2cosθ. Now that is something you should be able to figure out yourself: it’s quite easy to show that the angle between h and n is equal to the angle between the surfaces Δa1 and Δa2. The rest is just plain triangle trigonometry.
For example, when the surfaces coincide, the angle θ will be zero and then h·n is just equal to |h|cosθ = |h| = h·1 = h = ΔJ/Δa1. The other extreme is that orthogonal surfaces: in that case, the angle θ will be 90° and, hence, h·n = |h||n|cos(π/2) = |h|·1·0 = 0: there is no heat flow normal to the direction of heat flow.
OK. That’s clear enough. The point to note is that the vectors h and n represent physical entities and, therefore, they do not depend on our reference frame (except for the units we use to measure things). That allows us to define vector equations.
The ∇ (del) operator and the gradient
Let’s continue our example of temperature and heat flow. In a block of material, the temperature (T) will vary in the x, y and z direction and, hence, the partial derivatives ∂T/∂x, ∂T/∂y and ∂T/∂z make sense: they measure how the temperature varies with respect to position. Now, the remarkable thing is that the 3-tuple (∂T/∂x, ∂T/∂y, ∂T/∂z) is a physical vector itself: it is independent, indeed, of the reference frame (provided we measure stuff in the same unit) – so we can do a translation and/or a rotation of the coordinate axes and we get the same value. This means this set of three numbers is a vector indeed:
(∂T/∂x, ∂T/∂y, ∂T/∂z) = a vector
If you like to see a formal proof of this, I’ll refer you to Feynman once again – but I think the intuitive argument will do: if temperature and space are real, then the derivatives of temperature in regard to the x-, y- and z-directions should be equally real, isn’t it? Let’s go for the more intricate stuff now.
If we go from one point to another, in the x-, y- or z-direction, then we can define some (infinitesimally small) displacement vector ΔR = (Δx, Δy, Δz), and the difference in temperature between two nearby points (ΔT) will tend to the (total) differential of T – which we denote by ΔT – as the two point get closer and closer. Hence, we write:
ΔT = (∂T/∂x)Δx + (∂T/∂y)Δy + (∂T/∂z)Δz
The two equations above combine to yield:
ΔT = (∂T/∂x, ∂T/∂y, ∂T/∂z)(Δx, Δy, Δz) = ∇T·ΔR
In this equation, we used the ∇ (del) operator, i.e. the vector differential operator. It’s an operator like the differential operator ∂/∂x (i.e. the derivative) but, unlike the derivative, it returns not one but three values, i.e. a vector, which is usually referred to as the gradient, i.e. ∇T in this case. More in general, we can write ∇f(x, y, z), ∇ψ or ∇ followed by whatever symbol for the function we’re looking at.
In other words, the ∇ operator acts on a scalar-valued function (T), aka a scalar field, and yields a vector:
∇T = (∂T/∂x, ∂T/∂y, ∂T/∂z)
That’s why we write ∇ in bold-type too, just like the vector R. Indeed, using bold-type (instead of an arrow or so) is a convenient way to mark a vector, and the difference (in print) between ∇ and ∇ is subtle, but it’s there – and for a good reason as you can see!
[To be precise, I should add that we do not write all of the operators that return three components in bold-type. The most simple example is the common derivative ∂E/∂t = [∂Ex/∂t, ∂Ey/∂t, ∂Ez/∂t]. We have a lot of other possible combinations. Some make sense, and some don’t, like ∂h/∂y = [∂hx/∂y, ∂hy/∂y, ∂hz/∂y], for example.]
If ∇T is a vector, what’s its direction? Think about it. […] The rate of change of T in the x-, y- and z-direction are the x-, y- and z-component of our ∇T vector respectively. In fact, the rate of change of T in any direction will be the component of the ∇T vector in that direction. Now, the magnitude of a vector component will always be smaller than the magnitude of the vector itself, except if it’s the component in the same direction as the vector, in which case the component is the vector. [If you have difficulty understanding this, read what I write once again, but very slowly and attentively.] Therefore, the direction of ∇T will be the direction in which the (instantaneous) rate of change of T is largest. In Feynman’s words: “The gradient of T has the direction of the steepest uphill slope in T.” Now, it should be quite obvious what direction that really is: it is the opposite direction of the heat flow h.
That’s all you need to know to understand our first real vector equation:
h = –κ∇T
Indeed, you don’t need too much math to understand this equation in the way we want to understand it, and that’s in some kind of ‘physical‘ way (as opposed to just the math side of it). Let me spell it out:
- The direction of heat flow is opposite to the direction of the gradient vector ∇T. Hence, heat flows from higher to lower temperature (i.e. ‘downhill’), as we would expect, of course!). So that’s the minus sign.
- The magnitude of h is proportional to the magnitude of the gradient ∇T, with the constant of proportionality equal to κ (kappa), which is called the thermal conductivity. Now, in case you wonder what this means (again: do go beyond the math, please!), remember that the heat flow is the flow of thermal energy per unit area (and per unit time, of course): |h| = h = ΔJ/Δa.
But… Yes? Why would it be proportional? Why don’t we have some exponential relation or something? Good question, but the answer is simple, and it’s rooted in physical reality – of course! The heat flow between two places – let’s call them 1 and 2 – is proportional to the temperature difference between those two places, so we have: ΔJ ∼ T2 – T1. In fact, that’s where the factor of proportionality comes in. If we imagine a very small slab of material (infinitesimally small, in fact) with two faces, parallel to the isothermals, with a surface area ΔA and a tiny distance Δs between them, we can write:
ΔJ = κ(T2 – T1)ΔA/Δs = ΔJ = κ·ΔT·ΔA/Δs ⇔ ΔJ/ΔA = κΔT/Δs
Now, we defined ΔJ/ΔA as the magnitude of h. As for its direction, it’s obviously perpendicular (not parallel) to the isothermals. Now, as Δs tends to zero, ΔT/Δs is nothing but the rate of change of T with position. We know it’s the maximum rate of change, because the position change is also perpendicular to the isotherms (if the faces are parallel, that tiny distance Δs is perpendicular). Hence, ΔT/Δs must be the magnitude of the gradient vector (∇T). As its direction is opposite to that of h, we can simply pop in a minus sign and switch from magnitudes to vectors to write what we wrote already: h = –κ∇T.
But let’s get back to the lesson. I think you ‘get’ all of the above. In fact, I should probably not have introduced that extra equation above (the ΔJ expression) and all the extra stuff (i.e. the ‘infinitesimally small slab’ explanation), as it probably only confuses you. So… What’s the point really? Well… Let’s look, once again, at that equation h = –κ∇T and let us generalize the result:
- We have a scalar field here, the temperature T – but it could be any scalar field really!
- When we have the ‘formula’ for the scalar field – it’s obviously some function T(x, y, z) – we can derive the heat flow h from it, i.e. a vector quantity, which has a property which we can vaguely refer to as ‘flow’.
- We do so using this brand-new operator ∇. That’s a so-called vector differential operator aka the del operator. We just apply it to the scalar field and we’re done! The only thing left is to add some proportionality factor, but so that’s just because of our units. [In case you wonder about the symbol it self, ∇ is the so-called nabla symbol: the name comes from the Hebrew word for a harp, which has a similar shape indeed.]
This truly is a most remarkable result, and we’ll encounter the same equation elsewhere. For example, if the electric potential is Φ, then we can immediately calculate the electric field using the following formula:
E = –∇Φ
Indeed, the situation is entirely analogous from a mathematical point of view. For example, we have the same minus sign, so E also ‘flows’ from higher to lower potential. Where’s the factor of proportionality? Well… We don’t have one, as we assume that the units in which we measure E and Φ are ‘fully compatible’ (so don’t worry about them now). Of course, as mentioned above, this formula for E is only valid in electrostatics, i.e. when there are no moving charges. When moving charges are involved, we also have the magnetic force coming into play, and then equations become a bit more complicated. However, this extra complication does not fundamentally alter the logic involved, and I’ll come back to this so you see how it all nicely fits together.
Note: In case you feel I’ve skipped some of the ‘explanation’ of that vector equation h = –κ∇T… Well… You may be right. I feel that it’s enough to simply point out that ∇T is a vector with opposite direction to h, so that explains the minus sign in front of the ∇T factor. The only thing left to ‘explain’ then is the magnitude of h, but so that’s why we pop in that kappa factor (κ), and so we’re done, I think, in terms of ‘understanding’ this equation. But so that’s what I think indeed. Feynman offers a much more elaborate ‘explanation‘, and so you can check that out if you think my approach to it is a bit too much of a shortcut.
Interim summary
So far, we have only have shown two things really:
[I] The first thing to always remember is that h·n product: it gives us the component of ‘flow’ (per unit time and per unit area) of h perpendicular through any surface element Δa. Of course, this result is valid for any other vector field, or any vector for that matter: the scalar product of a vector and a unit vector will always yield the component of that vector in the direction of that unit vector. [But note the second vector needs to be a unit vector: it is not generally true that the dot product of one vector with another yields the component of the first vector in the direction of the second: there’s a scale factor that comes into play.]
Now, you should note that the term ‘component’ (of a vector) usually refers to a number (not to a vector) – and surely in this case, because we calculate it using a scalar product! I am just highlighting this because it did confuse me for quite a while. Why? Well… The concept of a ‘component’ of a vector is, obviously, intimately associated with the idea of ‘direction’: we always talk about the component in some direction, e.g. in the x-, y- or z-direction, or in the direction of any combination of x, y and z. Hence, I think it’s only natural to think of a ‘component’ as a vector in its own right. However, as I note here, we shouldn’t do that: a ‘component’ is just a magnitude, i.e. a number only. If we’d want to include the idea of direction, it’s simple: we can just multiply the component with the normal vector n once again, and then we have a vector quantity once again, instead of just a scalar. So then we just write (h·n)·n = (h·n)n. Simple, isn’t it? 🙂
[As I am smiling here, I should quickly say something about this dot (·) symbol: we use the same symbol here for (i) a product between scalars (i.e. real or complex numbers), like 3·4; (ii) a product between a scalar and a vector, like 3·v – but then I often omit the dot to simply write 3v; and, finally, (iii) a scalar product of two vectors, like h·n indeed. We should, perhaps, introduce some new symbol for multiplying numbers, like ∗ for example, but then I hope you’re smart enough to see from the context what’s going on really.]
Back to the lesson. Let me jot down the formula once again: h·n = |h||n|cosθ = h·cosθ. Hence, the number we get here is h (i.e. the amount of heat flow in the direction of flow) multiplied by cosθ, with θ the angle between (i) the surface we’re looking at (which, as mentioned above, is any surface really) and (ii) the surface that’s perpendicular to the direction of flow.
Hmm… […] The direction of flow? Let’s take a moment to think about what we’re saying here. Is there any particular or unique direction really? Heat flows in all directions from warmer to colder areas, and not just in one direction, doesn’t it? You’re right. Once again, the terminology may confuse you – which is yet another reason why math is so much better as a language to express physical ideas 🙂 – and so we should be precise: the direction of h is the direction in which the amount of heat flow (i.e. h·cosθ) is largest (hence, the angle θ is zero). As we pointed out above, that’s the direction in which the temperature T changes the fastest. In fact, as Feynman notes: “We can, if we wish, consider that this statement defines h.”
That brings me to the second thing you should – always and immediately – remember from all of that I’ve written above.
[II] If we write the infinitesimal (i.e. the differential) change in temperature (in whatever direction) as ΔT, then we know that
ΔT = (∂T/∂x, ∂T/∂y, ∂T/∂z)(Δx, Δy, Δz) = ∇T·ΔR
Now, what does this say really? ΔR is an (infinitesimal) displacement vector: ΔR = (Δx, Δy, Δz). Hence, it has some direction. To be clear: that can be any direction in space really. So that’s simple. What about the second factor in this dot product, i.e. that gradient vector ∇T?
The direction of the gradient (i.e. ∇T) is not just ‘any direction’: it’s the direction in which the rate of change of T is largest, and we know what direction that is: it’s the opposite direction of the heat flow h, as evidenced by the minus sign in our vector equations h = –κ∇T or E = –∇Φ. So, once again, we have a (scalar) product of two vectors here, ∇T·ΔR, which yields… Hmm… Good question. That ∇T·ΔR expression is very similar to that h·n expression above, but it’s not quite the same. It’s also a vector dot product – or a scalar product, in other words, but, unlike that n vector, the ΔR vector is not a unit vector: it’s an infinitesimally small displacement vector. So we do not get some ‘component’ of ∇T. More in general, you should note that the dot product of two vectors A and B does not, in general, yield the component of A in the direction of B, unless B is a unit vector – which, again, is not the case here. So if we don’t have that here, what do we have?
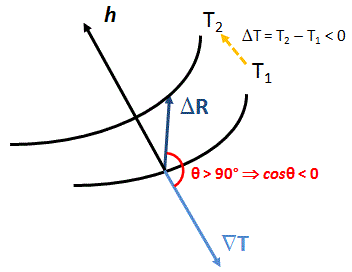
Let’s look at the (physical) geometry of the situation once again. Heat obviously flows in one direction only: from warmer to colder places – not in the opposite direction. Therefore, the θ in the h·n = h·cosθ expression varies from –90° to +90° only. Hence, the cosine factor (cosθ) is always positive. Always. Indeed, we do not have any right- or left-hand rule here to distinguish between the ‘front’ side and the ‘back’ side of our surface area. So when we’re looking at that h·n product, we should remember that that normal unit vector n is a unit vector that’s normal to the surface but which is oriented, generally, towards the direction of flow. Therefore, that h·n product will always yield some positive value, because θ varies from –90° to +90° only indeed.
When looking at that ΔT = ∇T·ΔR product, the situation is quite different: while ∇T has a very specific direction (I really mean unique) – which, as mentioned above is opposite to that of h – that ΔR vector can point in any direction – and then I mean literally any direction, including directions ‘uphill’. Likewise, it’s obvious that the temperature difference ΔT can be both positive or negative (or zero, when we’re moving on a isotherm itself). In fact, it’s rather obvious that, if we go in the direction of flow, we go from higher to lower temperatures and, hence, ΔT will, effectively, be negative: ΔT = T2 – T1 < 0, as shown below.
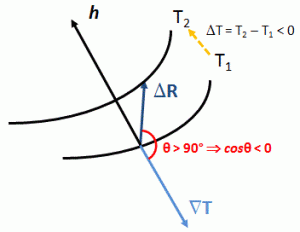
Now, because |∇T| and |ΔR| are absolute values (or magnitudes) of vectors, they are always positive (always!). Therefore, if ΔT has a minus sign, it will have to come from the cosine factor in the ΔT = ∇T·ΔR = |∇T|·|ΔR|·cosθ expression. [Again, if you wonder where this expression comes from: it’s just the definition of a vector dot product.] Therefore, ΔT and cosθ will have the same sign, always, and θ can have any value between –180° to +180°. In other words, we’re effectively looking at the full circle here. To make a long story short, we can write the following:
ΔT = |∇T|·|ΔR|·cosθ = |∇T|·ΔR·cosθ ⇔ ΔT/ΔR = |∇T|cosθ
As you can see, θ is the angle between ∇T and ΔR here and, as mentioned above, it can take on any value – well… Any value between –180° to +180°, that is. ΔT/ΔR is, obviously, the rate of change of T in the direction of ΔR and, from the expression above, we can see it is equal to the component of ∇T in the direction of ΔR:
ΔT/ΔR = |∇T|cosθ
So we have a negative component here? Yes. The rate of change is negative and, therefore, we have a negative component. Indeed, any vector has components in all directions, including directions that point away from it. However, in the directions that point away from it, the component will be negative. More in general, we have the following interesting result: the rate of change of a scalar field ψ in the direction of a (small) displacement ΔR is the component of the gradient ∇ψ along that displacement. We write that result as:
Δψ/ΔR = |∇ψ|cosθ
[Note the (not so) subtle difference between ΔR (i.e. a vector) and ΔR (some real number). It’s quite important. ]
We’ve said a lot of (not so) interesting things here, but we still haven’t answered the original question: what’s ∇T·ΔR? Well… We can’t say more than what we said already: it’s equal to ΔT, which is a differential: ΔT = (∂T/∂x)Δx + (∂T/∂y)Δy + (∂T/∂z)Δz. A differential and a derivative (i.e. a rate of change) are not the same, but they are obviously closely related, as evidenced from the equations above: the rate of change is the change per unit distance. [Likewise, note that |∇ψ|cosθ is just a product of two real numbers, while ∇T·ΔR is a vector dot product, i.e. a (scalar) product of two vectors!]
In any case, this is enough of a recapitulation. In fact, this ‘interim summary’ has become longer than the preceding text! We’re now ready to discuss what I’ll call the First Theorem of vector calculus in physics. Of course, never mind the term: what’s first or second or third doesn’t matter really: you’ll need all of the theorems below to understand vector calculus.
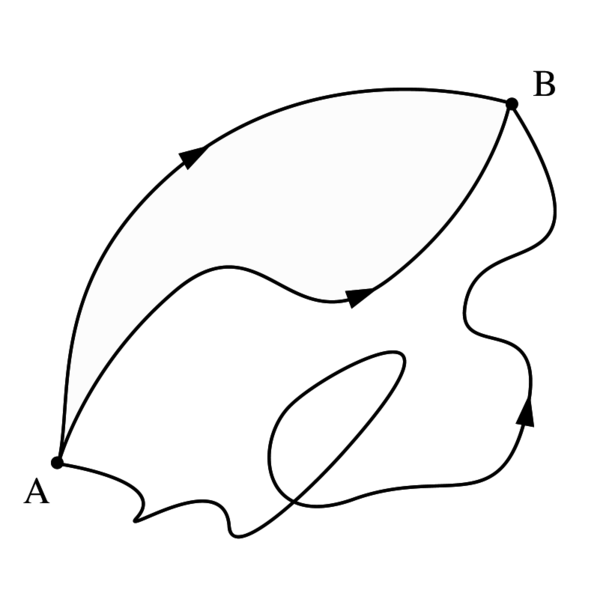
The First Theorem
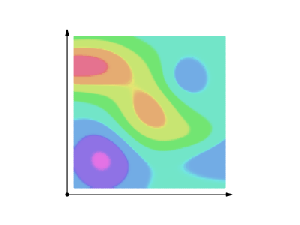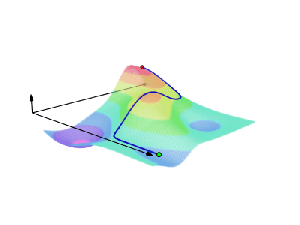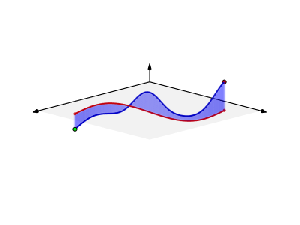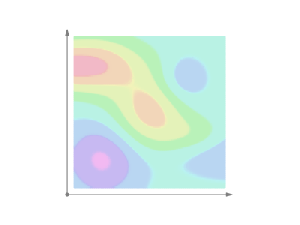
Let’s assume we have some scalar field ψ in space: ψ might be the temperature, but it could be any scalar field really. Now, if we go from one point (1) to another (2) in space, as shown below, we’ll follow some arbitrary path, which is denoted by the curve Γ in the illustrations below. Each point along the curve can then be associated with a gradient ∇ψ (think of the h = –κ∇T and E = –∇Φ expressions above if you’d want examples). Its tangential component is obviously equal to (∇ψ)t·Δs = ∇ψ·Δs. [Please note, once again, the subtle difference between Δs (with the s in bold-face) and Δs: Δs is a vector, and Δs is its magnitude.]
As shown in the illustrations above, we can mark off the curve at a number of points (a, b, c, etcetera) and join these points by straight-line segments Δsi. Now let’s consider the first line segment, i.e. Δs1. It’s obvious that the change in ψ from point 1 to point a is equal to Δψ1 = ψ(a) – ψ(1). Now, we have that general Δψ = (∂ψ/∂x, ∂ψ/∂y, ∂ψ/∂z)(Δx, Δy, Δz) = ∇ψ·Δs equation. [If you find it difficult to interpret what I am writing here, just substitute ψ for T and Δs for ΔR.] So we can write:
Δψ1 = ψ(a) – ψ(1) = (∇ψ)1·Δs1
Likewise, we can write:
ψ(b) – ψ(a) = (∇ψ)2·Δs1
In these expressions, (∇ψ)1 and (∇ψ)2 mean the gradient evaluated at segment Δs1 and point Δs2 respectively, not at point 1 and 2 – obviously. Now, if we add the two equations above, we get:
ψ(b) – ψ(1) = (∇ψ)1·Δs1 + (∇ψ)2·Δs1
To make a long story short, we can keep adding such terms to get:
ψ(2) – ψ(1) = ∑(∇ψ)i·Δsi
We can add more and more segments and, hence, take a limit: as Δsi tends to zero, ∑ becomes a sum of an infinite number of terms – which we denote using the integral sign ∫ – in which ds is – quite simply – just the infinitesimally small displacement vector. In other words, we get the following line integral along that curve Γ:
This is a gem, and our First Theorem indeed. It’s a remarkable result, especially taking into account the fact that the path doesn’t matter: we could have chosen any curve Γ indeed, and the result would be the same. So we have:
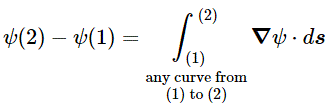
You’ll say: so what? What do we do with this? Well… Nothing much for the moment, but we’ll need this result later. So I’d say: just hang in there, and note this is the first significant use of our del operator in a mathematical expression that you’ll encounter very often in physics. So just let it sink in, and allow me to proceed with the rest of the story.
Before doing so, however, I should note that even Feynman sins when trying to explain this theorem in a more ‘intuitive’ way. Indeed, in his Lecture on the topic, he writes the following: “Since the gradient represents the rate of change of a field quantity, if we integrate that rate of change, we should get the total change.” Now, from that Δψ/ΔR = |∇ψ|cosθ formula, it’s obvious that the gradient is the rate of change in a specific direction only. To be precise, in this particular case – with the field quantity ψ equal to the temperature T – it’s the direction in which T changes the fastest.
You should also note that the integral above is not the type of integral you known from high school. Indeed, it’s not of the rather straightforward ∫f(x)dx type, with f(x) the integrand and dx the variable of integration. That type of integral, we knew how to solve. A line integral is quite different. Look at it carefully: we have a vector dot product after the ∫ sign. So, unlike what Feynman suggests, it’s not just a matter of “integrating the rate of change.”
Now, I’ll refer you to Wikipedia for a good discussion of what a line integral really is, but I can’t resist the temptation to copy the animation in that article, because it’s very well made indeed. While it shows that we can think of a line integral as the two- or three-dimensional equivalent of the standard type of integral we learned to solve in high school (you’ll remember the solution was also the area under the graph of the function that had to be integrated), the way to go about it is quite different. Solving them will, in general, involve some so-called parametrization of the curve C.
However, this post is becoming way too long and, hence, I really need to move on now.
Operations with ∇: divergence and curl
You may think we’ve covered a lot of ground already, and we did. At the same time, everything I wrote above is actually just the start of it. I emphasized the physics of the situation so far. Let me now turn to the math involved. Let’s start by dissociating the del operator from the scalar field, so we just write:
∇ = (∂/∂x, ∂/∂y, ∂/∂z)
This doesn’t mean anything, you’ll say, because the operator has nothing to operate on. And, yes, you’re right. However, in math, it doesn’t matter: we can combine this ‘meaningless’ operator (which looks like a vector, because it has three components) with something else. For example, we can do a vector dot product:
∇·(a vector)
As mentioned above, we can ‘do’ this product because ∇ has three components, so it’s a ‘vector’ too (although I find such name-giving quite confusing), and so we just need to make sure that the vector we’re operating on has three components too. To continue with our heat flow example, we can write, for example:
∇·h = (∂/∂x, ∂/∂y, ∂/∂z)·(hx, hy, hz) = ∂hx/∂x + ∂hy/∂y, ∂hz/∂z
This del operator followed by a dot, and acting on a vector – i.e. ∇·(vector) – is, in fact, a new operator. Note that we use two existing symbols, the del (∇) and the dot (·), but it’s one operator really. [Inventing a new symbol for it would not be wise, because we’d forget where it comes from and, hence, probably scratch our head when we’d see it.] It’s referred to as a vector operator, just like the del operator, but don’t worry about the terminology here because, once again, the terminology here might confuse you. Indeed, our del operator acted on a scalar to yield a vector, and now it’s the other way around: we have an operator acting on a vector to return a scalar. In a few minutes, we’ll define yet another operator acting on a vector to return a vector. Now, all of these operators are so-called vector operators, not because there’s some vector involved, but because they all involve the del operator. It’s that simple. So there’s no such thing as a scalar operator. 🙂 But let me get back to the main line of the story. This ∇· operator is quite important in physics, and so it has a name (and an abbreviated notation) of its own:
∇·h = div h = the divergence of h
The physical significance of the divergence is related to the so-called flux of a vector field: it measures the magnitude of a field’s source or sink at a given point. Continuing our example with temperature, consider air as it is heated or cooled. The relevant vector field is now the velocity of the moving air at a point. If air is heated in a particular region, it will expand in all directions such that the velocity field points outward from that region. Therefore the divergence of the velocity field in that region would have a positive value, as the region is a source. If the air cools and contracts, the divergence has a negative value, as the region is a sink.
A less intuitive but more accurate definition is the following: the divergence represents the volume density of the outward flux of a vector field from an infinitesimal volume around a given point.
Phew! That sounds more serious, doesn’t it? We’ll come back to this definition when we’re ready to define the concept of flux somewhat accurately. For now, just note two of Maxwell’s famous equations involve the divergence operator:
∇·E = ρ/ε0 and ∇·B = 0
In my previous post, I gave a verbal description of those two equations:
- The flux of E through a closed surface = (the net charge inside)/ε0
- The flux of B through a closed surface = zero
The first equation basically says that electric charges cause an electric field. The second equation basically says there is no such thing as a magnetic charge: the magnetic force only appears when charges are moving and/or when electric fields are changing. Note that we’re talking closed surface here, so they define a volume indeed. We can also look at the flux through a non-closed surface (and we’ll do that shortly) but, in the context of Maxwell’s equations, we’re talking volumes and, hence, closed surfaces.
Let me quickly throw in some remarks on the units in which we measure stuff. Electric field strength (so the unit we use to measure the magnitude of E) is measured in Newton per Coulomb, so force divided by charge. That makes sense, because E is defined as the force on the unit charge: E = F/q, and so the unit is N/C. Please do think about why we have q in the denominator: if we’d have the same force on an electric charge that is twice as big, then we’d have a field strength that’s only half, so we have an inverse proportionality here. Conversely, if we’d have twice the force on the same electric charge, the field strength would also double.
Now, flux and field strength are obviously related, but not the same. The flux is obviously proportional to the field strength (expressed in N/C), but then we also know it’s some number expressed per unit area. Hence, you might think that the unit of flux is field strength per square meter, i.e. N/C/m2. It’s not. It’s a stupid mistake, but one that is commonly made. Flux is expressed in N/C times m2, so that’s the product (N/C)·m2 = (N·m/C)·m = (J/C)·m. Why is that? Think about the common graphical representation of a field: we just draw lines, all tangent to the direction of the field vector at every point, and the density of the lines (i.e. the number of lines per unit area) represents the magnitude of our electric field vector. Now, the flux through some area is the number of lines we count in that area. Hence, if you double the area, you should get twice the flux. Halve the area, and you should get half the flux. So we have a direct proportionality here. In fact, assuming the electric field is uniform, we can write the (electric) flux as the product of the field strength E and the (vector) area S, so we write ΦE = E·S = E·S·cosθ.
Huh? Yes. The origin of the mistake is that we, somehow, think the ‘per unit area’ qualification comes with the flux. It doesn’t: it’s in the idea of field strength itself. Indeed, an alternative to the presentation above is just to draw arrows representing the same field strength, as illustrated below. However, instead of drawing more arrows (of some standard length) to represent increasing field strength, we’d just draw longer arrows—not more of them. So then the idea of the number of lines per unit area is no longer valid.
[…] OK. I realize I am probably just confusing you here. Just one more thing, perhaps. We also have magnetic flux, denoted as ΦB, and it’s defined in the same way: ΦB = B·S = B·S·cosθ. However, because the unit of magnetic field strength is different, the unit of magnetic flux is different too. It’s the weber, and I’ll let you look up its definition yourself. 🙂 Note that it’s a bit of a different beast, because the magnetic force is a bit of a different beast. 🙂
So let’s get back to our operators. You’ll anticipate the second new operator now, because that’s the one that appears in the other two equations in Maxwell’s set of equations. It’s the cross product:
∇×E = (∂/∂x, ∂/∂y, ∂/∂z)×(Ex, Ey, Ez) = … What?
Well… The cross product is not as straightforward to write down as the dot product. We get a vector indeed, not a scalar, and its three components are:
(∇×E)z = ∇xEy – ∇yEx = ∂Ey/∂x – ∂Ex/∂y
(∇×E)x = ∇yEz – ∇zEy = ∂Ez/∂y – ∂Ey/∂z
(∇×E)y = ∇zEx – ∇xEz = ∂Ex/∂z – ∂Ez/∂x
I know this looks pretty monstrous, but so that’s how cross products work. Please do check it out: you have to play with the order of the x, y and z subscripts. I gave the geometric formula for a dot product above, so I should also give you the same for a cross product:
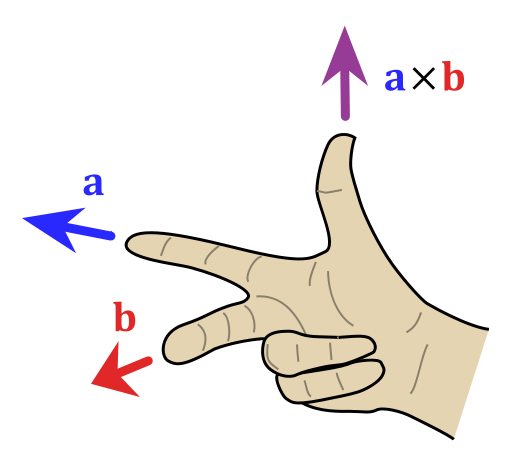
A×B = |A||B|sin(θ)n
In this formula, we once again have θ, the angle between A and B, but note that, this time around, it’s the sine, not the cosine, that pops up when calculating the magnitude of this vector. In addition, we have n at the end: n is a unit vector at right angles to both A and B. It’s what makes the cross product a vector. Indeed, as you can see, multiplying by n will not alter the magnitude (|A||B|sinθ) of this product, but it gives the whole thing a direction, so we get a new vector indeed. Of course, we have two unit vectors at right angles to A and B, and so we need a rule to choose one of these: the direction of the n vector we want is given by that right-hand rule which we encountered a couple of times already.
Again, it’s two symbols but one operator really, and we also have a special name (and notation) for it:
∇×h = curl h = the curl of h
The curl is, just like the divergence, a so-called vector operator but, as mentioned above, that’s just because it involves the del operator. Just note that it acts on a vector and that its result is a vector too. What’s the geometric interpretation of the curl? Well… It’s a bit hard to describe that but let’s try. The curl describes the ‘rotation’ or ‘circulation’ of a vector field:
- The direction of the curl is the axis of rotation, as determined by the right-hand rule.
- The magnitude of the curl is the magnitude of rotation.
I know. This is pretty abstract, and I’ll probably have to come back to it in another post. Let’s first ask some basic question: should we associate some unit with the curl? In fact, when you google, you’ll find lots of units used in electromagnetic theory (like the weber, for example), but nothing for circulation. I am not sure why, because if flux is related to some density, the idea of curl (or circulation) is pretty much the same. It’s just that it isn’t used much in actual engineering problems, and surely not those you may have encountered in your high school physics course!
In any case, just note we defined three new operators in this ‘introduction’ to vector calculus:
- ∇T = grad T = a vector
- ∇·h = div h = a scalar
- ∇×h = curl h = a vector
That’s all. It’s all we need to understand Maxwell’s famous equations:
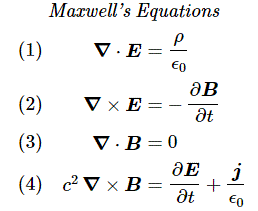
Huh? Hmm… You’re right: understanding the symbols, to some extent, doesn’t mean we ‘understand’ these equations. What does it mean to ‘understand’ an equation? Let me quote Feynman on that: “What it means really to understand an equation—that is, in more than a strictly mathematical sense—was described by Dirac. He said: “I understand what an equation means if I have a way of figuring out the characteristics of its solution without actually solving it.” So if we have a way of knowing what should happen in given circumstances without actually solving the equations, then we “understand” the equations, as applied to these circumstances.”
We’re surely not there yet. In fact, I doubt we’ll ever reach Dirac’s understanding of Maxwell’s equations. But let’s do what we can.
In order to ‘understand’ the equations above in a more ‘physical’ way, let’s explore the concepts of divergence and curl somewhat more. We said the divergence was related to the ‘flux’ of a vector field, and the curl was related to its ‘circulation’. In my previous post, I had already illustrated those two concepts copying the following diagrams from Feynman’s Lectures:
flux = (average normal component)·(surface area)
So that’s the flux (through a non-closed surface).
To illustrate the concept of circulation, we have not one but three diagrams, shown below. Diagram (a) gives us the vector field, such as the velocity field in a liquid. In diagram (b), we imagine a tube (of uniform cross section) that follows some arbitrary closed curve. Finally, in diagram (c), we imagine we’d suddenly freeze the liquid everywhere except inside the tube. Then the liquid in the tube would circulate as shown in (c), and so that’s the concept of circulation.
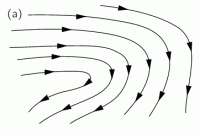

We have a similar formula as for the flux:
circulation = (the average tangential component)·(the distance around)
In both formulas (flux and circulation), we have a product of two scalars: (i) the average normal component and the average tangential component (for the flux and circulation respectively) and (ii) the surface area and the distance around (again, for the flux and circulation respectively). So we get a scalar as a result. Does that make sense? When we related the concept of flux to the divergence of a vector field, we said that the flux would have a positive value if the region is a source, and a negative value if the region is a sink. So we have a number here (otherwise we wouldn’t be talking ‘positive’ or ‘negative’ values). So that’s OK. But are we talking about the same number? Yes. I’ll show they are the same in a few minutes.
But what about circulation? When we related the concept of circulation of the curl of a vector field, we introduced a vector cross product, so that yields a vector, not a scalar. So what’s the relation between that vector and the number we get when multiplying the ‘average tangential component’ and the ‘distance around’. The answer requires some more mathematical analysis, and I’ll give you what you need in a minute. Let me first make a remark about conventions here.
From what I write above, you see that we use a plus or minus sign for the flux to indicate the direction of flow: the flux has a positive value if the region is a source, and a negative value if the region is a sink. Now, why don’t we do the same for circulation? We said the curl is a vector, and its direction is the axis of rotation as determined by the right-hand rule. Why do we need a vector here? Why can’t we have a scalar taking on positive or negative values, just like we do for the flux?
The intuitive answer to this question (i.e. the ‘non-mathematical’ or ‘physical’ explanation, I’d say) is the following. Although we can calculate the flux through a non-closed surface, from a mathematical point of view, flux is effectively being defined by referring to the infinitesimal volume around some point and, therefore, we can easily, and unambiguously, determine whether we’re inside or outside of that volume. Therefore, the concepts of positive and negative values make sense, as we can define them referring to some unique reference point, which is either inside or outside of the region.
When talking circulation, however, we’re talking about some curve in space. Now it’s not so easy to find some unique reference point. We may say that we are looking at some curve from some point ‘in front of’ that curve, but some other person whose position, from our point of view, would be ‘behind’ the curve, would not agree with our definition of ‘in front of’: in fact, his definition would be exactly the opposite of ours. In short, because of the geometry of the situation involved, our convention in regard to the ‘sign’ of circulation (positive or negative) becomes somewhat more complicated. It’s no longer a simple matter of ‘inward’ or ‘outward’ flow: we need something like a ‘right-hand rule’ indeed. [We could, of course, also adopt a left-hand rule but, by now, you know that, in physics, there’s not much use for a left hand. :-)]
That also ‘explains’ why the vector cross product is non-commutative: A×B ≠ B×A. To be fully precise, A×B and B×A have the same magnitude but opposite direction: A×B = |A||B|sin(θ)n = –|A||B|sin(θ)(–n) = –(B×A) = –B×A. The dot product, on the other hand, is fully commutative: A·B = B·A.
In fact, the concept of circulation is very much related to the concept of angular momentum which, as you’ll remember from a previous post, also involves a vector cross product.
[…]
I’ve confused you too much already. The only way out is the full mathematical treatment. So let’s go for that.
Flux
Some of the confusion as to what flux actually means in electromagnetism is probably caused by the fact that the illustration above is not a closed surface and, from my previous post, you should remember that Maxwell’s first and third equation define the flux of E and B through closed surfaces. It’s not that the formula above for the flux through a non-closed surface is wrong: it’s just that, in electromagnetism, we usually talk about the flux through a closed surface.
A closed surface has no boundary. In contrast, the surface area above does have a clear boundary and, hence, it’s not a closed surface. A sphere is an example of a closed surface. A cube is an example as well. In fact, an infinitesimally small cube is what’s used to prove a very convenient theorem, referred to as Gauss’ Theorem. We will not prove it here, but just try to make sure you ‘understand’ what it says.
Suppose we have some vector field C and that we have some closed surface S – a sphere, for example, but it may also be some very irregular volume. Its shape doesn’t matter: the only requirement is that it’s defined by a closed surface. Let’s then denote the volume that’s enclosed by this surface by V. Now, the flux through some (infinitesimal) surface element da will, effectively, be given by that formula above:
flux = (average normal component)·(surface area)
What’s the average normal component in this case? It’s given by that ΔJ/Δa2 = (ΔJ/Δa1)cosθ = h·n formula, except that we just need to substitute h for C here, so we have C·n instead of h·n. To get the flux through the closed surface S, we just need to add all the contributions. Adding those contributions amounts to taking the following surface integral:
Now, I talked about Gauss’ Theorem above, and I said I would not prove it, but this is what Gauss’ Theorem says:
Huh? Don’t panic. Just try to ‘read’ what’s written here. From all that I’ve said so far, you should ‘understand’ the surface integral on the left-hand side. So that should be OK. Let’s now look at the right-hand side. The right-hand side uses the divergence operator which I introduced above: ∇·(vector). In this case, ∇·C. That’s a scalar, as we know, and it represents the outward flux from an infinitesimally small cube inside the surface indeed. The volume integral on the right-hand side adds all of the fluxes out of each part (think of it as zillions of infinitesimally small cubes) of the volume V that is enclosed by the (closed) surface S. So that’s what Gauss’ Theorem is all about. In words, we can state Gauss’ Theorem as follows:
Gauss’ Theorem: The (surface) integral of the normal component of a vector (field) over a closed surface is the (volume) integral of the divergence of the vector over the volume enclosed by the surface.
Again, I said I would not prove Gauss’ Theorem, but its proof is actually quite intuitive: to calculate the flux out of a large volume, we can ‘cut it up’ in smaller volumes, and then calculate the flux out of these volumes. If we add it up, we’ll get the total flux. In any case, I’ll refer you to Feynman in case you’d want to see how it goes exactly. So far, I did what I promised to do, and that’s to relate the formula for flux (i.e. that (average normal component)·(surface area) formula) to the divergence operator. Let’s now do the same for the curl.
Curl
For non-native English speakers (like me), it’s always good to have a look at the common-sense definition of ‘curl’: as a verb (to curl), it means ‘to form or cause to form into a curved or spiral shape’. As a noun (e.g. a curl of hair), it means ‘something having a spiral or inwardly curved form’. It’s clear that, while not the same, we can indeed relate this common-sense definition to the concept of circulation that we introduced above:
circulation = (the average tangential component)·(the distance around)
So that’s the (scalar) product we already mentioned above. How do we relate it to that curl operator?
Patience, please ! The illustration below shows what we actually have to do to calculate the circulation around some loop Γ: we take an infinite number of vector dot products C·ds. Take a careful look at the notation here: I use bold-face for s and, hence, ds is some little vector indeed. Going to the limit, ds becomes a differential indeed. The fact that we’re talking a vector dot product here ensures that only the tangential component of C ‘enters the equation’, so to speak. I’ll come back to that in a moment. Just have a good look at the illustration first.
Such infinite sum of vector dot products C·ds is, once again, an integral. It’s another ‘special’ integral, in fact. To be precise, it’s a line integral. Moreover, it’s not just any line integral: we have to go all around the (closed) loop to take it. We cannot stop somewhere halfway. That’s why Feynman writes it with a little loop (ο) through the integral sign (∫):
Note the subtle difference between the two products in the integrands of the integrals above: Ctds versus C·ds. The first product is just a product of two scalars, while the second is a dot product of two vectors. Just check it out using the definition of a dot product (A·B = |A||B|cosθ) and substitute A and B by C and ds respectively, noting that the tangential component Ct equals C times cosθ indeed.
Now, once again, we want to relate this integral with that dot product inside to one of those vector operators we introduced above. In this case, we’ll relate the circulation with the curl operator. The analysis involves infinitesimal squares (as opposed to those infinitesimal cubes we introduced above), and the result is what is referred to as Stokes’ Theorem. I’ll just write it down:
Again, the integral on the left was explained above: it’s a line integral taking around the full loop Γ. As for the integral on the right-hand side, that’s a surface integral once again but, instead of a div operator, we have the curl operator inside and, moreover, the integrand is the normal component of the curl only. Now, remembering that we can always find the normal component of a vector (i.e. the component that’s normal to the surface) by taking the dot product of that vector and the unit normal vector (n), we can write Stokes’s Theorem also as:
That doesn’t look any ‘nicer’, but it’s the form in which you’ll usually see it. Once again, I will not give you any formal proof of this. Indeed, if you’d want to see how it goes, I’ll just refer you to Feynman’s Lectures. However, the philosophy behind is the same. The first step is to prove that we can break up the surface bounded by the loop Γ into a number of smaller areas, and that the circulation around Γ will be equal to the sum of the circulations around the little loops. The idea is illustrated below:
Of course, we then go to the limit and cut up the surface into an infinite number of infinitesimally small squares. The next step in the proof then shows that the circulation of C around an infinitesimal square is, indeed, (i) the component of the curl of C normal to the surface enclosed by that square multiplied by (ii) the area of that (infinitesimal) square. The diagram and formula below do not give you the proof but just illustrate the idea:
OK, you’ll say, so what? Well… Nothing much. I think you have enough to digest as for now. It probably looks very daunting, but so that’s all we need to know – for the moment that is – to arrive at a better ‘physical’ understanding of Maxwell’s famous equations. I’ll come back to them in my next post. Before proceeding to the summary of this whole post, let me just write down Stokes’ Theorem in words:
Stokes’ Theorem: The line integral of the tangential component of a vector (field) around a closed loop is equal to the surface integral of the normal component of the curl of that vector over any surface which is bounded by the loop.
Summary
We’ve defined three so-called vector operators, which we’ll use very often in physics:
- ∇T = grad T = a vector
- ∇·h = div h = a scalar
- ∇×h = curl h = a vector
Moreover, we also explained three important theorems, which we’ll use as least as much:
[1] The First Theorem:
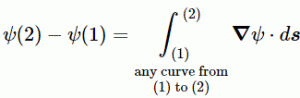
[2] Gauss Theorem:
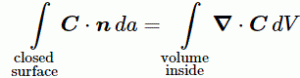
[3] Stokes Theorem:
As said, we’ll come back to them in my next post. As for now, just try to familiarize yourself with these div and curl operators. Try to ‘understand’ them as good as you can. Don’t look at them as just some weird mathematical definition: try to understand them in a ‘physical’ way, i.e. in a ‘completely unmathematical, imprecise, and inexact way’, remembering that’s what it takes to understand to truly understand physics. 🙂
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 17, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/
Some content on this page was disabled on June 20, 2020 as a result of a DMCA takedown notice from Michael A. Gottlieb, Rudolf Pfeiffer, and The California Institute of Technology. You can learn more about the DMCA here:
https://wordpress.com/support/copyright-and-the-dmca/








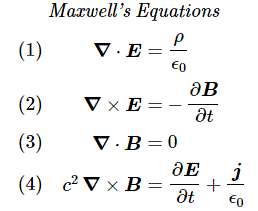




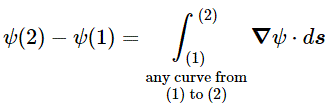

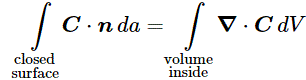



















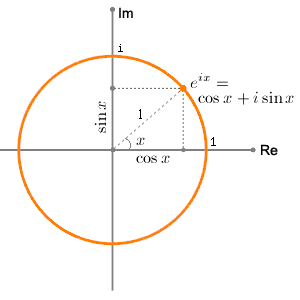
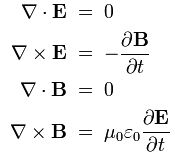
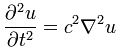
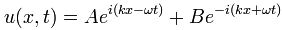
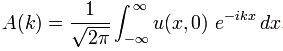
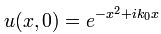
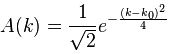
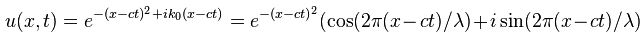
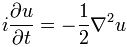

 Now if we plug that in the equation above, we get our time-dependent Schrödinger equation:
Now if we plug that in the equation above, we get our time-dependent Schrödinger equation: